

Test Automation with SWAG [Testμ 2023]
LambdaTest
Posted On: August 24, 2023
![]() 6317 Views
6317 Views
![]() 17 Min Read
17 Min Read
Have you ever wondered how we can fuel automation frameworks with unlimited test data? Multiple solutions like traditional, conventional & new emerging tools are available in the market to follow a test data-driven approach, one widely used to document all input values in a storage file like (CSV, YAML, JSON, etc.). Another available solution is using the utility of the database, which also resolves multiple issues & fulfills requirements like automation scripting with dynamic variables.
But before diving into the session, let’s understand about SWAG. It is Equinox’s in-house test data service. Beyond being just data delivery, SWAG tackles more complex issues. The upcoming dialogue with Garvit Chandna will dive deep into the creation, implementation, and broader applications of SWAG. Further, he will share innovative strategies to supercharge your automation frameworks with limitless test data, going beyond the boundaries of conventional approaches.
About the Speaker
With 14 years of experience handling globally distributed automation and manual test engineering teams, Garvit Chandna possesses a deep interest and expertise in management and architecting complex automation frameworks. Currently, he is working with Equinox as the Senior Manager, SDET.
If you couldn’t catch all the sessions live, don’t worry! You can access the recordings at your convenience by visiting the LambdaTest YouTube Channel.
Evolution of Test Automation at Equinox
Garvit began the session by discussing the automation landscape at Equinox. He discussed their progress from manual processes in 2011 to introducing their ‘Swagger APIs’ in 2023.
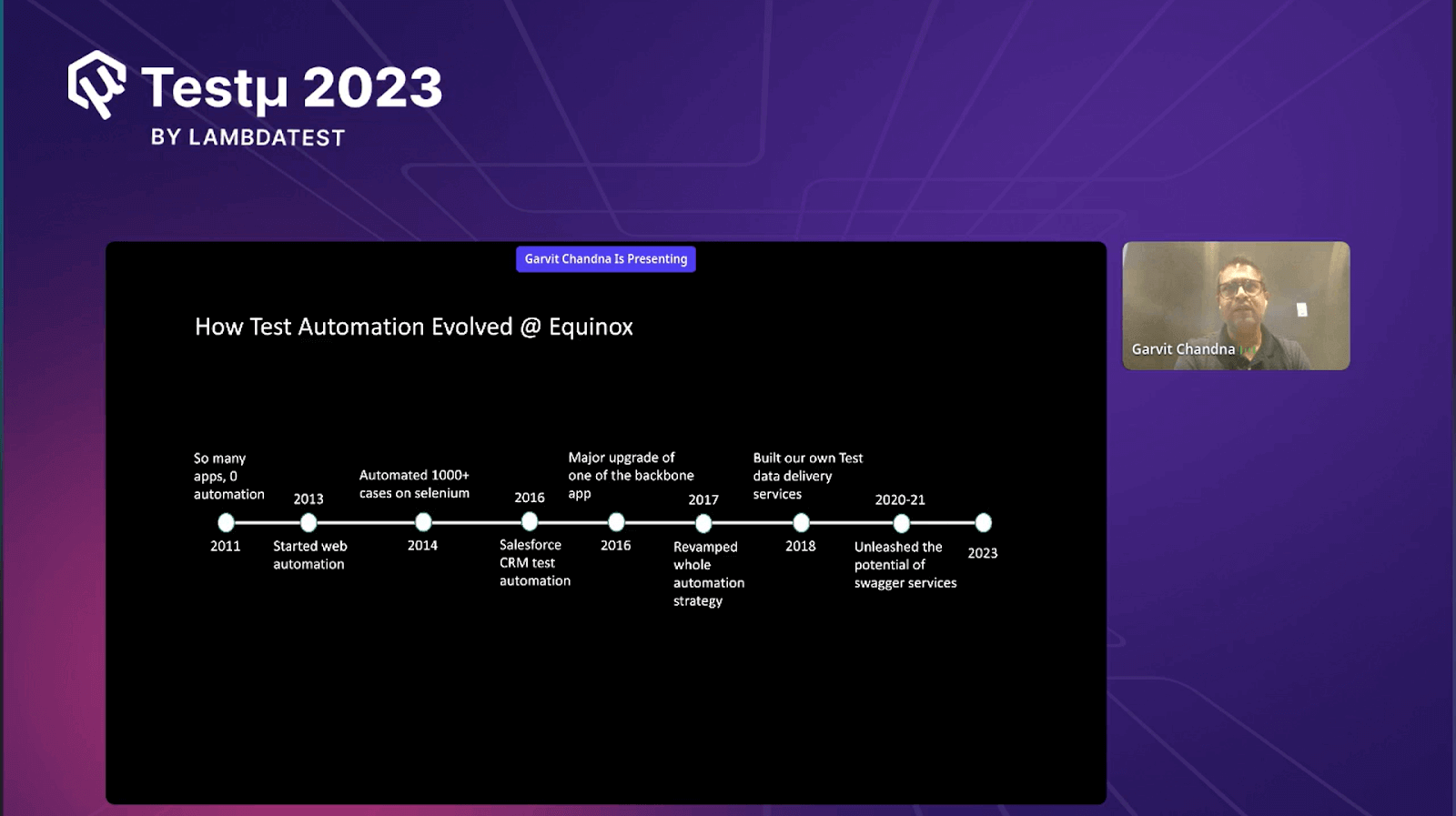
- Beginning in 2011: In 2011, test automation was virtually nonexistent within Equinox. There was no automation culture or processes in place across the organization.
