How to Use XPath in Selenium [XPath Tutorial]
Vipul Gupta
Posted On: October 30, 2025
25 Min



The reliability of your test scripts depends on how consistently you can identify and interact with the right web elements, even as the application changes. XPath in Selenium plays a major role in this. It provides a flexible way to navigate through HTML and XML structures, helping you locate elements when other locators like ID, Name, or Class fall short.
Overview
XPath in Selenium is a query language used to locate elements in an XML or HTML document. It helps testers find web elements precisely when automating browser actions.
What Are the Types of XPath in Selenium?
XPath in Selenium is divided into Absolute and Relative types. Each serves a unique role depending on how stable or dynamic your application’s structure is.
- Absolute XPath: Defines the full path from the root element to the target node using a single slash (/). It’s simple but breaks easily when the page structure changes. Best for static pages or quick debugging.
- Relative XPath: Begins from any node using double slashes (//), making it flexible and resilient to DOM updates. It supports conditions, attributes, and functions, making it ideal for dynamic web applications.
How to Write XPath in Selenium?
XPath in Selenium is used to locate web elements when basic locators like ID or Class aren’t enough. It lets you define precise conditions using attributes, text, or structural relationships.
Syntax:
//tag[@attribute=’value’]
Example:
driver.findElement(By.xpath(“//input[@id=’username’]”));
Chapters
- What Is Selenium
- What is Selenium Used For?
- Selenium IDE
- Selenium RC
- Selenium WebDriver
- Selenium Grid
- Selenium 4
- Cross Browser Testing in Selenium
- Selenium Locators
- Selenium Wait
- XPath in Selenium
- Alerts in Selenium
- Selenium Java Tutorial
- Selenium Python Tutorial
- Selenium JavaScript Tutorial
- Selenium C# Tutorial
- Selenium PHP Tutorial
- Robot Class in Selenium
- Selenium Stealth Mode
- Selenium Proxy
- Challenges In Selenium Automation
- Testing Scenarios Not to Automate With Selenium
- Selenium Best Practices
TABLE OF CONTENTS
- What Is XPath in Selenium?
- Why XPath Is Important
- Types of XPath
- Write XPath in Selenium
- Common XPath Patterns
- Logical Operators in Selenium XPath
- XPath Axes in Selenium
- Chained XPath in Selenium
- Create Dynamic XPath in Selenium
- Use LambdaTest Online Selenium Grid for Scalable Automation
- Best Practices for Using XPath
- Common XPath Issues and Troubleshooting
What Is XPath in Selenium?
XPath (XML Path Language) is a query language used to navigate and locate nodes in XML and HTML documents. In Selenium automation, XPath help you locate elements inside the Document Object Model (DOM) based on their attributes, relationships, or text content.
When an element doesn’t have a unique ID or predictable structure, XPath gives you the flexibility to locate it using combinations of conditions. For example, you can target an element based on partial attribute matches, relative positioning, or even its displayed text. This flexibility makes XPath one of the most commonly used and reliable Selenium locators in real-world test automation.
Syntax:
|
1 |
//tagname[@attribute='value'] |
Here is an example of using XPath to locate a button element on a webpage.
