

Guide To Scraping Dynamic Web Pages Using Selenium And C#
Himanshu Sheth
Posted On: March 29, 2021
![]() 219909 Views
219909 Views
![]() 17 Min Read
17 Min Read
Today’s websites are a lot different from yesteryears, where content on a majority of the websites is dynamic in nature. The content in dynamic pages varies from one user request to another based on the website visitor’s actions. Selenium, the popular test automation framework, is useful for testing dynamic web pages, but it can be extensively used for scraping dynamic web pages.

Though there are many tools for scraping static web pages, Selenium is one of the preferred tools for scraping large volumes of data (e.g., images, links, text, etc.) in a relatively short amount of time. We have chosen C# – the popular backend programming language for demonstrating dynamic web page scraping. As per Stack Overflow Survey 2020, C# holds the sixth position in the preferred programming languages category.
In this C# automation testing tutorial, you would be in a comfortable position for scraping dynamic web pages and extracting the meaningful information (from the page) that you intend to save for future use.
TABLE OF CONTENT
What is Web Scraping?
Web Scraping is a common technique primarily used for extracting information (or data) from websites. The HTML of the page from where relevant data has to be scraped is processed using the appropriate tools and stored in the database, excel sheet, etc. so that the data can be used for further analysis.
With larger size (or amounts) of data, scraping could add a significant amount of load on the server that hosts the website. As long as the scraping activity does not disrupt the website’s services, it is perfectly fine to scrap the said website.
Prominent Use Cases of Web Scraping
Why scrap websites when they might add load on the server that is hosting the website? Well, the answer lies in the umpteen number of scenarios where web scraping can be extremely useful. Web scraping can help unleash information related to customers, products, etc., which can be further used to make future decisions.
Owners of e-commerce websites can analyze data from different sources like their website, social media accounts, review websites, etc., for understanding users ’ buying patterns and improving their services. Product review scraping is a prominent use case that online businesses leverage for keeping a close watch on their competition.
Example – Dynamic web page scraping of the LambdaTest blog can give detailed insights on article views, author’s performance, and more. The data can be used for better content planning and getting the best out of the rockstar writers who contribute to our blog ☺.
Difference between Static & Dynamic Web Scraping
In static web pages, all the data on the page is available at the initial call to the site. You might not even need to maintain a connection to the server since all the information is now available locally. Hence, the HTML document can be downloaded, and data can be scraped using tools that let you scrap data from static pages.
On the other hand, dynamic content means that the data is generated from a request after the initial page load request. On dynamic pages, most of the functionality happens in responses to the actions performed by the user and the JavaScript code that is executed in the web browser.
HTTP agent is not suited for websites (or web applications) where there is a high level of dynamic interaction and interface automation. The Selenium C# library, which is widely used for automation testing of web applications, helps emulate human actions and render dynamic JavaScript code.
Scraping Dynamic Web Pages with Selenium C#
Due to Selenium’s capability in handling dynamic content generated using JavaScript, it is the preferred option for scraping dynamic web pages. Selenium is a popular automated testing framework used to validate applications across different browsers and operating systems.
Prerequisites for demonstrating web scraping with Selenium C#
We use Visual Studio for the implementation of test scenarios in C#. Here are the basic setup requirements for performing Selenium web scraping in C#
- Visual Studio IDE – For implementation, we use the Visual Studio (Community Edition), which can be downloaded from VS Community Download Page.
- Browser Driver – It automates browser interaction from Selenium C# code. You have to download the browser driver for Selenium in accordance with the browser on which Selenium web scraping is performed. Shown below are the locations for downloading browser drivers for Selenium:
| Browser | Download location |
| Opera | https://github.com/operasoftware/operachromiumdriver/releases |
| Firefox | https://github.com/mozilla/geckodriver/releases |
| Chrome | http://chromedriver.chromium.org/downloads |
| Internet Explorer | https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver |
| Microsoft Edge | https://blogs.windows.com/msedgedev/2015/07/23/bringing-automated-testing-to-microsoft-edge-through-webdriver/ |
Downloading and installing browser drivers is not required when dynamic web page scraping is done using a cloud-based Selenium Grid like LambdaTest. You can refer to our detailed Selenium WebDriver tutorial for a quick recap on Selenium WebDriver.
- C# Packages – We showcase Selenium web scraping using the Selenium WebDriver and NUnit framework. The NUnit project requires reference to the following libraries (or packages):
- Selenium.WebDriver
- NUnit
- NUnit3TestAdapter
- Microsoft.NET.Test.Sdk
These are the standard set of packages that are used for automated browser testing with NUnit and Selenium. No additional packages are required for scraping dynamic web pages with C# and Selenium. Check out our tutorial on NUnit test automation with Selenium C# for a quick recap on NUnit for automation testing.
Setting up the Selenium C# Project
- We create a new project of type ‘NUnit Test Project (.Net Core)’ in Visual Studio.
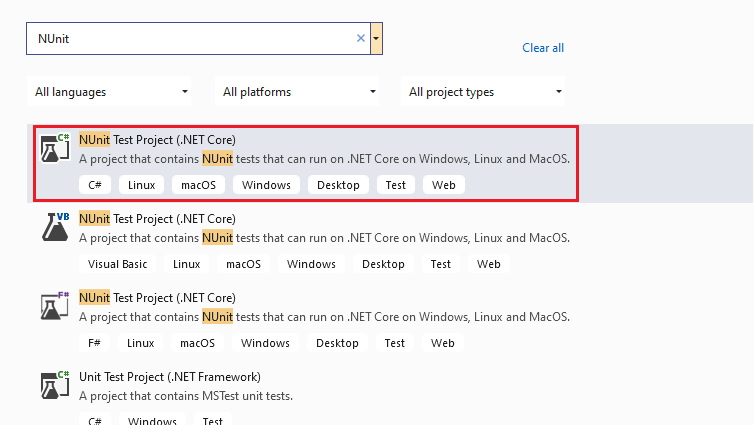
- Name the project as ‘WebScraping’ and press the ‘Create button.
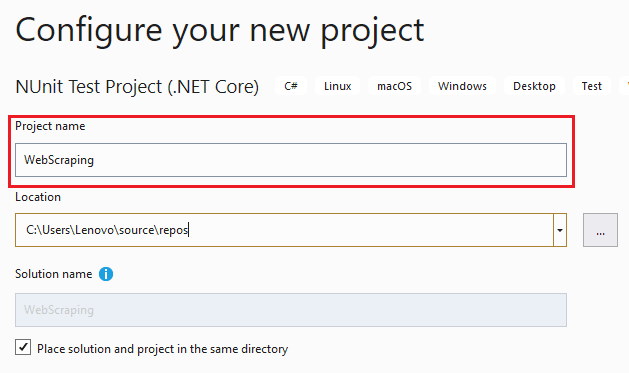
- Once you have created the project, install the packages mentioned above using the Package Manager (PM) console, which can be accessed through ‘Tools’ -> ‘NuGet Package Manager’ -> ‘Package Manager Console.’
- For installing the packages, run the following commands in the PM console:
12345Install-Package Selenium.WebDriverInstall-Package NUnitInstall-Package NUnit3TestAdapterInstall-Package Microsoft.NET.Test.SdkInstall-Package Selenium.WebDriver.ChromeDriver - Run the Get-Package command on the PM console to confirm whether the above packages are installed successfully:
123456789PM> get-packageId Versions-- --------Selenium.WebDriver {3.141.0}NUnit {3.12.0}NUnit3TestAdapter {3.16.1}Microsoft.NET.Test.Sdk {16.5.0}Selenium.WebDriver.ChromeDriver {88.0.4324}
Now that the necessary packages are installed for the Selenium C# NUnit project, we proceed with the addition of NUnit test scenarios that demonstrate scraping dynamic web pages with Selenium.