- Progress in 2013: Around 2013, Equinox took its first steps into web automation. They initiated automation efforts and successfully automated over a thousand test cases using Selenium.
- Advancements in 2014: In the subsequent year, 2014, the focus remained on web automation, further refining their practices and proficiency in using Selenium.
- Major Changes in 2016: By 2016, Equinox had undergone a significant transformation by incorporating more complex applications into its automation strategy. They also introduced Salesforce automation using Selenium.
- Turning Point in 2016: Equinox encountered a pivotal moment in the same year due to a substantial upgrade in one of its core systems. This shift prompted a re-evaluation of their automation approach, particularly regarding test data delivery.
- API-First Approach: In response to the challenges posed by the system upgrade, Equinox adopted an API-driven automation strategy. APIs were chosen for their stability compared to the UI. They began to prioritize automation on the API layer, enhancing the reliability of their testing.
- Test Data Delivery Service in 2016: The most significant change came in 2016 with the creation of a dedicated test data delivery service known as “Hypergate APIs.” This service, developed using Java Spring Boot, interacted with various databases, catering to Equinox’s diverse data sources, including SQL Server, Documentdb, Postgres, Redshift, and Redis.
- Need for Centralized Solution: Equinox recognized the need for a centralized solution to seamlessly integrate data from these diverse sources and serve it to their automation scripts.
- Security Measures: Between 2020 and 2021, Equinox’s journey continued. As they fine-tuned their services, they implemented security measures. An API Gateway was added to facilitate external access while maintaining control and security over their ‘Swagger’ APIs.
Types of Automation Frameworks
Before moving ahead what his team did with the Swagger APIs, Garvit highlighted the various types of automation frameworks. According to him, these 5 are the most important automation frameworks:

- Linear Automation Framework: Garvit introduced the concept of linear automation, where actions performed by a user are recorded and then replayed as scripts. This method, while initially easy, lacks stability and flexibility, making it better suited for simpler tasks rather than complex scenarios.
- Data-Driven Framework: Moving on, he highlighted the data-driven framework. Here, the focus is on isolating test data from script logic. Testers store data externally, allowing for greater script reusability and adaptability across test cases.
- Modular-Based Testing Framework: Transitioning to the modular framework, Garvit explained how applications are divided into distinct units or segments. For each of these, individual test scripts are crafted, promoting targeted testing that’s easier to manage and maintain.
- Library Architecture Testing Framework: The library architecture framework was next. Similar to the modular approach, it identifies common functions within scripts. The key distinction is that the application is categorized based on shared goals, leading to even higher levels of script reusability and streamlined testing.
- Keyword-Driven Framework: Lastly, Garvit introduced the keyword-driven framework. In this structure, functions are laid out in a table, with step-by-step instructions outlining each test action. This approach offers a methodical way to construct and execute tests, ensuring clear and systematic testing processes.
Traditional Approach of Providing Test Data
Among the common automation frameworks, a common challenge exists, and that’s data. Data has the potential to disrupt any automation script. Lack of test data or incorrect data can cause failures. Around 70 to 75%—tend to break due to data-related issues. Therefore, even with varying frameworks, data management remains a crucial concern in effective test automation.

To solve this problem, Garvit highlighted the traditional approaches to providing test data:
- Supplying Hard-Coded Test Data: One common traditional method is embedding test data directly within the script. However, this practice lacks stability and reusability. It’s a beginner’s approach that isn’t sustainable, as more experienced professionals would agree.