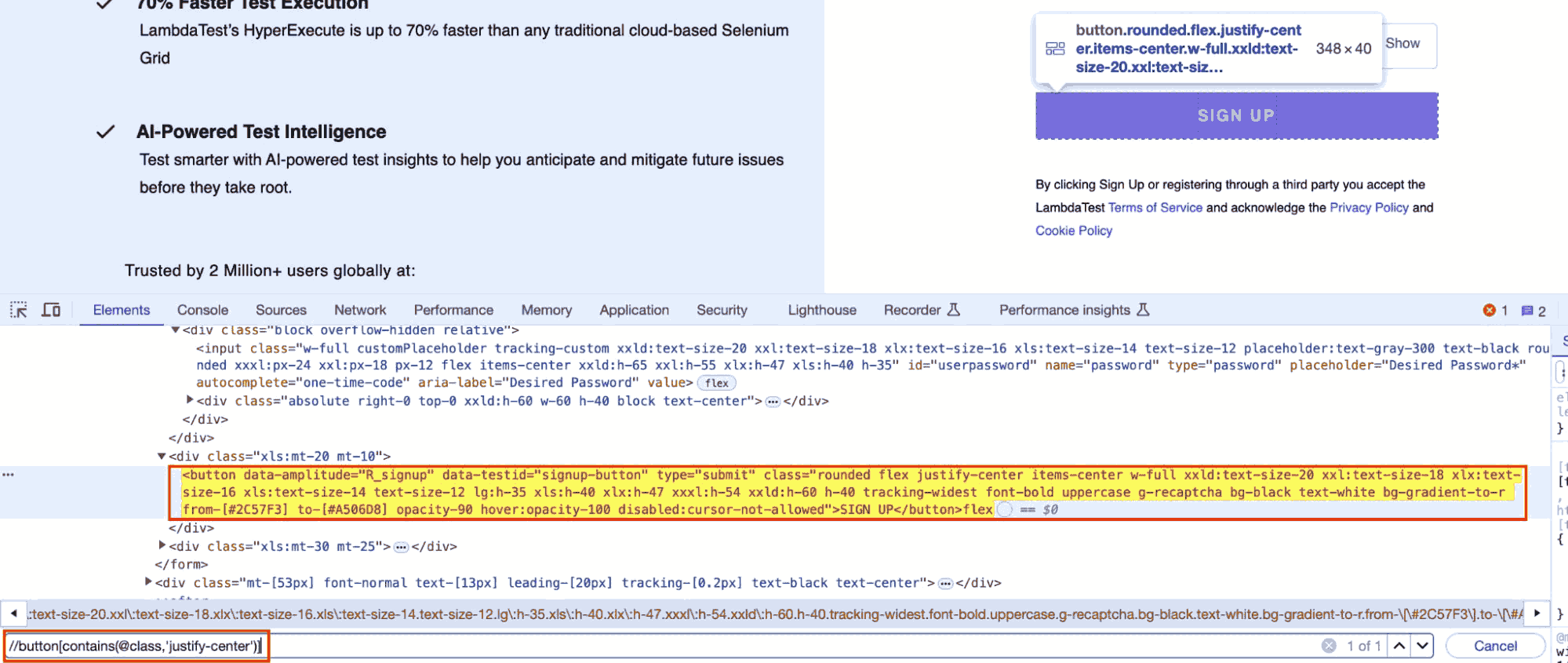
The highlighted SIGN UP button in the screenshot has a class attribute that includes justify-center.
|
1 |
//button[contains(@class, 'justify-center')] |
This XPath selects the button element whose class attribute includes the text justify-center.
For instance, it would match the SIGN UP button in the HTML code since that button’s class list contains justify-center.
Why XPath Is Important in Selenium?
XPath in Selenium is important for handling unstable identifiers, layout changes, and context-based element location.They also help with dynamic or nested structures, and advanced logic like conditional or partial attribute matching in complex web applications.
- Unstable Identifiers: You need to identify elements without consistent IDs, names, or classes, and XPath provides flexible expressions for targeting them reliably.
- Frequent Layout Changes: When page structures change often, XPath’s relative paths ensure your locators remain stable instead of breaking like absolute element references.
- Context-Based Location: You can locate elements relative to nearby components, such as labels, siblings, or containers, enabling more natural and maintainable test logic.
- Dynamic or Nested Elements: XPath efficiently handles dynamic, deeply nested, or component-based elements that standard locators struggle to access or identify correctly.
- Advanced Logic Support: XPath enables conditional matching, partial attribute searches, and parent-child traversal, making it ideal for complex and data-driven web applications.
What Are Types of XPath in Selenium?
In Selenium, XPath expressions are mainly categorized into two types: Absolute XPath and Relative XPath. Both serve different purposes, and choosing the right one depends on your application’s stability and structure.
- Absolute XPath
- Relative XPath
Absolute XPath
Absolute XPath provides the complete path from the root element (<>) to the target element. It follows every node in the hierarchy, which makes it straightforward but fragile. Any structural change in the DOM, even adding a new div, can break it.
Syntax:
|
1 |
/html/body/div[1]/form/input[2] |
Characteristics:
- Starts with a single forward slash (/), which indicates the path begins at the root.
- Easy to understand but not suitable for dynamic or frequently updated pages.
- Typically used for small static pages where the DOM doesn’t change.
It is recommended not to rely heavily on Absolute XPath in test suites that run against modern web apps. Even minor UI tweaks can invalidate multiple locators.