Let’s begin writing a scraper for scraping the following websites:
Web Scraping LambdaTest YouTube Channel
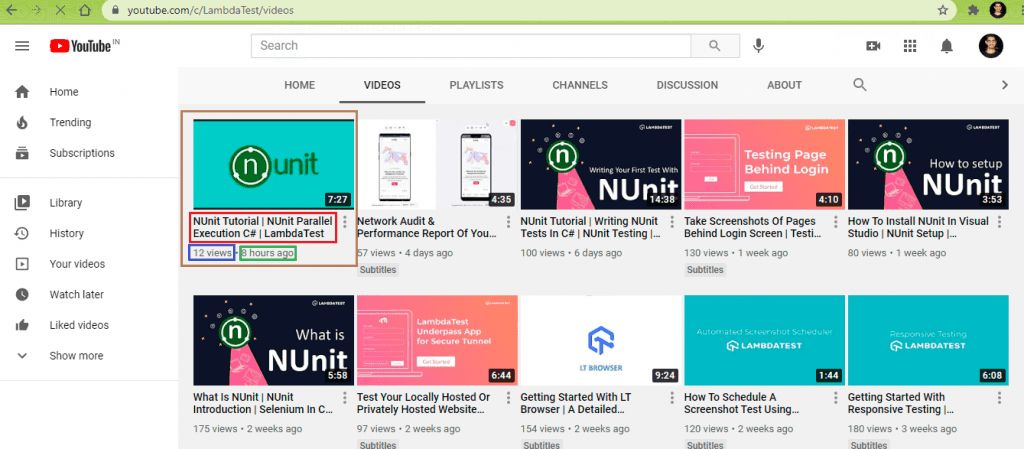
In this demonstration, we scrap the following data from the LambdaTest YouTube channel:
- Video Title
- Number of video views
- Time of upload
When writing this article, the LambdaTest YouTube channel had 79 videos, and we would scrape the requisite information from all the videos on the channel. Here is the Selenium web scraping test scenario that will be executed on Chrome (on Windows 10). The test is run on a cloud-based Selenium Grid provided by LambdaTest.
- Go to https://www.youtube.com/c/LambdaTest/videos.
- Scroll till the end of the page so that all the videos are available on the page.
- Scrap the video title, views, and upload details.
- Print the scraped information on the terminal.
Implementation
Code Walkthrough
Now let’s decipher the code where we scraped vital information from the LambdaTest YouTube Channel.
Step 1 – Import the packages (or namespaces).
First, we import the namespaces or packages for Selenium Remote WebDriver, NUnit framework, and more.
|
1 2 3 4 5 6 7 |
using NUnit.Framework; using OpenQA.Selenium; using OpenQA.Selenium.Chrome; using OpenQA.Selenium.Remote; using OpenQA.Selenium.Support.UI; ...................................... ...................................... |
Step 2 – Set the desired browser capabilities.
In the [SetUp] annotation, we implement a method that sets the desired browser capabilities that are created using the LambdaTest capabilities generator.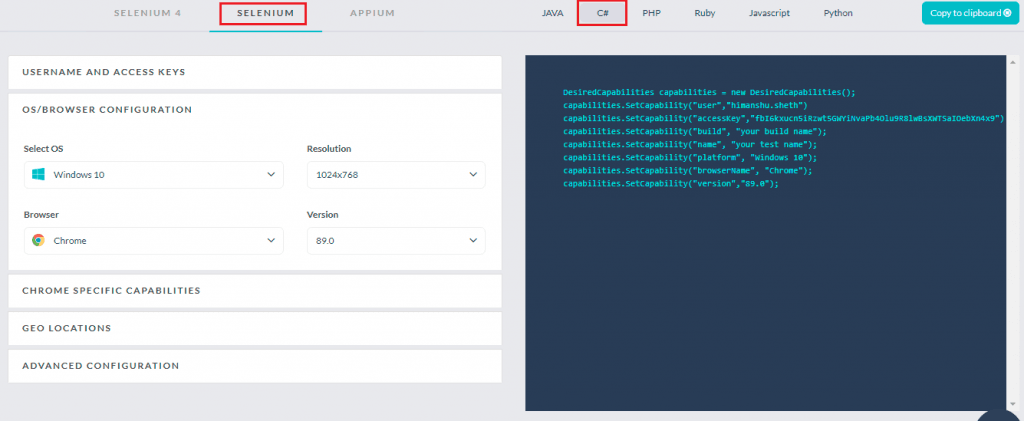
The test is run on Selenium 3 Grid. Hence, we have used desired browser capabilities in the implementation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
String username = "user-name"; String accesskey = "access-key"; String gridURL = "@hub.lambdatest.com/wd/hub"; [SetUp] public void start_Browser() { DesiredCapabilities capabilities = new DesiredCapabilities(); capabilities.SetCapability("user", username); capabilities.SetCapability("accessKey", accesskey); capabilities.SetCapability("build", "[C#] Demo of Web Scraping in Selenium"); capabilities.SetCapability("name", "[C#] Demo of Web Scraping in Selenium"); capabilities.SetCapability("platform", "Windows 10"); capabilities.SetCapability("browserName", "Chrome"); capabilities.SetCapability("version", "latest"); |
Step 3 – Create an instance of Selenium RemoteWebDriver.
An instance of Remote WebDriver is created using the browser capabilities (generated in the previous step) and the access-credentials of the LambdaTest platform. You can get the access details (i.e., user-name & access-key) from the LambdaTest Profile Page.
The LambdaTest Grid URL [i.e. @hub.lambdatest.com/wd/hub] is also passed an argument to the RemoteWebDriver interface.
|
1 |
driver = new RemoteWebDriver(new Uri("https://" + username + ":" + accesskey + gridURL), capabilities, TimeSpan.FromSeconds(600)); |
Step 4 – Navigate to the LambdaTest YouTube URL.
Using WebDriver.URL, we navigate to the URL under test.
|
1 |
driver.Url = test_url_1; |
Step 5 – Wait for the page load to complete.
We want to start the test only when the loading of the web page is complete. Using Explicit Wait in Selenium, a WebDriverWait of 10 seconds is initiated.
|
1 2 |
var timeout = 10000; var wait = new WebDriverWait(driver, TimeSpan.FromMilliseconds(timeout)); |
Document.readyState property describes the loading state of the document. Document.readyState equates to complete when the current HTML document (or page) and its resources have finished loading. An explicit wait is performed on the Document.readyState till its value equates to ‘complete.’ The ExecuteScript method in the JavascriptExecutor interface is used for executing the JavaScript in the context of the current page.
|
1 |
wait.Until(d => ((IJavaScriptExecutor)d).ExecuteScript("return document.readyState").Equals("complete")); |
If the document is not loaded within the maximum wait duration (i.e., 10 seconds), a timeout error occurs, and a further part of the test is not executed.
Step 6 – Load all the YouTube Videos on the page.
When we load the LambdaTest YouTube page, only 30 videos will be available (or loaded) on the page. As we want to scrap details of all the videos on the page, we perform a vertical scroll until the page’s end is reached.
The document.documentElement.scrollHeight method in JavaScript returns the height of the entire document. A while loop is run for scrolling till the end of the document (or page) and the window.scrollTo method in JavaScript scrolls to a specified set of coordinates in the document.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Int64 last_height = (Int64)(((IJavaScriptExecutor)driver).ExecuteScript("return document.documentElement.scrollHeight")); while (true) { ((IJavaScriptExecutor)driver).ExecuteScript("window.scrollTo(0, document.documentElement.scrollHeight);"); Thread.Sleep(2000); /* Calculate new scroll height and compare with last scroll height */ Int64 new_height = (Int64)((IJavaScriptExecutor)driver).ExecuteScript("return document.documentElement.scrollHeight"); if (new_height == last_height) /* If heights are the same it will exit the function */ break; last_height = new_height; } |
At each step in the while loop, the document’s current height is checked to ensure that we scroll until the page’s end. Once the current height and previous height (of the page) are the same, it means that we have reached the end of the page, and we break from the while loop.