- Generating Test Data Based on Scenarios: Another approach involves generating test data tailored to specific scenarios or requirements. This often means storing the test data in Excel Sheets or databases. However, this approach can become complex and not entirely maintainable.
- Writing SQL Queries Within Code: Writing SQL queries directly within the code is a prevalent traditional approach. While effective for obtaining dynamic test data, it’s not always manageable or scalable. It’s a useful approach but can lead to code becoming cumbersome.
- Using Excel for Data-Driven Testing Framework: A common practice is using Excel sheets to provide test data for data-driven testing frameworks. This involves inputting test data into Excel files and then having the automation framework read the data from those files.
Major Test Data Challenges
When it comes to using the traditional approach of providing test data, Garvit discussed the top 5 challenges that could be encountered while following this approach:

- Low Variety of Test Data: If SQL queries aren’t used, the range of test data available for automation scripts tends to be limited.
- Manual Data Creation and Maintenance: Without SQL queries, test data creation and maintenance become manual tasks, leading to increased effort.
- Complexity in Data Handling: Different teams and frameworks requiring distinct data further complicate managing and sharing data resources.
- Complexity in System Management: Managing multiple systems with diverse data sources becomes intricate, with the risk of inconsistencies.
- Data Protection and Security Concerns: Storing database credentials within code for SQL queries is not secure, exposing data to potential vulnerabilities.
Parameters Equinox Considered while Building their Solution
Garvit delved into their journey of building their in-house solution. These considerations strongly influenced their approach to developing their solution. Garvit emphasized their commitment to addressing these concerns and crafting a robust, versatile, and secure solution to enhance their testing efficiency and effectiveness.

- Eliminating Hardcoding: Garvit mentioned that his team aimed to eliminate hardcoded values from their test scripts. While hardcoding might work initially, it becomes problematic in the long run when maintenance is required. Hardcoding can lead to quality issues and greater losses over time.
- Variety of Test Data: They sought to avoid supplying the same test data repeatedly to their scripts. By introducing variety in test data, they aimed to uncover a wider range of issues within the code, increasing the effectiveness of their tests.
- Efficient Testing with Parallel Execution: Parallel execution of multiple frameworks and test cases can lead to a series of database calls. To ensure efficient testing, his team aimed to mitigate excessive database calls that could result from hard coding SQL queries within the code.
- Ease of Maintenance: While complete absence of maintenance is unrealistic, they focused on creating a solution that would be easy to maintain, reducing the associated costs and efforts.
- Data Security: With data security being a significant concern, especially in the post-Covid era, they aimed to ensure the security of data used in their test scripts.
- Data Reusability Across Platforms: Equinox operates with diverse data sources like SQL, Redshift, Redis, Postgres, and Documentdb. Rather than creating separate utilities for each data source within every framework or application, they aimed to develop a centralized solution to which all frameworks could connect.
High-Level Architecture of the Solution – SWAG
Garvit provided a comprehensive overview of the high-level architecture they developed. On the left side, various applications are under test, including mobile apps, admin apps, and websites. These applications are tested using various automation tools such as Selenium, Appium, Rest Assured, and Wsl2, each with its dedicated setup.
