

Examples of Generative AI for Software Testing
Matt Heusser
Posted On: August 21, 2023
![]() 46508 Views
46508 Views
![]() 15 Min Read
15 Min Read
About ten years ago a certain large technology company had giant banners announcing their “futurists.”. I remember a big billboard in Toronto, Canada,detailing a vision of a future where you could speak software into existence, and perhaps even think it into being. Given that English, like other human non-scientific languages, is a vague and ambiguous language, I doubted it. While AI struggles to translate words into symbols as effectively as humans, even when teams of people collaborate on written descriptions, they often have wildly different understandings of what should be created.
Then, the Large Language Models arrived, which promise to take ambiguous natural language as input and generate code. There are, however, classic engineering problems with this. Fred Brooks, the lead manager on OS/360, one of the world’s first structured software engineering efforts with several hundred people of size, suggested that it was logically impossible to have a single silver bullet to slay the software development best. Brooks proposed that software works through different activities – requirements (what), design (how), code (build it), and test. Since no single activity takes more than 25% of the time, any silver bullet that made an activity instant and free would only be a 25% reduction. Brook’s solution was a series of bronze bullets, each one making things a little better.
Despite the rhetoric Brooks logic seems to apply today, simple english descriptions of software sent into AI do fall short. More than that, we can’t even “AI” our way out of the test process. What we might be able to achieve, though, is to identify a series of small, rapid victories in utilizing AI for testing. As we discussed previously, it’s worthwhile to be at the forefront of this endeavor.
As the landscape of software testing continues to evolve, the integration of Generative AI introduces innovative possibilities and challenges. We conducted a poll on LambdaTest’s social media platform, asking the community about their primary concerns regarding AI in test automation. The majority of respondents voiced their apprehension about “Data privacy” shedding light on a critical aspect that demands careful consideration in the era of advanced testing methodologies.

In this article, we’ll explore some AI use cases in testing. We’ve tried these techniques, either at work or on sample code from the public domain, and have some commentary to share. The ideas below look for bronze bullets using AI in all of software, but focused on test and quality.
Requirements
- Generating UNIT tests from given requirements involves processing plain English descriptions and, possibly, function signatures in a specific programming language or API. Large Language Model software (LLM) can analyze a few paragraphs to generate test ideas. if the code consists purely of business logic without “scaffolding” code or additional business logic, the tests can run. However, a significant challenge arises due to the extensive reliance on numerous code libraries in most software projects. Current AI tools like ChatGPT, Bard, and Copilot often struggle to accommodate the entire context in memory to generate setups for implied subclasses and dependencies present in complex production software. This is especially true for “unit” tests that, despite their names, rely on databases, files, APIs, and so on. Furthermore, a recurring issue is that cloud-based tools employ their inputs to self-improve. Many companies and commercial NDAs forbid sharing code and requirements with Google and Microsoft.
- Generating UNIT tests from given code is similar to the requirements scenario, where existing code is employed to generate unit tests. The challenge lies in determining the intended scope of testing within this context.Usually we check to make sure that the software will do what it should do. With no requirements, we would expect generated unit tests to check to make sure the software does … what it does. That might have little value during maintenance, if the changes alter its behavior, but is otherwise a circular reference.
Perhaps, at best, the generated tests could find crashes and unhandled exceptions. Still we wouldn’t expect the AI to recognize the correct behavior of the code without being told. Thus, we also would not expect it to generate unit tests that expose and cause failure when the software deviates. We asked ChatGPT to create tests for a Roman Number to decimal calculator. (Requirements code generated tests) The initial tests ChatGPT 3.5 produced asked for single digits, 1 to 3, additive digits, and examples that involved subtraction, such as IX or XL. It was a pleasant surprise when, after the first round of unit tests, we tried to ask for more tests to “break” or “stress” the software. These can find interesting use cases and unexpected combinations. The stress test of the roman numeral to decimal evaluator , here’s what ChatGPT 3.5 produced:
- Generate Specification-by-example code from given requirements. This is converting plain requirements into “Given … When … Then”, or GWT format. By establishing clear and precise terminology, it becomes feasible to automate these GWT documents, transforming them into executable examples. In general, the history of BDD is muddled. It is all too common that people produce volumes of very thick GWTs when plain English would do, then fail to automate the documents. many of these documents are left unautomated, resulting in requirements that resemble archaic 15th-century English legal proclamations. This makes them challenging to comprehend without the aid of suitable tools. there’s potential for AI tools to automate and maintain Given-When-Then scenarios more effectively. By leveraging AI, it becomes possible to take a function signature and generate the corresponding code, increasing the likelihood of successful automation. Our reviewer, Wouter Lagerweij, has reported promising outcomes in employing generative AI tools to craft “glue code” or boilerplate for BDD, a topic we will delve into more extensively in our upcoming article.