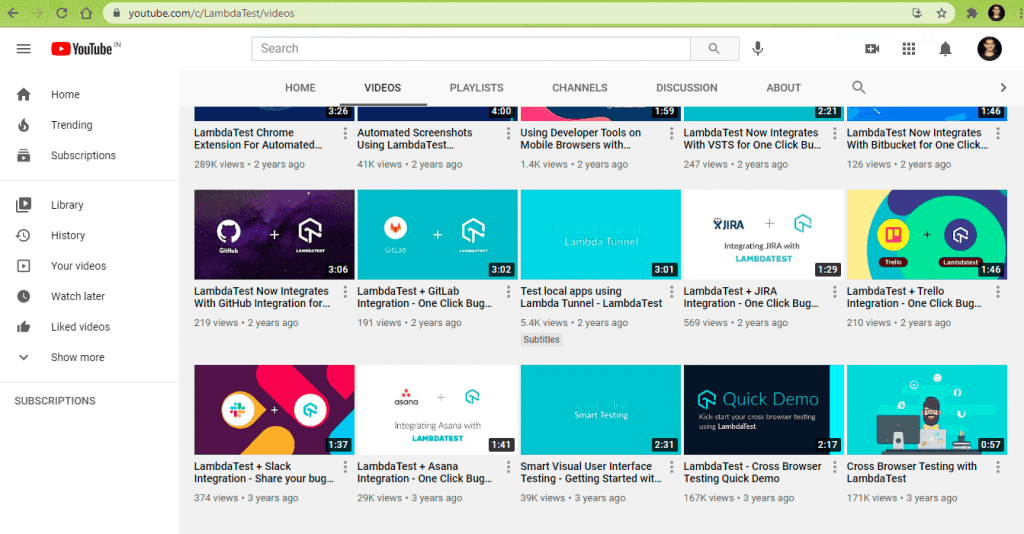
This is the page when the LambdaTest YouTube Channel is loaded in the web browser:

The LambdaTest YouTube Channel page after the ‘end of the page’ scroll is performed using the scrollTo method in JavaScript.
Step 7 – Create a ReadOnlyCollection of the VideoElements on the page.
This is the most important step when it comes to scraping dynamic web pages in Selenium. Whether it is static or dynamic web page scraping, we need to identify WebElements that house (or contain) the items from where the relevant information has to be scraped. In the case of LambdaTest YouTube Channel (or any YouTube channel page), all the videos are enclosed under a div with id: items and class: style-scope ytd-grid-renderer.
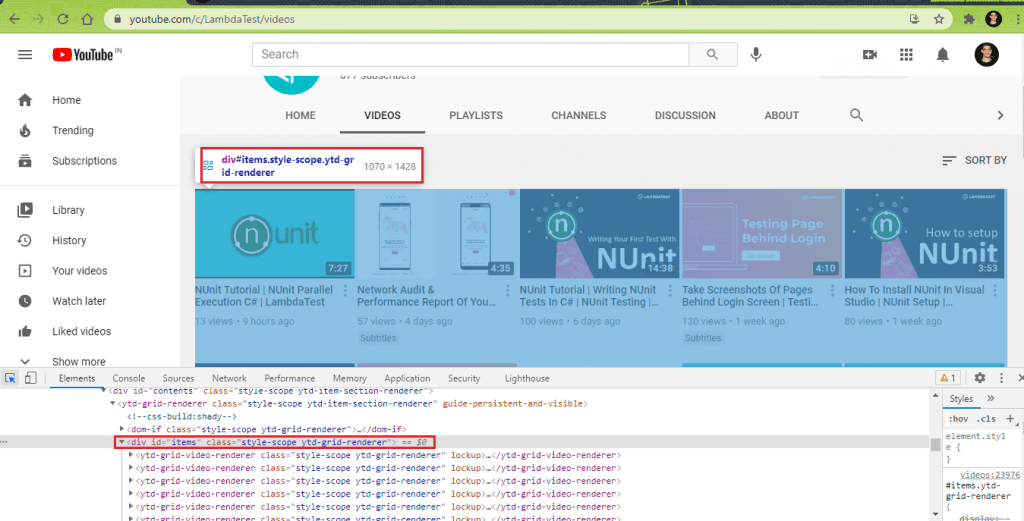
Inside the <div> container, every video is enclosed in a class style-scope ytd-grid-renderer.
Here are the details for the first 2 videos obtained using the ‘Inspect Tool’ in Chrome browser:
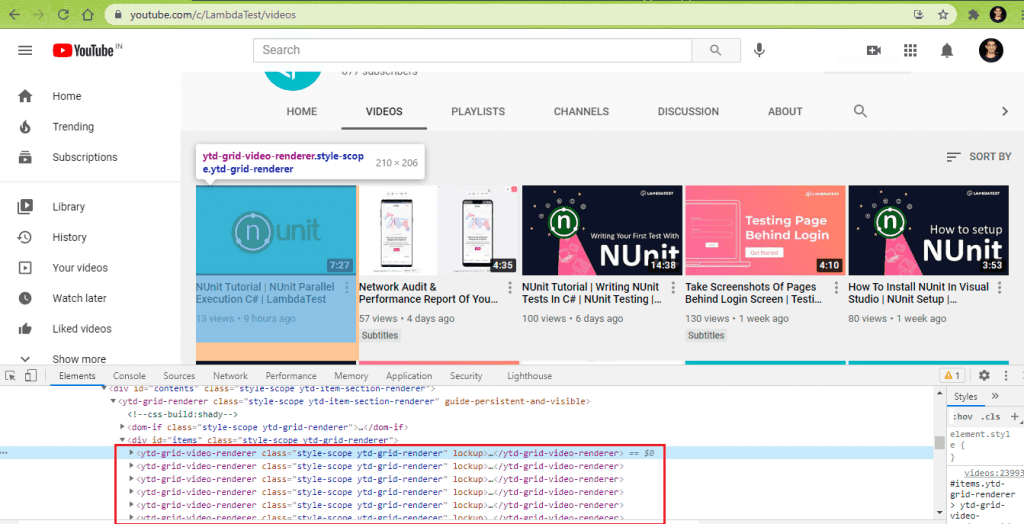
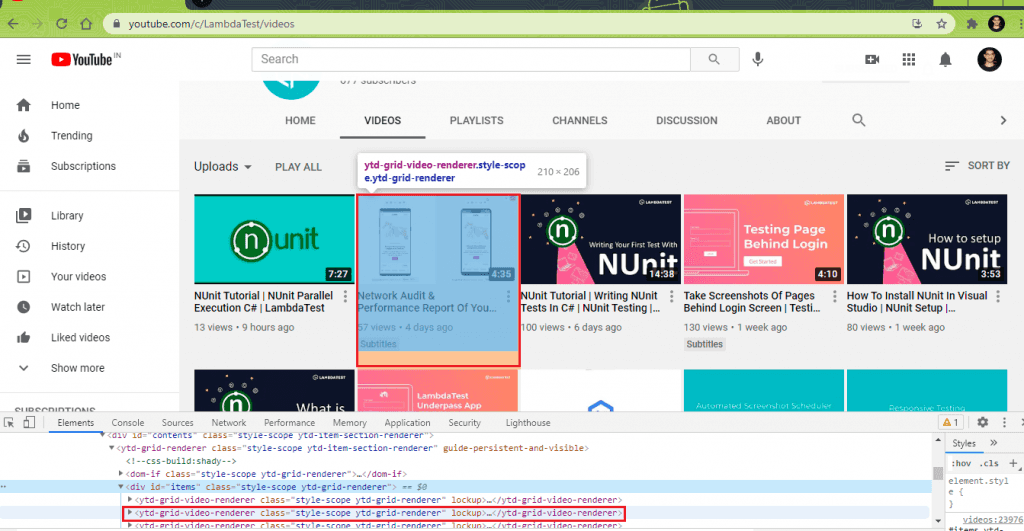
A variable of By attribute in Selenium is created that uses the CssSelector property ytd-grid-video-renderer.style-scope.ytd-grid-renderer.