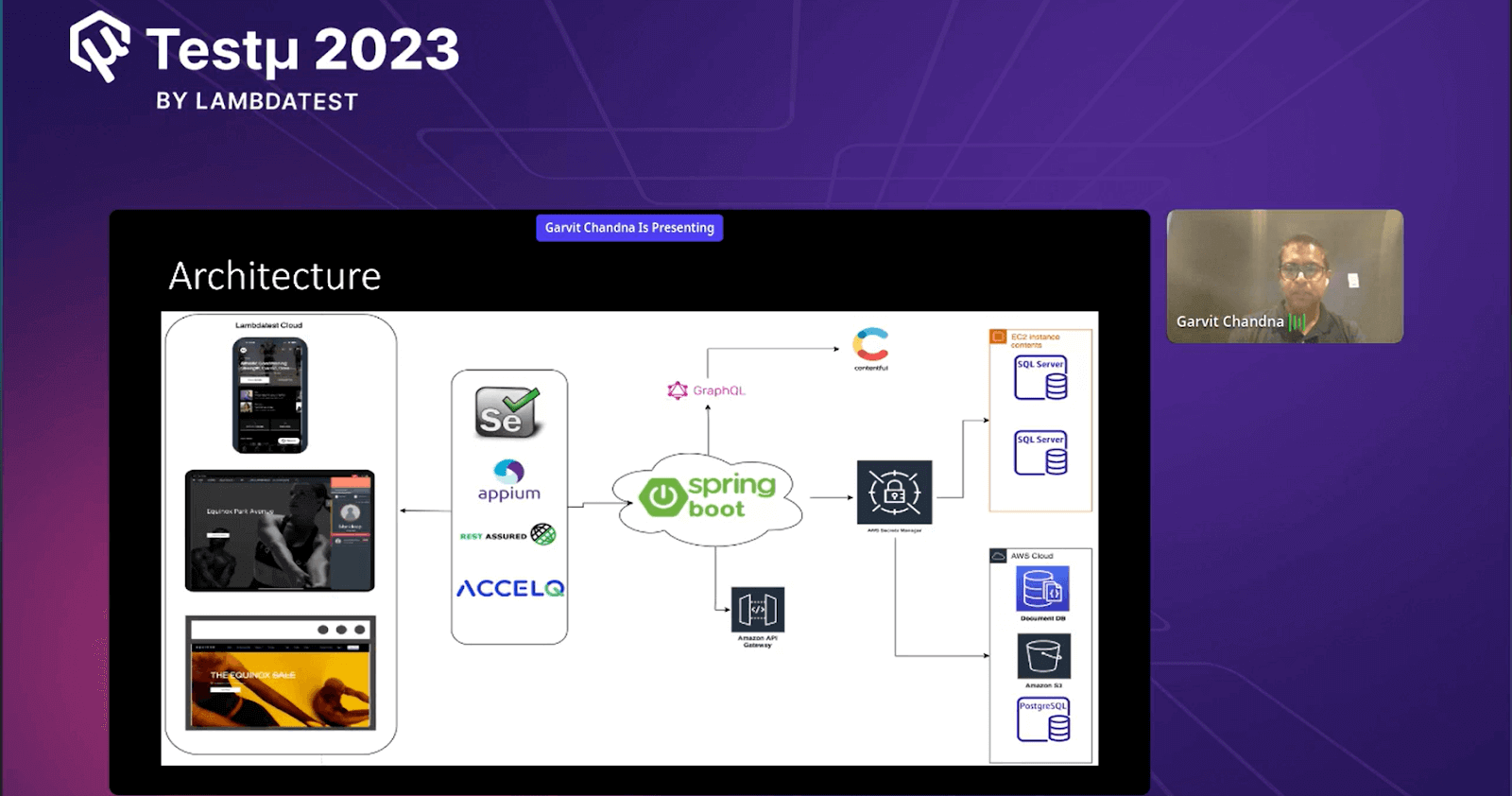
Key to their architecture was the Spring Boot Cloud, situated on the right side. This core component receives instructions from automation frameworks through Swagger queries. Once these instructions are received, the Spring Boot Cloud interfaces with various databases – SQL Server, Documentdb, Amazon S3, Postgres, Redshift, and Redis – to retrieve the necessary data. This data is converted into JSON format, effectively providing a consolidated data pool from multiple sources.
An addition to this architecture is the Contentful utility, which enables the extraction of content from Contentful, a vital content delivery system used primarily for content-driven websites. This utility employs graph query language to acquire content data and transfer it to automation scripts.
To ensure security and controlled access, an API gateway was introduced. This gateway permits external vendors to access specific exposed APIs securely, allowing them to retrieve test data located behind a VPN wall. This minimizes data exchange complexity and enhances data security.
Furthermore, Garvit emphasized their commitment to data security. Sensitive credentials are stored within the Secret Manager, avoiding their direct inclusion in code. This ensures the confidentiality of data while enabling controlled access as needed.
Garvit highlighted that it addresses the challenges previously encountered and optimizes scalability and maintainability. Changes and updates can be made centrally within the Spring Boot Cloud, avoiding the need for manual updates across various frameworks and applications. This holistic architecture reflects their dedication to creating an efficient, secure, and easily maintainable solution that streamlines the testing process across diverse platforms and data sources.
The SpringBoot Architecture
According to Garvit, they use Swagger, a tool that helps visualize APIs. It’s like a tool called Postman that developers use to talk to APIs. With Swagger, they can describe their APIs and show sample ways to use them. This makes it easier to understand how things work in their system.
Garvit also talked about Docker, a special container that holds their services. It’s like a small, self-contained world for their programs. Using Docker helps them improve their services, and they can put these containers on Amazon’s EC2 system, which helps everything run smoothly and quickly.