- Finding problems with requirements. Many requirements are inconsistent, vague, or open to multiple interpretations. To illustrate this, we presented ChatGPT with a set of requirements that mirrors the quality frequently encountered in organizational contexts. Consider it carefully.
- Explaining the code. ChatGPT can be surprisingly good at summarizing code snippets and translating them into human languages; we’ll provide an example in the next article. How useful those documents will be is unclear.
Using generative AI tools can streamline and enhance the accuracy of unit test creation from complex requirements or existing code. KaneAI stands out by addressing the limitations of traditional AI tools, which often struggle with intricate dependencies or ambiguous requirements.
KaneAI is a GenAI native QA Agent-as-a-Service platform that excels in generating precise tests directly from plain English descriptions and specifications, translating natural language instructions into automated tests. This not only ensures clarity but also reduces manual effort.
Additionally, KaneAI effectively handles inconsistent requirements and complex logic, offering actionable insights and improving test accuracy. With KaneAI, you benefit from intelligent, context-aware testing tailored to your needs, all while upholding privacy and compliance standards.

With the rise of AI in testing, its crucial to stay competitive by upskilling or polishing your skillsets. The KaneAI Certification proves your hands-on AI testing skills and positions you as a future-ready, high-value QA professional.
def test_stress_test
romannumeral = Romannumeral.new
min_numeral = 'I' * 1000
max_numeral = 'M' * 1000
assert_equal 1000, romannumeral.rn_to_decimal(min_numeral)
assert_equal 1000000, romannumeral.rn_to_decimal(max_numeral)
end
Reviewing this article, Harry Robinson pointed out that the assertion and values are an oracle, a programmed way of finding a problem. He raised an intriguing question: did humans initially create the original tests that ChatGPT then expanded upon? It’s conceivable that ChatGPT may have aligned with certain examples present on Github, even though we hadn’t provided any such examples to begin with. Notably, despite a thorough search of both GitHub and the wider internet, we were unable to uncover any parallels to this particular strategy. For that matter, more than three “I”‘s in a row is arguably an invalid Roman Numeral – we need requirements. The same applies for roman numerals with invalid letters, special characters, and decimals; we need to know what the software should do.
Acme auto insurance charges based on age. Clients under 16 cannot purchase insurance. Clients aged 16-21 pay $600 per month for insurance. 21 to 30 pay $500 per month. 30 to 40 pay $400 per month. 40 to 60 pay $350 per month. 61 to 99 pay $550 per month. In addition, acme insurance has a good student discount of -10% per month for students who get at least at 3.0 in school and maintain it. In addition, Acme has a safe driver discount of -5% for drivers who have had no accidents in 5 years. There is a bad driver penalty of +5% for drivers who have had one at-fault accident in the past 24 months and +10% for two or more at-fault accidents. Coverage is not offered if someone has had five at-fault accidents. Students who have the bad driver label are not eligible for the good student discount.
We hoped the tool would find that 21 and 30 are overlapping ages. It did, along with the overlap at 40. However, the tool falls short in providing guidance regarding a 100-year-old driver. Similarly, when faced with a scenario involving a responsible 22-year-old student driver, the tool does not offer a definitive solution. Should we deduct 10% from $500 or multiply $500 by 95% twice consecutively? The generative AI tool lacks the capability to advise us on this matter. Remember, LLM tools don’t have insight the way a human does – they find mathematical models for how words could be strung together. With enough training and a consistent domain, such as tax law, it might be more helpful. As of now, that would be under a great deal of human supervision.
Test Design
- Generating Test Ideas. Special Cases As A Checklist. Some of us can rattle off test ideas. Inject big data, try small data, use special characters, decimals, use strings when the software is expecting a number, leave the field blank, etc. Others just have a cheat sheet handy. It would be nice to have a tool smart enough to figure out which of these apply to a different domain. Go ahead and come up with your own test ideas, even do your own testing – then ask the tool for its ideas. Junior testers and testers looking to be more through can expect to find a gem or two in there, cheap.
- Generating Test Ideas – Combinatorial Test Cases. Given a set of possible inputs, all-singles, all-pairs, and all-triples are ways to reduce the executed tests to a few of the most powerful examples. When the combination is less than 35 test cases, ChatGPT generated test cases. Larger than that, it recommended a tool, such as Microsoft’s PICT, and actually converted the data we entered into parameters for PICT.