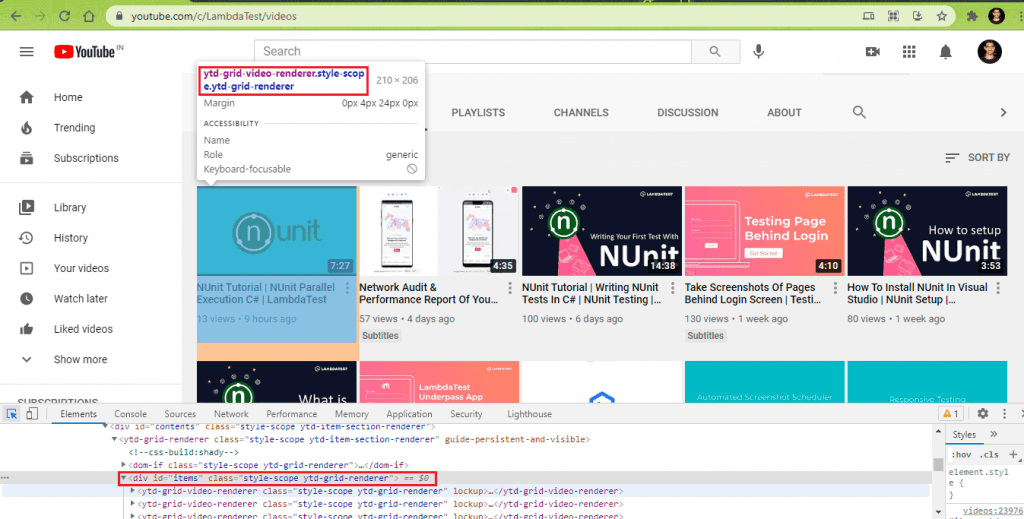
A ReadOnlyCollection (or list) of type IWebElement is created that contains the WebElements located using the FindElements method (and CssSelector property obtained in the earlier step).
|
1 2 |
By elem_video_link = By.CssSelector("ytd-grid-video-renderer.style-scope.ytd-grid-renderer"); ReadOnlyCollection<IWebElement> videos = driver.FindElements(elem_video_link); |
Since the page contains 79 videos (at the time of writing this article), the count method on the created list (or ReadOnlyCollection) returns 79.
|
1 |
Console.WriteLine("Total number of videos in " + test_url_1 + " are " + videos.Count); |
Step 8 – Parse the list of IWebElements to obtain the MetaData of the videos.
Parse through the list created in the earlier steps to obtain the video title, views, and upload date for each video in the list.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
foreach (IWebElement video in videos) { string str_title, str_views, str_rel; IWebElement elem_video_views = video.FindElement(By.XPath(".//*[@id='metadata-line']/span[1]")); str_views = elem_video_views.Text; IWebElement elem_video_reldate = video.FindElement(By.XPath(".//*[@id='metadata-line']/span[2]")); str_rel = elem_video_reldate.Text; vcount++; } |
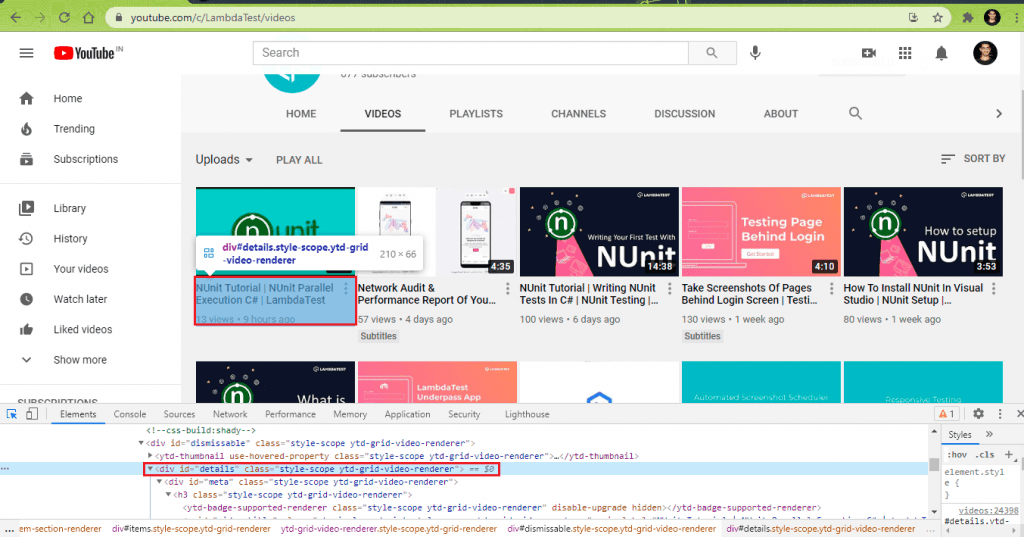
8.1) Scrap Video Title for every video (in the Video List/Channel).
The meta <div> in the “style-scope ytd-grid-video-renderer” class contains every video’s metadata on the page.
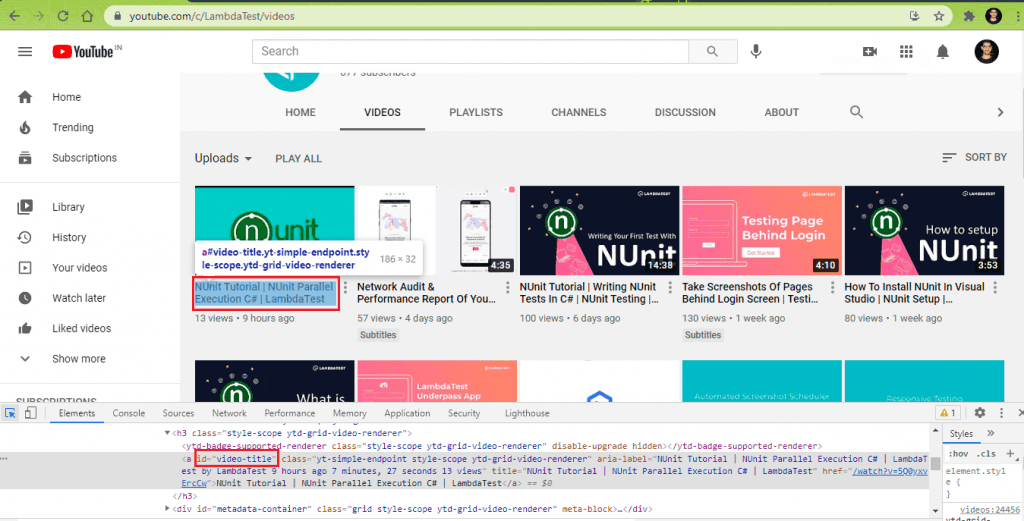
The Video Title of each video in the list is obtained by reading the CssSelector property [ #video-title ].
|
1 2 |
IWebElement elem_video_title = video.FindElement(By.CssSelector("#video-title")); str_title = elem_video_title.Text; |
8.2) Scrap Video Views for every video (in the list/Channel).
