

Reducing Production Failures by Improving Quality: Vinayak Hegde [Testμ 2022]
LambdaTest
Posted On: August 31, 2022
![]() 8122 Views
8122 Views
![]() 6 Min Read
6 Min Read
Production failures in software are one of the most costly and time-consuming challenges a project can face. It is an incident in the live production environment where the end-user requirements don’t meet as expected. Therefore, it becomes critical to track the production failures since it defines how effective your testing process is. The priority of production defects specifies how quickly you need to fix the issues.
So what can you do to reduce production failures? Well, there are many things that can be done early on and during the software development cycle to mitigate production failures.
In our next incredible session of the Testμ conference, Vinayak Hegde – CTO-in-residence at Microsoft for Startups, and Mohit Juneja – VP, Strategic Partnerships and Business Development at LambdaTest talk about various techniques for reducing software failure risk in production by leveraging different technology and processes like code profiling, observability, static analysis, code coverage, and more.
So, without further ado, let’s dive ahead!
Vinayak Hegde started the session by talking about the software life cycle and its stages: code, build & test, deploy, and production. He mainly emphasized the code and production stage.
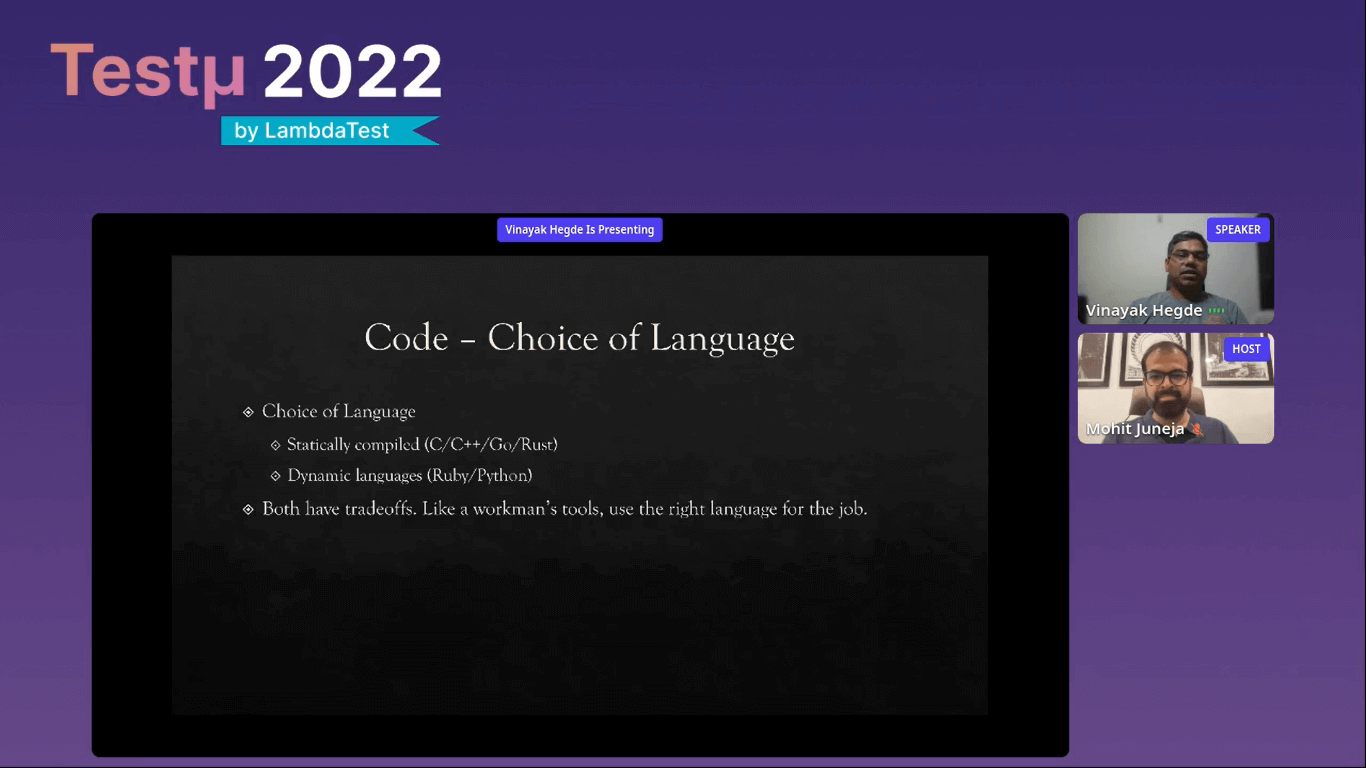
Code
Vinayak lists down the five different things about the coding stage.