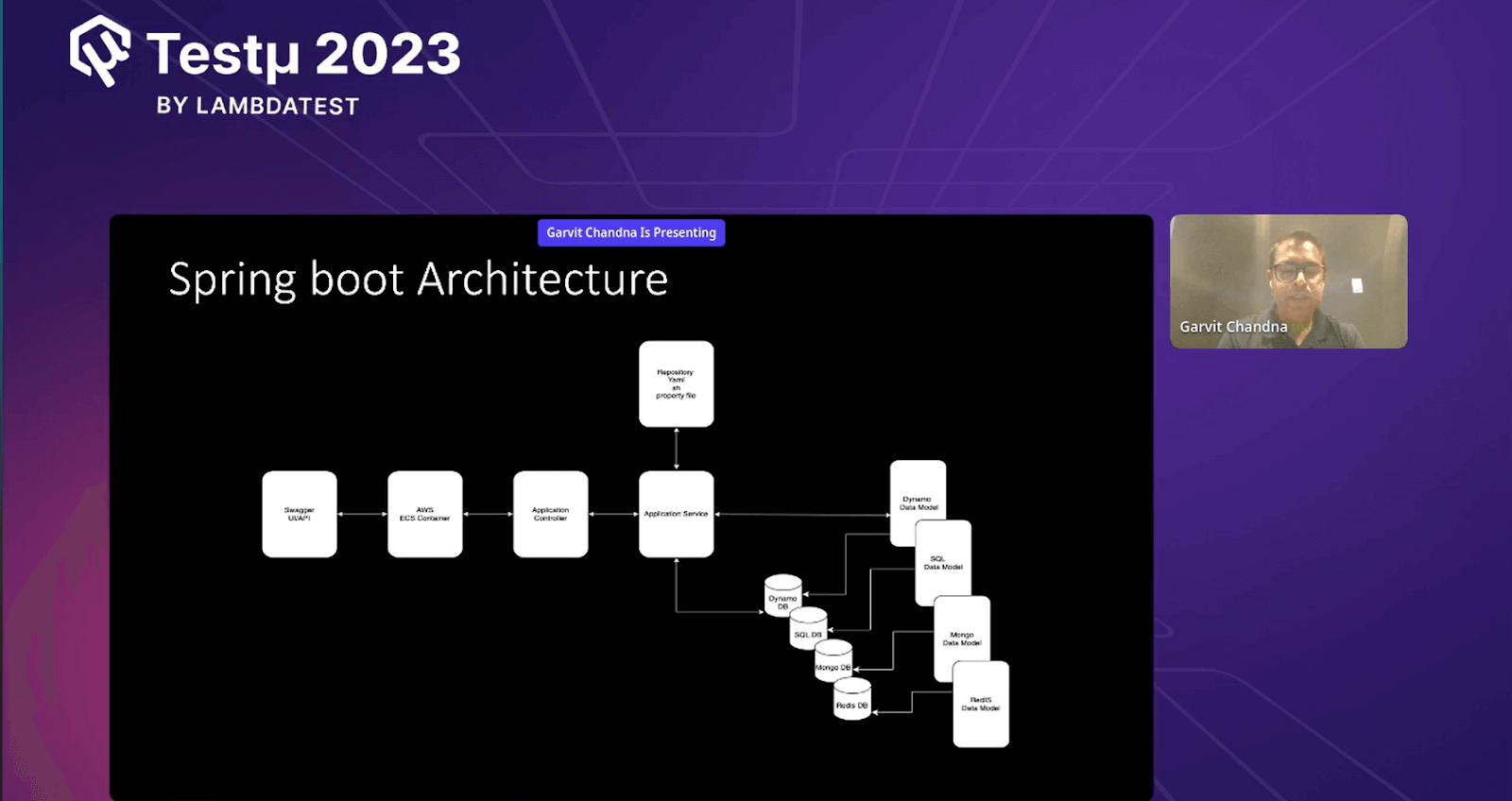
Now, let’s look at two important parts of their system. The first is the Application Controller. It takes care of requests, ensures the right things happen, and gives back the right answers. Garvit compared it to a traffic director, ensuring all the cars go where they should.
The second important part is the Application Service Layer. This is where the important stuff happens. It’s like the heart of their system. It knows how to give the right data to their tests. He said It’s like a super-smart helper ensuring everything works correctly.
Garvit also mentioned a special place to keep their instructions called a repository. It’s like a folder where they keep special files with instructions for the computer. These files tell the system how to talk to databases and get the right information.