The WebElement that contains the video views obtained using the findElement method with the XPath property. A dot (.) is used at the start of the XPath since we want the XPath search to be restricted to the required WebElement (i.e., video).
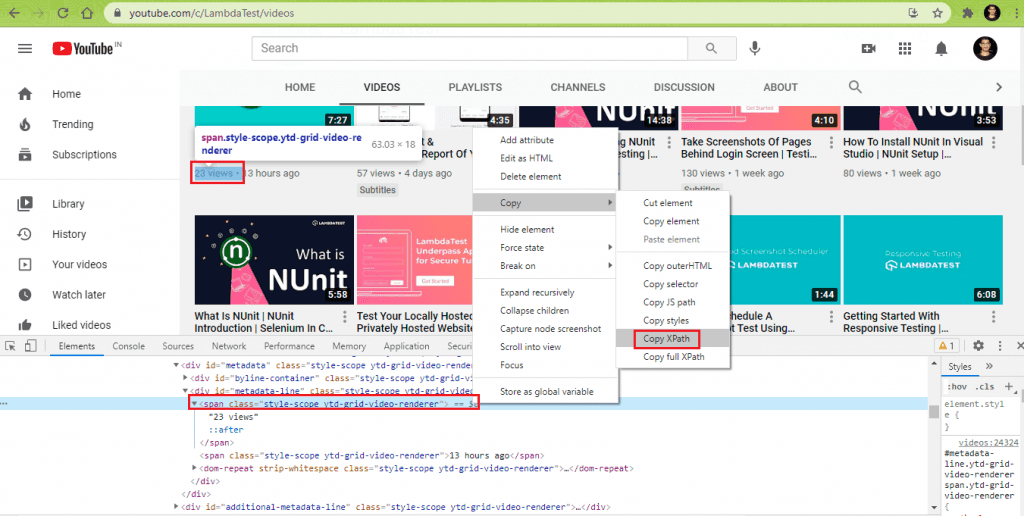
|
1 |
IWebElement elem_video_views = video.FindElement(By.XPath(".//*[@id='metadata-line']/span[1]")); |
Now that we have located the WebElement containing the video views, the Text property of the WebElement is used to obtain the video views.
|
1 |
str_views = elem_video_views.Text; |
8.3) Scrap Upload Details for every video (in the list/Channel).
Similar to step (8.2), the XPath of the WebElement that displays the video’s upload details is obtained using the ‘Inspect Tool’ in Chrome.
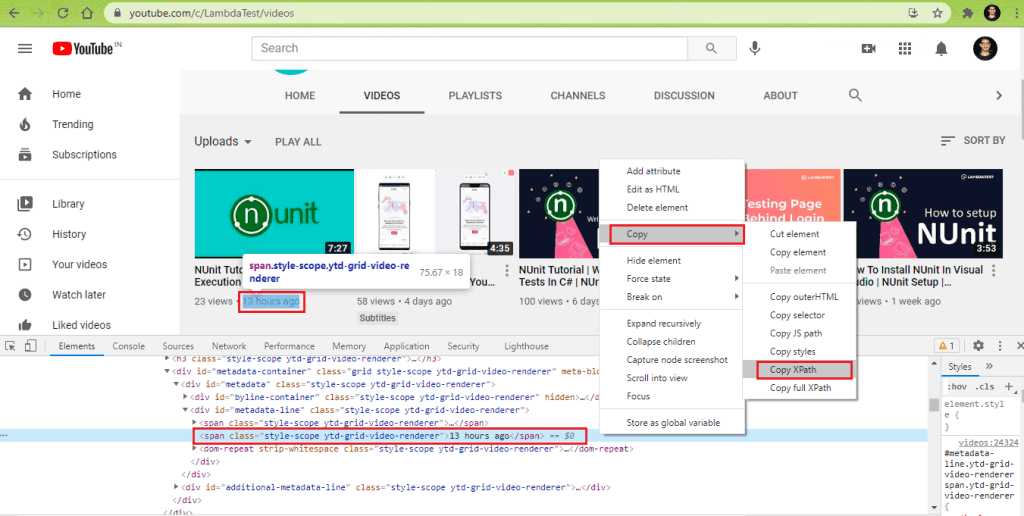
Once we have the XPath of the element, the findElement method in Selenium is used to locate the element using the XPath property.
|
1 |
IWebElement elem_video_reldate = video.FindElement(By.XPath(".//*[@id='metadata-line']/span[2]")); |
The text property of the WebElement gives the upload details of the video.
|
1 |
str_rel = elem_video_reldate.Text; |
Steps 8.2 through 8.3 are repeated for all the videos in the channel (or list). In our case, the total video count was 79. Hence the sub-steps in step(8) will be run 79 times. In our case, we print the details of each video on the terminal.
Execution
Here is the truncated execution snapshot from the VS IDE, which indicates that there are a total of 79 videos on the LambdaTest YouTube channel.
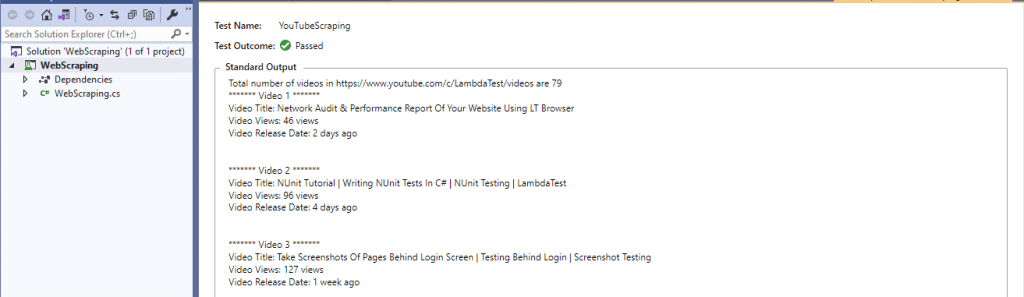
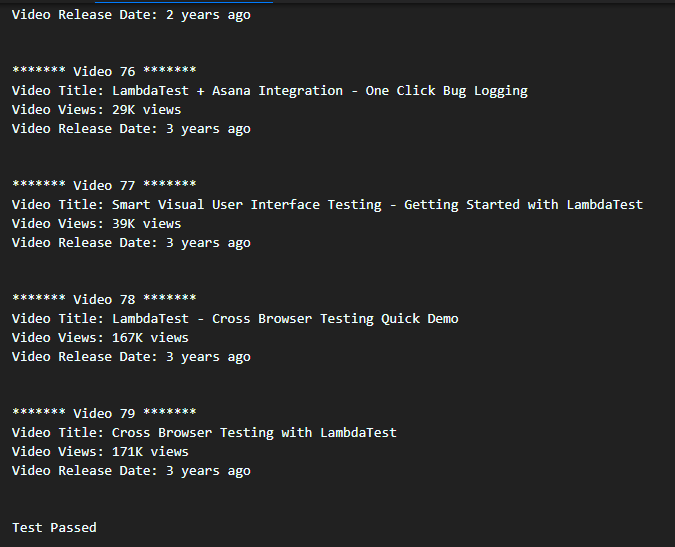
We obtained the Standard Output by doing ‘Copy All’ in the Standard Output area. As seen below, we could successfully do dynamic web page scraping of LambdaTest YouTube channel:
Web Scraping LambdaTest Blog Page
In this demonstration, we scrap the following data from the LambdaTest Blog:
- Blog Title
- Blog Link
- Blog Author
- Blog Views & Read Duration
Though the demonstration is limited to scraping data on the blog’s first page, it can be further extended to scrap relevant information from the blog’s subsequent pages.