- Generating Synthetic Test Data. Wouldn’t it be nice to have a tool smart enough to answer a question like the one below:

I want to generate a .csv file. The fields are first name, last name, middle initial, social security, date of birth, sex, and home address with street number, street, city, state and zip. These should be people who live in Michigan with Allegan zip codes - that is 49010. They should have a rough bell curve of ages from 18-50. They should all have unique first and last names. 50 names should do.
With ChatGPT, now you can! Though ChatGPT kept trying to generate small samples. It needed to be coaxed to make more, maxing out at about 50 rows. Bard did even worse, creating ten rows then producing blank lines. There’s a bit more on test data generation in another article for the Lambdatest blog. And, of course,there are plenty of open source test data generators; they just don’t process natural English the way generative AI can.
Test-ing
- Generating Test Code (Boilerplate). Often test code needs to connect to a library, or hit an API end-point, or drive a browser, click a button. These things are supposed to be easy, but for some reason they are not. We get stuck. Because they scrape the web looking for examples and create an in-memory tokenized lookup table, Large Language Models may be able to generate the code to do these things for us. When we started our research, we expected to get stuck, because selenium IDE, webdriver, webdriver 2.0, etc, use so much different setup/install/code. Yet our examples of open-source boilerplate using classic websites such as Google and Amazon worked almost out-of-the-box. Google’s Bard can access today’s internet, so in theory you could generate boilerplate for your own website. In practice, we found that as of today, Bard does not look at websites – it can only look at classic sites and search results. For websites outside of the few largest public ones, Bard appears to “fake it”, suggesting code that doesn’t work. For example, it suggested select_element_by_xpath for FireFox, which is not currently implemented, and it suggested the app connect to the :name attribute of “search_button” – which is not the correct locator for the search button on the Excelon Development Homepage.
- Generating models (test oracles) given requirements. Often software has to perform complex calculations. One strategy to get it is to model-drive it. That is, create another piece of software that takes the same variables and spits out an answer. Then run both together given the same input, and compare the answers. The second piece of software, called the “Oracle”, can be much more crude. The models the software generates are invariably buggy, but a programmer armed with a for-loop can write code to find the differences between the two, which can be the source of a good conversation. Note this does not replace traditional testing as much as augments it.
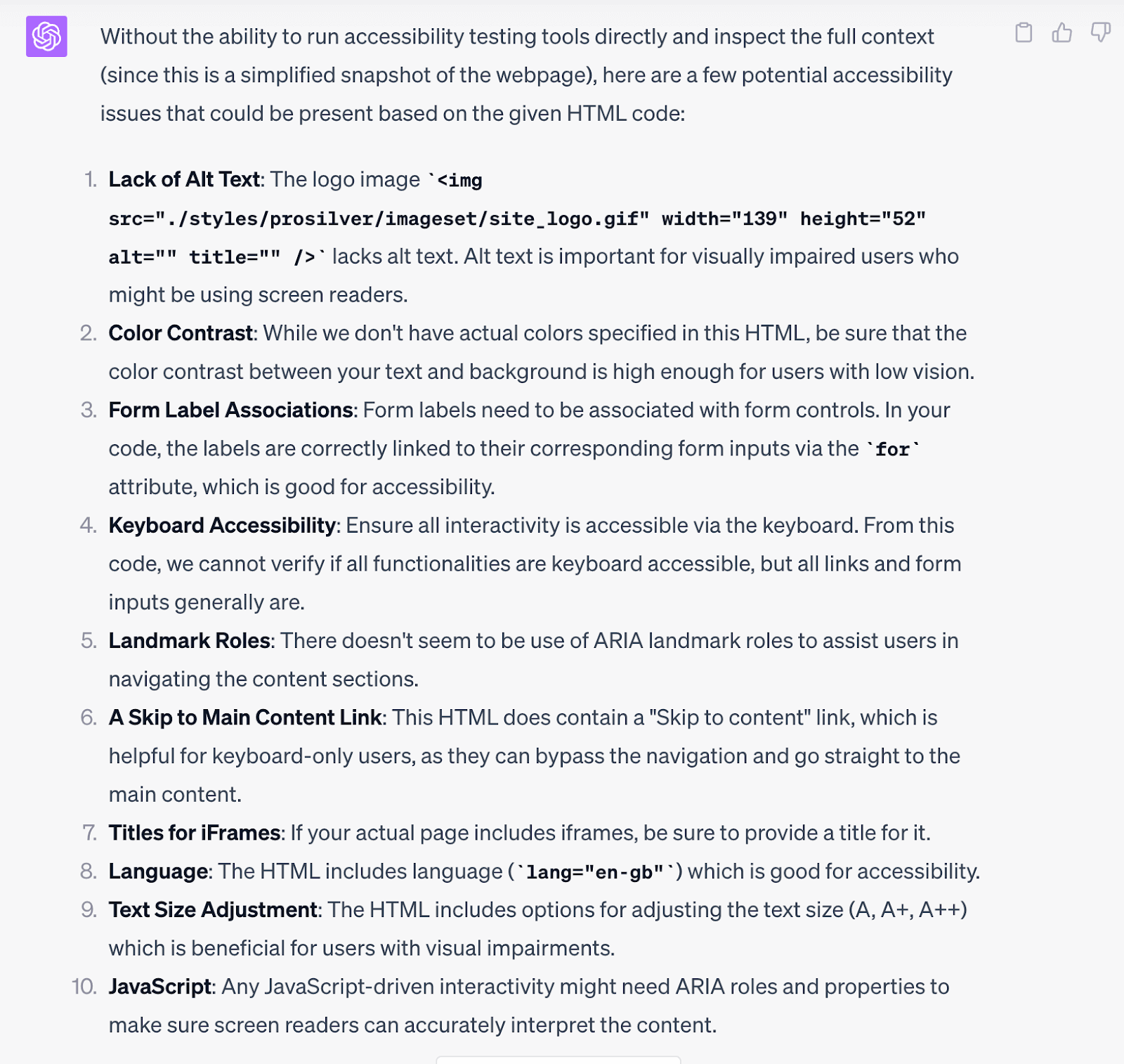
- Finding Accessibility problems. Although Bard does not access direct web pages, we found that we could paste HTML sections as long as it was short enough and did not have complex javascript that manipulated the web page structure. The advice that ChatGPT4 generated mixed general advice with a bit of specific advice, listing examples that were actual form fields from that web page. The Bard advice was relatively generic, but did contain accessibility flaws the web page had. (We used the login form for php bb, such as apachefriends.org)
 Note