Lastly, Garvit talked about the different types of data they use, like Dynamo, SQL, MongoDB, and Redis. They’ve made special tools to get data from these types, and these tools live inside their Spring Boot cloud. This cloud is like a big digital place where everything comes together.
Garvit pointed out that Spring Boot architecture uses tools like Swagger and Docker to organize and control how their system works. The Application Controller and Application Service Layer manage requests and data and have special ways to talk to different data sources. All of this happens in their Spring Boot cloud, where everything connects and works together.
How does the System Work?
Garvit gave a live demo of how their system works in an easy-to-understand way. He provided inputs like the number of records needed, the type of data required, and the desired status.
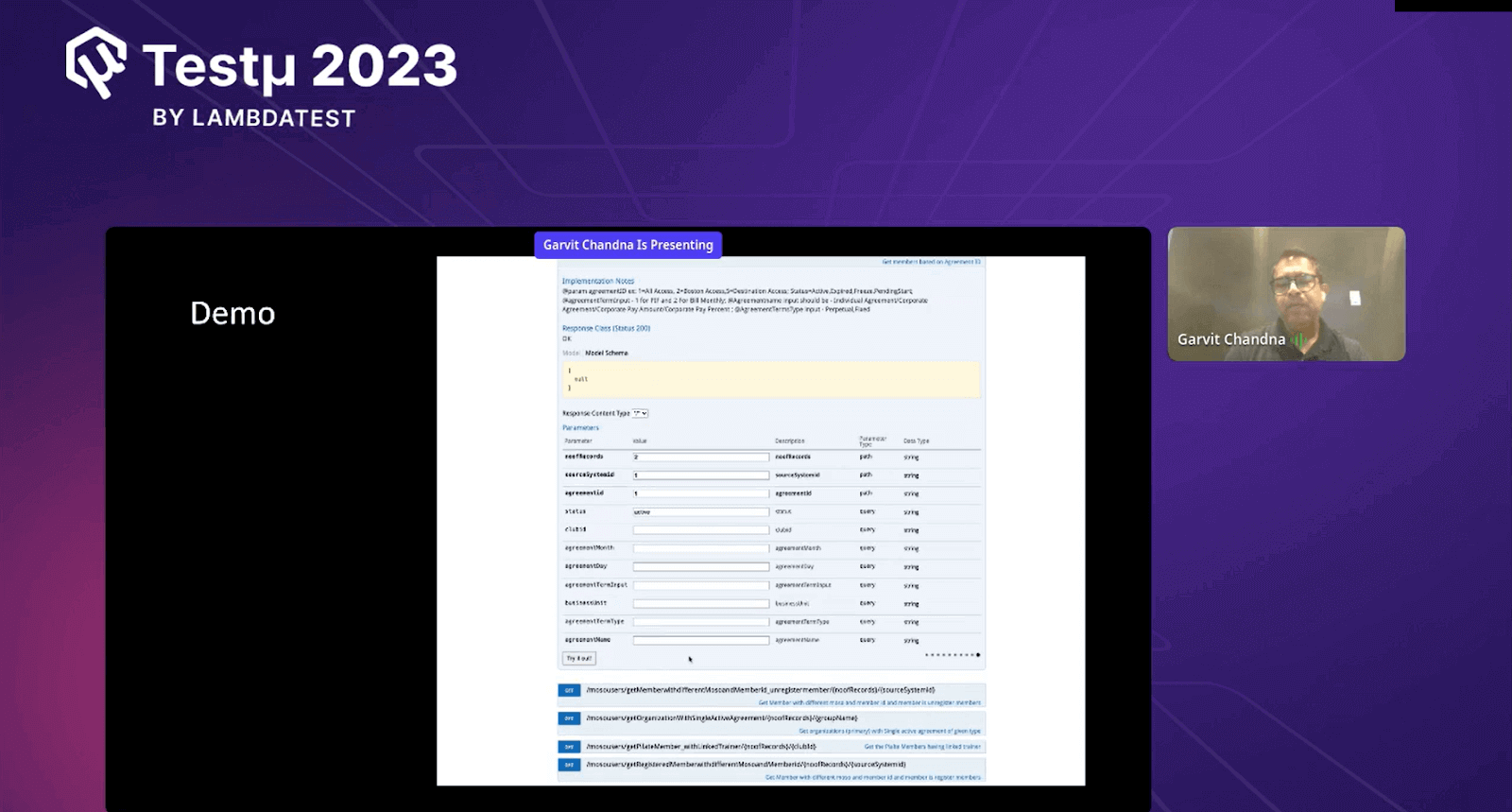
When he ran this query, the system did something interesting. It went to places where data is stored, like digital storage areas. It checked what data was there in one place, then went to another place and combined all that information. After doing this, the system gave the final results in JSON format. JSON is a way computers can share information easily.