Here is the Selenium web scraping test scenario that will be executed on Chrome (on Windows 10). The test is run on a cloud-based Selenium Grid provided by LambdaTest.
- Go to https://www.lambdatest.com/blog/.
- Scrap the blog title, blog author, blog perm link, blog views, and read duration for each blog article on the homepage of LambdaTest blog.
- Print the scraped information on the terminal.
Implementation
Code Walkthrough
Step (1) – Step (5)
These steps remain the same as the previous example. Please refer to the earlier section for a detailed explanation of those steps.
Step 6 – Create a ReadOnlyCollection of the Blogs on the page.
On the LambdaTest Blog page, we see that each blog article is enclosed under the following <div>.
|
1 |
<div class="col-xs-12 col-md-12 blog-list"> |
Hence, the findElements method is used with the CssSelector property to locate the blog articles’ total number on the Blog home page.
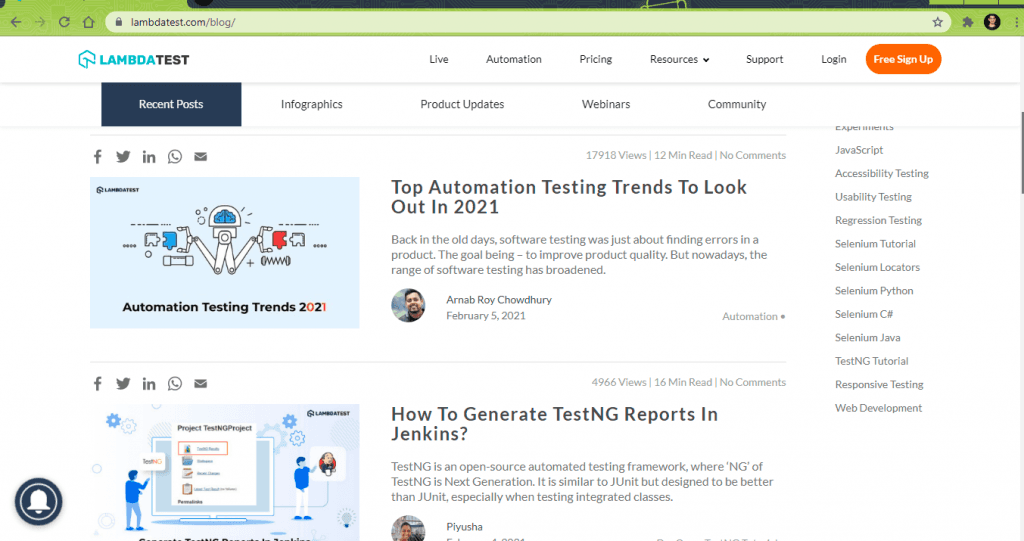
Here are the details for the first 2 blog articles obtained using the ‘Inspect Tool’ in Chrome browser: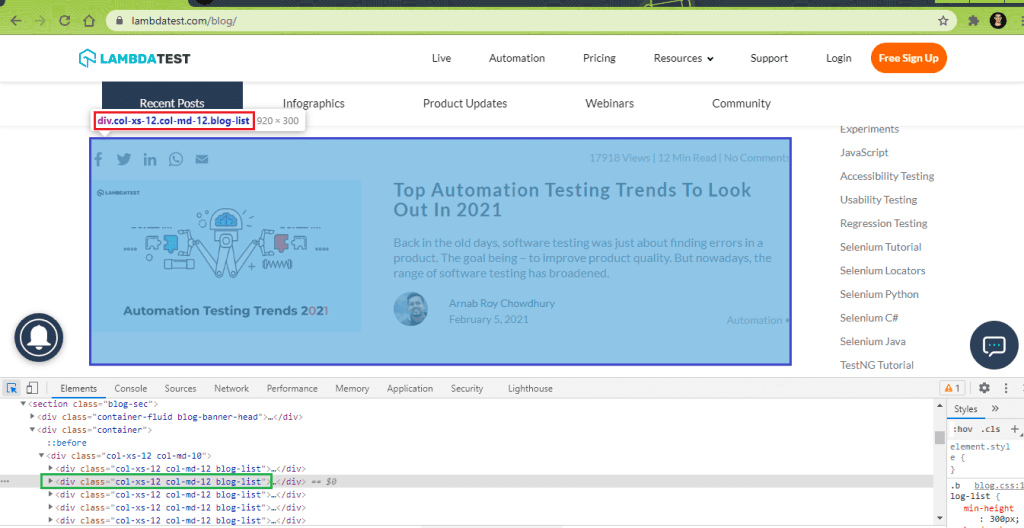
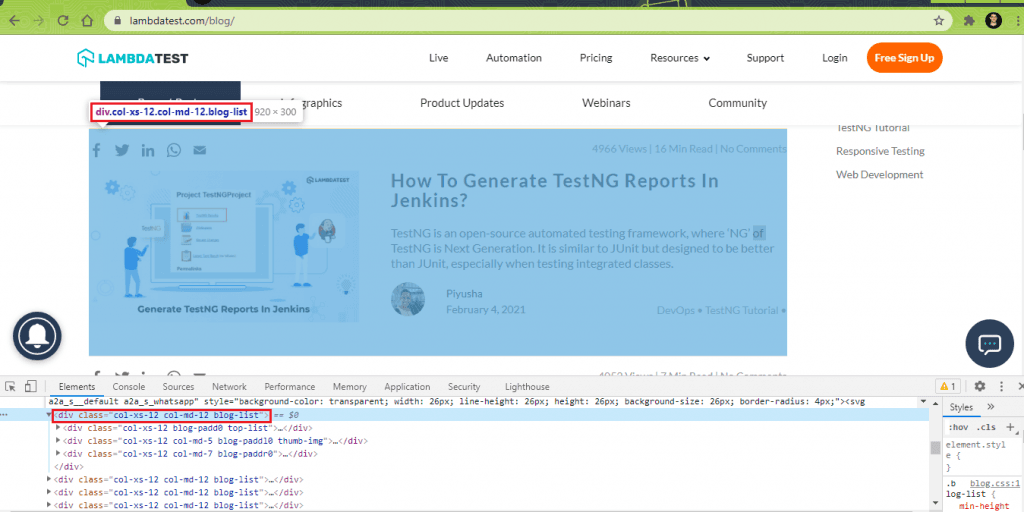
This is an overall view of the DOM, which shows that there are a total of 10 blogs on the blog home page:
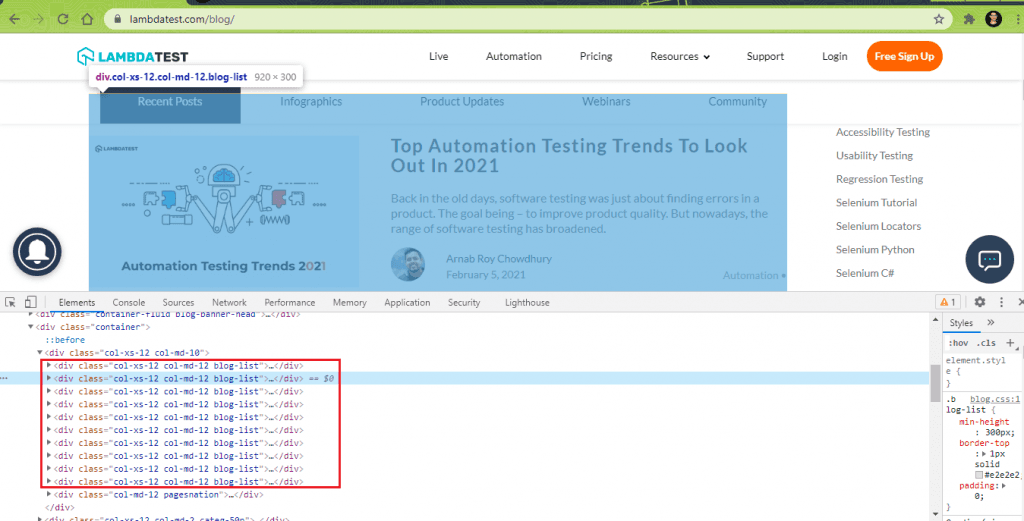
A ReadOnlyCollection (or List) is created containing the WebElements located using the FindElements method (and CssSelector property). Since there are 10 blogs on the home page, the ‘count’ property of the list (or collection) will return 10.
|
1 2 3 |
/* Find total number of blogs on the page */ By elem_blog_list = By.CssSelector("div.col-xs-12.col-md-12.blog-list"); ReadOnlyCollection<IWebElement> blog_list = driver.FindElements(elem_blog_list); |
Step 7 – Parse the list of IWebElements to obtain the MetaData of the blogs.