- Choice of language: When working with a startup, you may come across a question: how do you choose a tech stack? When you are starting up, you wish to run a build fast and don’t want to have complicated setups. So you want the language and tools to be malleable. Most startups start with Ruby and Python language.
However, they can also choose statically compiled languages like C/C++/C Sharp/Rust. Both dynamic and static tools have tradeoffs. Like a workman’s tool, you must use the right tools for the job. - Design by contract: It is a notion of a contract that extends down to what is like a procedure method or a function level. Every specific function has a contract consisting of the following information:
- Acceptable or unacceptable input values or types and their message.
- Return value or types and their meanings
- Error and exception condition values or types that can occur and their meanings.
- Side effects
- Pre-conditions
- Post-conditions
- Invariants
- Programming safety: If you look at the overall landscape, you will notice the bugs are associated, especially with old software that is returned with C++, and there are a lot of other issues with memory safety.
When Microsoft researched this vulnerability database, it found that almost 70% of errors can be caught because of memory safety, and the rest can be caught by checking for thread safety.
Rust language is regarded as memory safe and goes out of its way to ensure that concepts like ownership offer specific memory blocks. There is a concept of borrow and checker, which is used to check whenever you’re using a memory or any kind of memory chunk or variable. - Linters and static analysis: It is a tool that analyzes source code to flag programming errors, bugs, stylistic errors, and suspicious constructs. They perform checks like indexing beyond errors, dereferencing null pointers, potentially dangerous data type combinations, and non-portable constructs. Examples of linters are PyLint, Js lint, etc., and they can be easily added to the developer workflow.