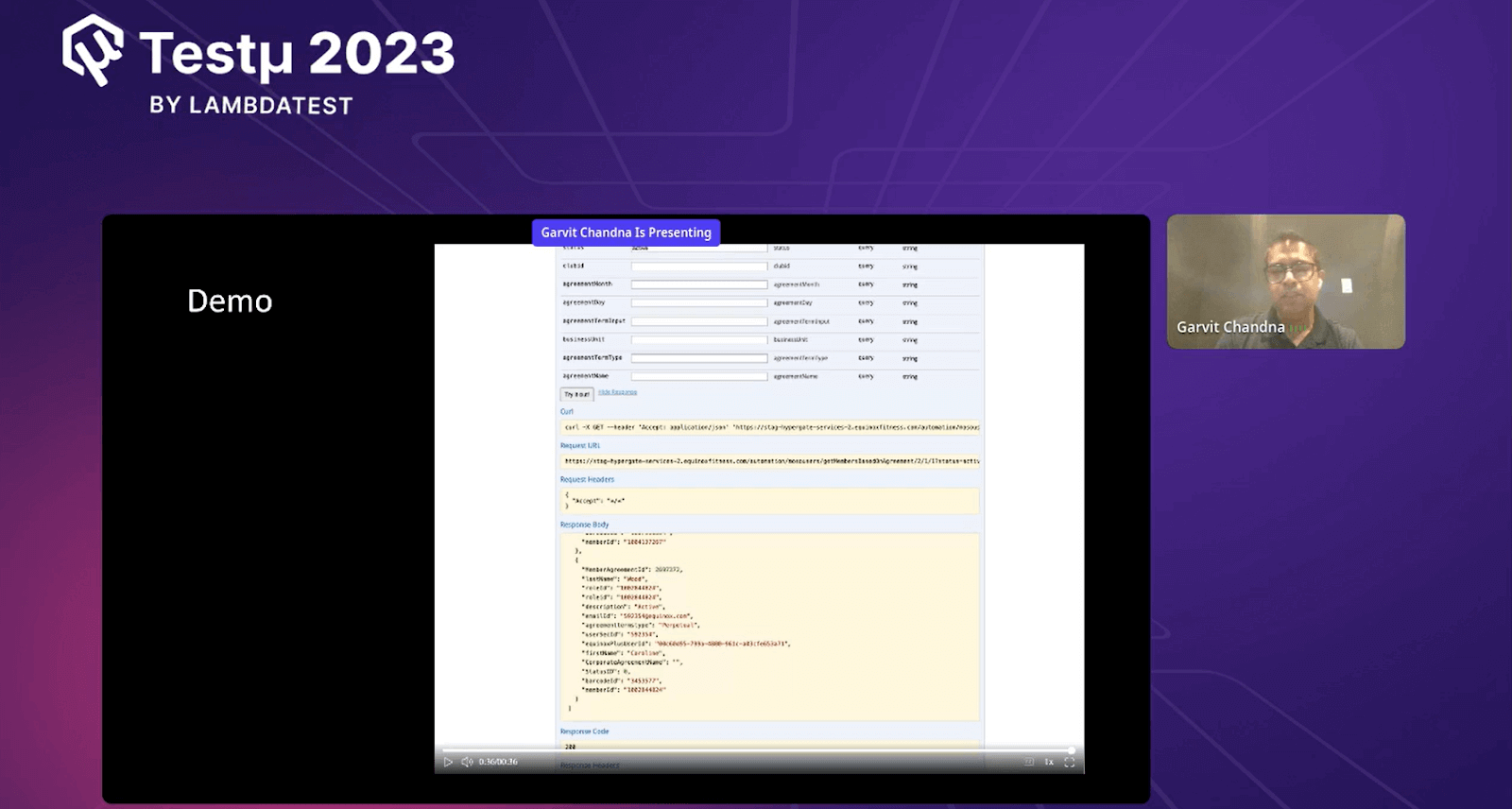
Garvit pointed out that instead of writing complicated instructions (SQL queries) separately for each part of their system, they made one special set of instructions (API) that all parts can use. This API lets them get the data they need from these different places without having to write a lot of different instructions each time. This makes things much easier and faster for everyone who uses the system.