Parse through the list created in step (6) to scrap every blog’s required information in the list.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
foreach (IWebElement blog in blog_list) { string str_blog_title, str_blog_author, str_blog_views, str_blog_link; IWebElement elem_blog_title = blog.FindElement(By.ClassName("blog-titel")); str_blog_title = elem_blog_title.Text; IWebElement elem_blog_link = blog.FindElement(By.ClassName("blog-titel")); IWebElement elem_blog_alink = elem_blog_link.FindElement(By.TagName("a")); str_blog_link = elem_blog_alink.GetAttribute("href"); IWebElement elem_blog_author = blog.FindElement(By.ClassName("user-name")); str_blog_author = elem_blog_author.Text; IWebElement elem_blog_views = blog.FindElement(By.ClassName("comm-count")); str_blog_views = elem_blog_views.Text; vcount++; } |
7.1) Scrap Blog Title for each blog (in the list).
The class name ‘blog-titel’ inside the parent class ‘col-xs-12 col-md-12 blog-list’ contains the href (or link to the blog post) and the blog title.
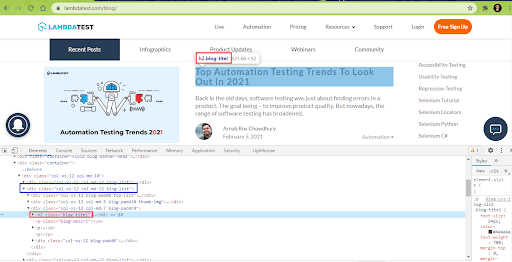
The findElement method is used with className (i.e., blog-titel) property to locate the WebElement that gives the blog title. The Text property of the located WebElement gives the title of each blog post in the list.
|
1 2 |
IWebElement elem_blog_title = blog.FindElement(By.ClassName("blog-titel")); str_blog_title = elem_blog_title.Text; |
7.2) Scrap Blog Post Link from every blog (in the list).
The class name ‘blog-titel’ inside the parent class ‘col-xs-12 col-md-12 blog-list’ also contains the href (or link to the blog post). We first locate that WebElement using the ClassName property.
|
1 |
IWebElement elem_blog_link = blog.FindElement(By.ClassName("blog-titel")); |
Once we have located the WebElement [i.e., elem_blog_link], the findElement method is applied on it with the TagName locator set to anchor tag [i.e. ‘a’].
|
1 |
IWebElement elem_blog_alink = elem_blog_link.FindElement(By.TagName("a")); |
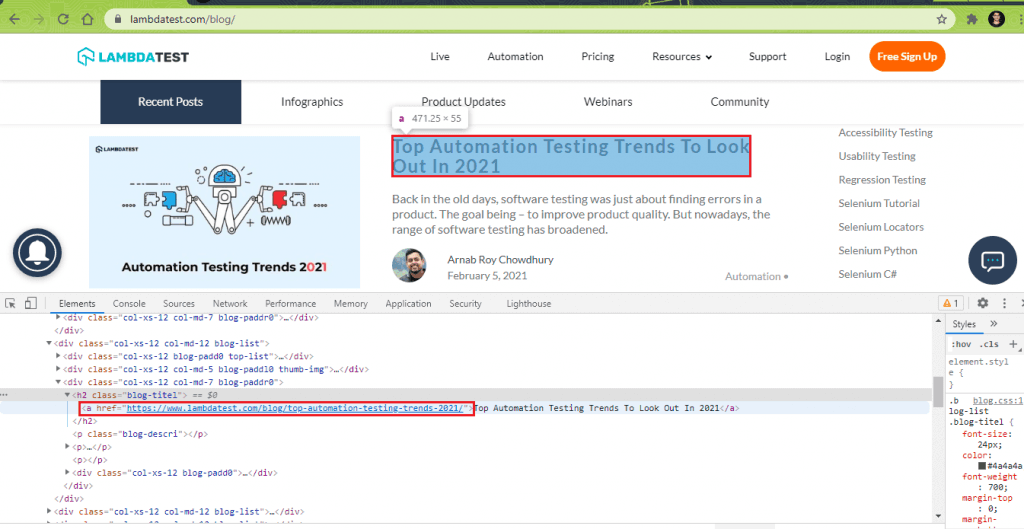
On the located WebElement [i.e., elem_blog_alink], GetAttribute in Selenium is used to get the value of that element’s ‘href’ attribute.
|
1 |
str_blog_link = elem_blog_alink.GetAttribute("href"); |
The output is the ‘href’ (or permalink) of each blog post in the list.
7.3) Scrap Author Name for every blog (in the list).
The WebElement that gives the ‘Author Name’ is located using the ClassName property. As seen below, the “user-name” class contains the author’s name.
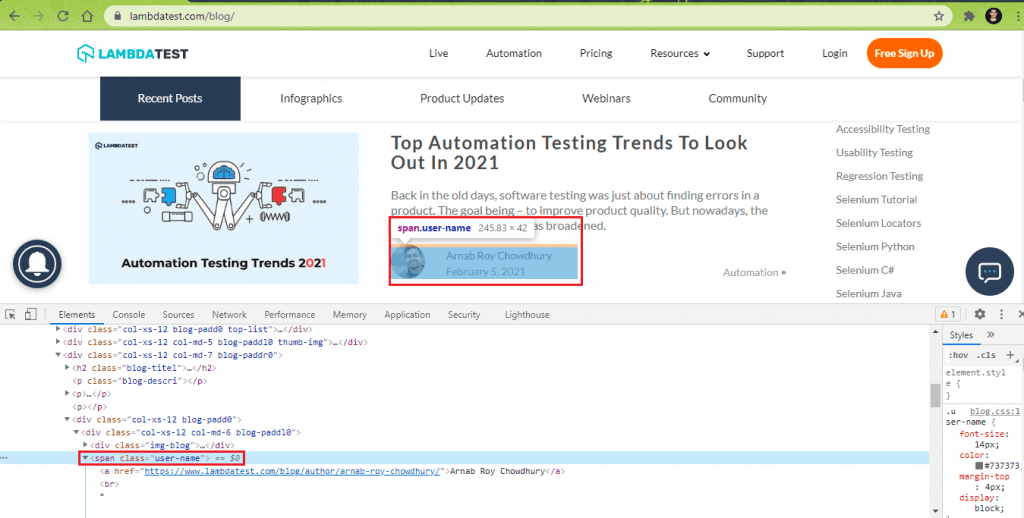
The FindElement method locates the WebElement using the “user-name” class.
|
1 |
IWebElement elem_blog_author = blog.FindElement(By.ClassName("user-name")); |
The Text property of the WebElement gives the author name for the located WebElement [i.e., elem_blog_author].
|
1 |
str_blog_author = elem_blog_author.Text; |
7.4) Scrap Blog Views & Read Duration for each blog (in the list).