Then comes static analysis, which analyzes source code to flag programming errors related to security issues. It performs checks like pattern-based simulation, quality and complexity metrics, best practice recommendations for developers, etc. Examples of static analysis include HelixQAC, Coverity, etc. - Code profilers: They validate the application’s source code to ensure it is optimized, which results in high application performance. It analyzes the memory, CPU, and network utilized by each component of an application. Code profilers are of two types: sampling and instrumentation profilers.
Profilers perform checks like coverage, allocation, resource usage, etc. Some examples of profilers are Gprof, and oprofile.
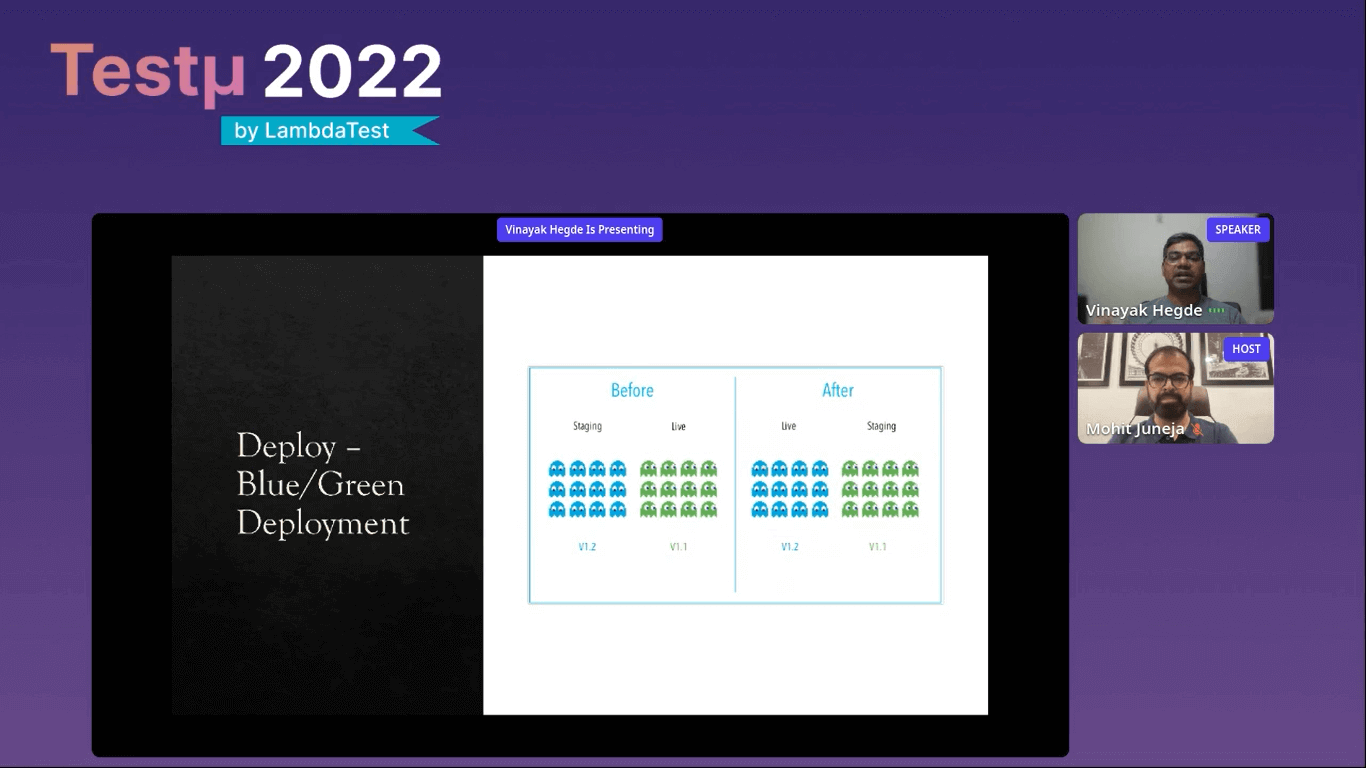
Vinayak then briefly touched upon the build and test stage, explaining the concepts like load testing, trace testing, and fuzz testing. He then talked about the deployment stage and its two steps: Canary testing and blue/green deployment.
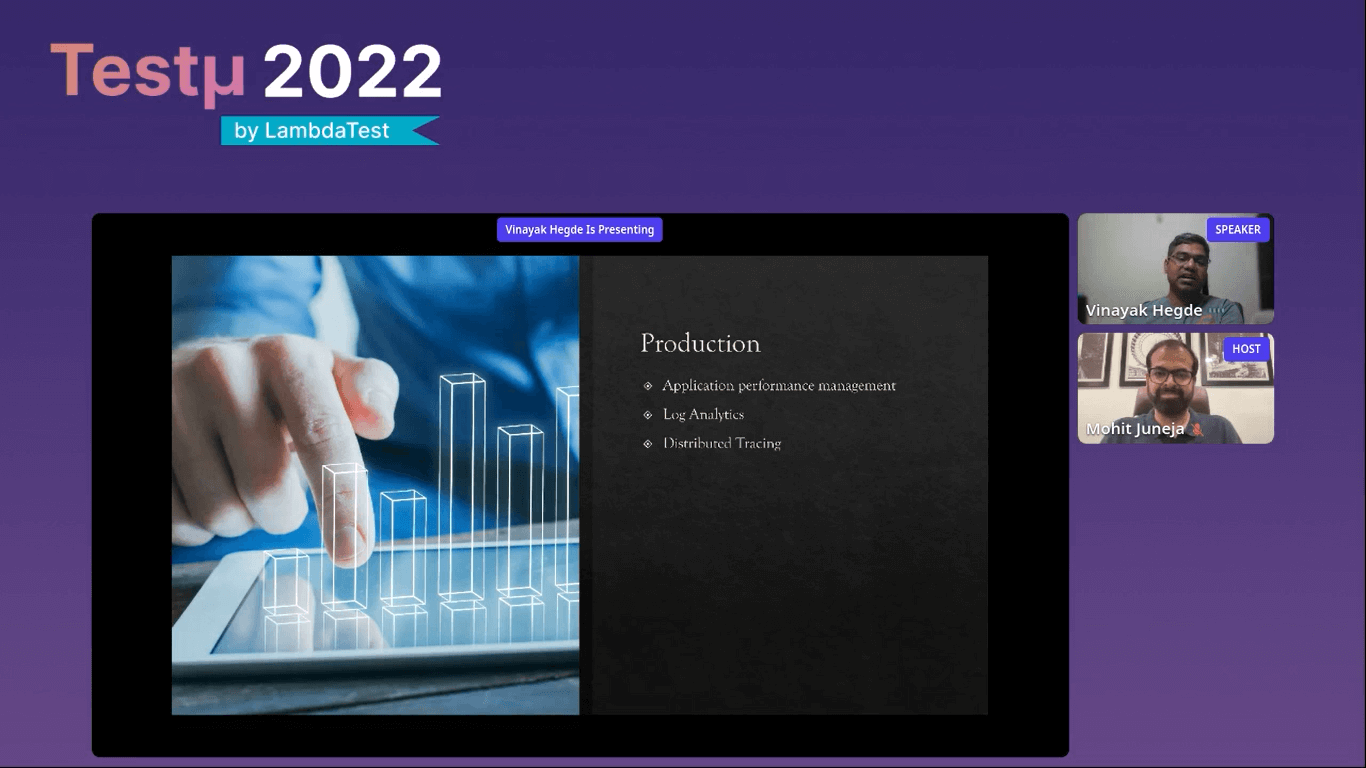
Production
Once you perform blue/green deployment and your code is live. Does this mean you caught all of the bugs? – he added.
No!
Even if your code doesn’t have a bug, you still need to run some performance tests to determine how it works in real-world scenarios.
In the production stage, there are three different parts that you need to take care of
- Application performance management: It performs sampling in the production environment and provides real-world performance. Example: NewRelic, Azure app analytics, etc.
- Log analytics: It identifies error rates in production with the help of application logs and parsing. Example: Azure Data Explorer and open-source ELK stack.
- Distributed tracing: It tracks application requests as they flow from front-end devices to back-end services and databases. Example: Jaeger and open telemetry.
- As the CTO of a startup, when do you add QA professionals to the team? I have seen many startup companies hire QA after a few years. In that case, how do you set up the QA processes to deliver Quality Product?
- How do we avoid flaky test cases?
- What should be the level of Language proficiency ( Beginner, Intermediate, Professional) when you are starting as an Automation Engineer?