Benefits of the Approach Equinox Adopted
While concluding the session, Garvit discussed the benefits of driving data-centric automation to optimize test execution and security.
- Pure Data-Driven Automation Testing: Garvit emphasized that their approach uses data to power their automation tests. They rely on different test data sets for various situations – different users, statuses, and more. Their swagger APIs provide this data. Once a data set is used, it won’t be repeated, adding a dynamic element to testing.
- Dynamic Test Data Generation: He described how their system could generate dynamic test data. Instead of creating test data from scratch, their APIs gather it from different sources. This creates test data tailored to the test’s specific needs, making their testing approach very adaptable.
- Data Reusability: Garvit highlighted the reusability of their APIs across various platforms and applications. Since they share data sources between different applications, they can use the same logic and APIs. This simplifies their testing process and makes it more efficient.
- No Data Setup: He mentioned that they’ve eliminated the need for manual data setup before running tests. Their system directly accesses the database, retrieves the required data, and provides it to their automation scripts. This removes the hassle of manually preparing test data.
- Faster Test Execution: In comparison to traditional methods, Garvit pointed out that their approach speeds up test execution. Instead of performing heavy data filtering within each framework’s code, their system does this work at the boot layer. This optimized process leads to faster test execution.
- Test Environment Independence: He explained that their solution allows them to adapt to different test environments easily. Instead of embedding test environment credentials in the code, they only need to adjust the swagger URL based on the environment. This flexibility ensures smoother testing across various environments.
- Data Security: While discussing unexpected benefits, Garvit mentioned data security. Their system ensures data security by fetching data from various sources while maintaining control and security measures. This was an unexpected advantage they realized during the development process.
- Accessible Test Data: One unique benefit he highlighted is that testers and developers can access test data independently. Instead of testers manually providing test data to developers upon request, the swagger APIs empower developers to retrieve the required test data themselves. This adds an element of independence to their testing process.
Time for Some Q&A
- The biggest challenge I see for dynamic data is:
- How do we provide usable test data for teams throughout the company, tens of development teams on one product?
- How do we provide the date for the whole test pyramid?
- Considering the need for parallel execution and scalability, what architecture choices should organizations make when designing their solutions?
- Can you please cover the best framework for mobile apps built on Flutter?
- What can be the popular strategy to speed up your UI automation tests?
- How does using a database utility for test data solve some of the challenges associated with traditional storage file methods?
Garvit: It’s not just about many teams on one product. We have different products that share similar data sources. For example, if there’s a customer-facing app and an admin tool, they might both use the same data. So, we created APIs to get data from these sources based on what each team needs. We invested time in building these APIs, and as we discover more needs, we add new APIs. These APIs help everyone in the company, including manual testers, get the data needed for any testing layer. We want everyone to be independent in getting the test data they require. I hope that explains it well.
Garvit: Parallel execution and scalability have different ways to approach them. For example, there’s a tool called HyperExecute from LambdaTest. You can divide your tests into smaller parts, use tools like HyperExecute, or even automate different app layers. For example, if your app has 100 things to test, maybe you automate 60 with one tool and 40 with another. You can run them together or split them into chunks and run them on platforms like LambdaTest Cloud for faster testing. It’s all about finding the right fit for your needs.
Garvit: Well, there are a few good options, like React Native, but we found that using Appium works well for us. It’s great for handling the UI stuff on mobile apps, even though UI automation can be tricky. The trick is to balance UI automation with API automation, which needs less upkeep and runs faster. And you can use any programming language you’re comfortable with. Some tools are moving towards low-code or no-code solutions, like Slack. So, choices are depending on your needs.
Garvit: A helpful way is to combine similar steps in your tests. If you have tests going from A to C and another from A to B to C, merging them can save time by avoiding repeated steps like logging in. Also, parallel execution is a powerful solution to speed things up.
Garvit: With traditional storage methods like files, you might hardcode specific data for testing, limiting the range of scenarios you explore. Using a database utility, you fetch data dynamically during runtime based on scenarios. This lets you uncover issues that might not arise with static test data. Opening the gate to varied data enhances your testing quality and ultimately delivers a higher-quality product.
Have you got more questions? Drop them on the LambdaTest Community.


Author’s Profile
LambdaTest
LambdaTest is a continuous quality testing cloud platform that helps developers and testers ship code faster.
Blogs: 179
Got Questions? Drop them on LambdaTest Community. Visit now