NoteYou can use LambdaTest Cloud to test on a variety of iPhone simulators and real iPhone devices. No need to install anything, just sign up for a free account and start testing. Try LambdaTest Today!
If you wish to learn more about AI Automation you can read our hub for more insights
Summary/Conclusions
Andy Hird, a software tester in Cleveland, Ohio (who is as of now running for the board of the Association for Software Testing), pointed out that there is a difference between using AI to generate test ideas and data, and relying on it to generate expected results. In other words, if you feed these tools you code, get tests back, cut/paste, save and run, you deserve the result you’ll likely get. Wouter Lagerweij, another friend from consulting, believes that few technical staff are comfortable working in the tight test-code-refactor feedback loops that Test Driven Development (TDD) and BDD requires. Generative AI, especially AI in the development environment such as Github’s CoPilot, can work to fill in that gap – but you’ll have to double check it.,
The great benefit of using these tools for stub code is that they can get us past that “stuck” point where we just can’t figure out why a few lines of code aren’t working, for example to launch a browser or click a button. That “stuck” point might change two lines of code and cost an hour or four. Ironically, when I tried to have the tools generate simple code for the roman numeral kata, the code contained an off-by-one index error, accessing an array outside of bounds and causing a crash. Debugging and fixing it took about two hours – and two lines of code – about half as long as it would take to write from scratch. Blake Link, a developer with Excelon Development, reports a 90% reduction in “boilerplate” code generation.
We realize the two data points above unravel each other. And yet, here we are. Our goal was neither to tell you AI is an amazing solution, nor to “debunk” anything. Instead, we wanted to do a broad, detailed analysis of generative AI for testing, to push the conversation, research, and application in the field a half-inch forward.
For now, it’s probably best to look for these tools as the sources of test ideas and to generate template code to drive events. Tools already exist to generate synthetic test data, for accessibility testing, for combinatorial ideas. The power of LLMs is less in doing that work, and more in making programmatic sense of unstructured natural language.
That’s just the opinions of a few of us, plus a few experiments and a little more experience. What do you think? Where can you use generative AI for testing? More importantly, where are you using it right now?
Let’s keep talking.



Author’s Profile
Matt Heusser
As the Managing Director of Excelon Development, Matt Heusser, consults, trains, and does software delivery while helping others do it. Probably best known for his writing, Matt is the lead editor of "How to Reduce The Cost of Software Testing" (Taylor and Francis, 2011), editor for Stickyminds.com, and recipient of the 2015 Most Popular Online Contributor to Agile at the Agile Awards. A 2014 recipient of the Most Influential Agile Test Professional Person Award (MAITPP) in Potsdam, Germany, Matt also served as the lead organizer of the Software Testing World Cup. He is a former member of the board of directors of the Association for Software Testing and creator of Lean Software Testing family of methods.
Blogs: 6
Got Questions? Drop them on LambdaTest Community. Visit now