Q & A session!
The following are some questions that were asked during the session.
Vinayak: It depends on the product and context, but you should ideally have something like test-driven development. If you are not doing test-driven development at some point when the product has traction and starts getting users.
Those users are paying you for software to work reliably, so if you’re not setting up a QA team, or I would not say that QA team because I think software quality is not just the job of the QA team or the person, it is also the job of the developer.
Vinayak: There are two things: one is the flaky test, and another one is documentation. It requires significant effort to keep them in sync and boils down to culture. The way I have done that as a CTO is a regular review for the QA team as to which tests are failing, why they are failing, and whether they are even relevant.
Vinayak: I always felt that automation is not given its due, and language proficiency is at least, I would say, intermediate. If you don’t understand what that piece of code is doing because the developer has a mental model, and as a QA person, you are writing automation test cases. Still, you should also try to break that mental model as a QA and security tester. So knowing where those bugs are creeping in, you need to have at least an intermediate level of language and system understanding.
After the successful Testμ Conference 2022, where thousands of testers, QA professionals, and developers worldwide joined together to discuss on future of testing.
Join the testing revolution at LambdaTest Testμ Conference 2023. Register now!” – The testing revolution is happening, and you don’t want to be left behind. Join us at LambdaTest Testμ Conference 2023 and learn how to stay ahead of the curve. Register now and be a part of the revolution.



Author’s Profile
LambdaTest
LambdaTest is a continuous quality testing cloud platform that helps developers and testers ship code faster.
Blogs: 182
Got Questions? Drop them on LambdaTest Community. Visit now