The WebElement that gives the ‘Blog Views & Read Duration’ is located using the ClassName property. As seen below, the “comm-count” class contains the views and estimated time duration to read that blog article.
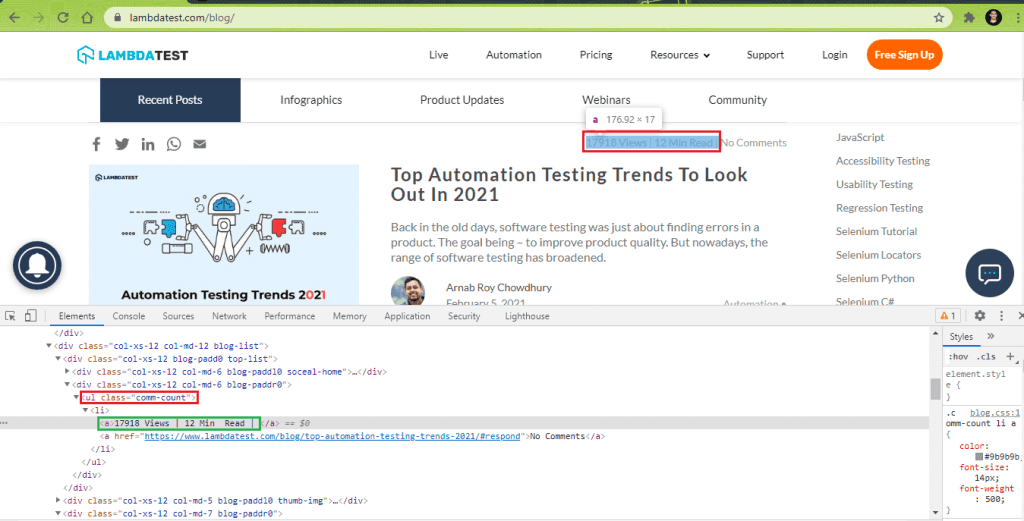
The FindElement method locates the WebElement using the “comm-count” class.
|
1 |
IWebElement elem_blog_views = blog.FindElement(By.ClassName("comm-count")); |
The Text property of the WebElement gives the blog views & estimated time duration for the located WebElement [i.e., elem_blog_views].
|
1 |
str_blog_views = elem_blog_views.Text; |
Execution
Here is the truncated execution snapshot from the VS IDE, indicating that details of the 10 blogs are scrapped successfully.
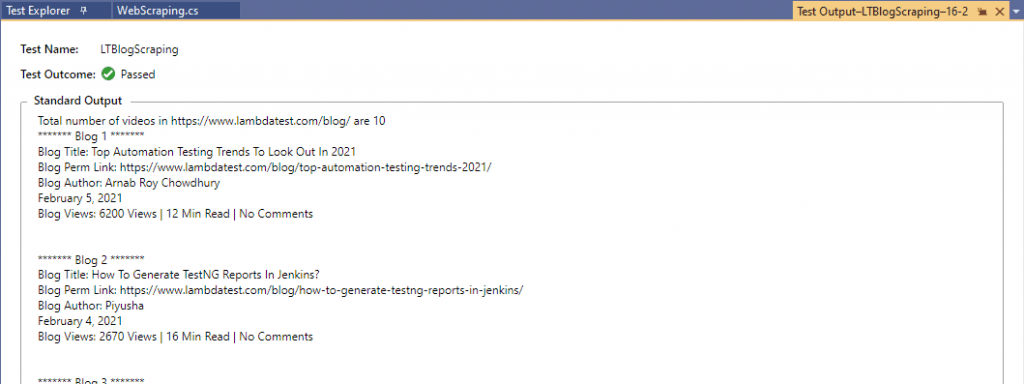
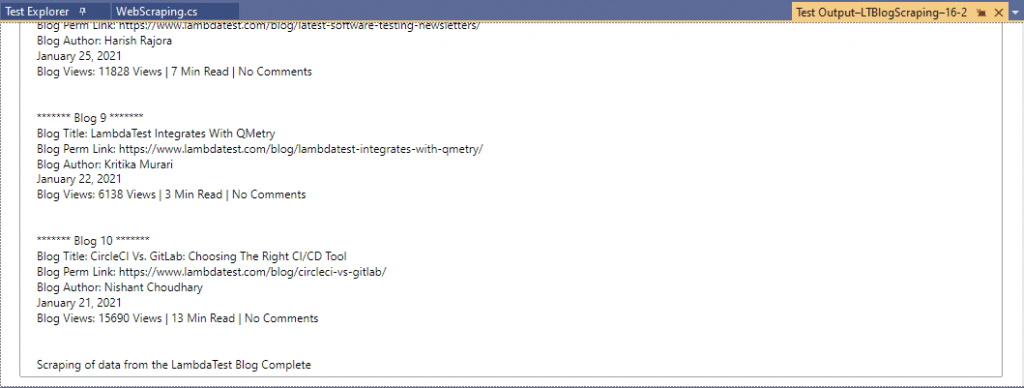
Shown below is the execution snapshot of both the test scenarios that demonstrated scraping dynamic web pages in Selenium:
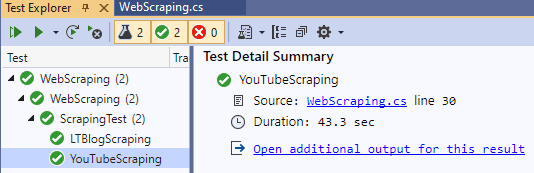
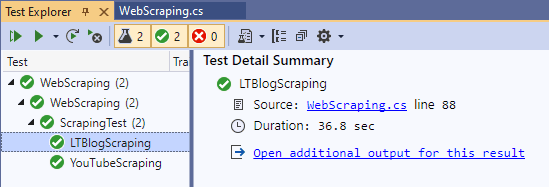
We are done Scraping!

In this Selenium C# tutorial, we laid the foundation blocks for web scraping with Selenium C#. There is a lot of difference between scraping static web pages and dynamic web pages. There are a number of tools like VisualScrapper, HTMLAgilityPack, etc., used for scraping static web pages. However, Selenium is the most preferred tool when it comes to dynamic web page scraping. The FindElements method in Selenium helps in locating the list (or collection) of web element(s). The FindElement method is used on the collection (obtained using FindElements) to scrap relevant information from the objects in that list.
Do let us know how you use Selenium for dynamic web page scraping, please leave your feedback in the comments section…
Happy Scraping!
Frequently Asked Questions
Can websites detect web scraping?
Most websites have almost the same coding structure. Therefore, a single way of scraping might be constructed repeatedly by the website owners. This might cause you to get detected as a scraper. Sometimes developers even include the detection of scraper into their source code, and this would cause it to fail-fast before you are able to get any data from it.
How do I crawl a dynamic Web page?
Web Crawling is the technology that helps you quickly index websites so search engines can find and organize your content. It starts with the seeding of the URLs, then fetching the content of these URLs, parsing the content (get the text for indexing as well as outlinks), and indexing the content.


Author’s Profile
Himanshu Sheth
Himanshu Sheth is a seasoned technologist and blogger with more than 15+ years of diverse working experience. He currently works as the 'Lead Developer Evangelist' and 'Senior Manager [Technical Content Marketing]' at LambdaTest. He is very active with the startup community in Bengaluru (and down South) and loves interacting with passionate founders on his personal blog (which he has been maintaining since last 15+ years).
Blogs: 130
Got Questions? Drop them on LambdaTest Community. Visit now