Relative XPath
Relative XPath starts from any node within the DOM rather than from the root. It uses double slashes (//) to search anywhere in the document, making it far more flexible and maintainable.
Syntax:
|
1 |
//input[@type='email'] |
Characteristics:
- Starts with //, which means the search can begin anywhere in the DOM.
- Works with dynamic or frequently updated elements.
- Allows use of functions, text content, and attribute combinations.
Relative XPath is preferred in almost all Selenium frameworks. It adapts to changes better, can be combined with conditions, and is easier to maintain in large test suites.
Always use Relative XPath in production test code. If you need to debug or verify an element’s structure, start with Absolute XPath to understand the hierarchy, then refine it into a Relative one.
 Note
NoteRun automation tests using various browsers and platforms. Try LambdaTest Today!
How to Write XPath in Selenium?
You use XPath in Selenium to locate elements on a webpage. Write it as //tag[@attribute=’value’]. For example: driver.findElement(By.xpath(“//input[@id=’username’]”));. It supports absolute and relative paths.
When you work on complex web applications, you often encounter elements that cannot be uniquely identified using standard locators like ID or Class. XPath lets you define conditions that describe exactly what you’re looking for. These conditions can be based on attributes, text, partial matches, or relationships with other elements.
A good XPath expression is both specific enough to locate a single element and resilient to minor DOM changes. The best way to write XPath is to start simple and refine it as needed.
Basic Structure:
|
1 |
XPath = //tagname[@attribute='value'] |
Example:
Consider a login page with two buttons:
|
1 2 |
<button type="submit">Login</button> <button type="button">Cancel</button> |
If you use the XPath //button[@type=’submit’], Selenium will identify the Login button, since it’s the only one with type=”submit”.
You can then use it in your Selenium script like this:
|
1 2 |
WebElement loginButton = driver.findElement(By.xpath("//button[@type='submit']")); loginButton.click(); |
What Are Common XPath Patterns in Selenium?
You use common XPath patterns in Selenium to find elements easily. These include single and multiple attribute matches, text-based selection, partial attribute matching for dynamic values, and parent-child navigation within the page.
Let’s break down some key XPath expressions you’ll use frequently in Selenium automation.
- XPath Using Single Attribute: It finds an element based on a single, unique attribute. This approach is stable and simple, especially when the attribute remains consistent across different DOM structures and updates.
- XPath Using Multiple Attributes: It combines more than one attribute using the and operator for better accuracy. It reduces ambiguity when multiple elements share similar properties or structures.
- XPath Using Text: It selects elements based on visible text content. Often used for buttons, links, or labels, this approach is simple and effective when the text is unique.
- XPath Using Partial Attribute Match: It uses the contains() function to locate elements when attributes are partially known. Ideal for handling dynamic attributes that change slightly between sessions or builds.
- XPath Using Parent-Child Relationships: It navigates through structured layouts to locate nested elements within containers. Useful when elements are grouped inside parent sections like forms, modals, or cards.
Example:
|
1 |
//input[@id='password'] |
Example:
|
1 |
//input[@type='text' and @name='username'] |
Example:
|
1 |
//button[text()='Login'] |
Example:
|
1 |
//input[contains(@name, 'user')] |
Example:
|
1 |
//div[@class='form-container']//input[@type='email'] |
What Are XPath Functions in Selenium?
You use XPath functions in Selenium to handle dynamic or structured elements. contains() matches partial attribute values, useful for changing IDs. starts-with() finds attributes with fixed prefixes, and text() selects elements by visible content.
- contains(): It is used when attribute values change partially or dynamically. It helps locate elements by matching partial strings. Ideal for frameworks like React or Angular-driven DOM structures.
- starts-with(): It is used to find elements whose attributes begin with a predictable prefix. Best for auto-generated IDs or fields that follow naming patterns like “user_101” or “user_202”.
- text(): It locates elements using visible text content. Works well for static UI labels, buttons, or menu items but fails with dynamic or localized text variations during testing.
Example:
|
1 |
//input[contains(@id,'email')] |
Example:
|
1 |
//input[starts-with(@name,'user')] |
Example:
|
1 |
//a[text()='Forgot Password?'] |
What Are Logical Operators in Selenium XPath?
XPath supports logical operators like and, or, and not() to refine or exclude conditions, ensuring flexible, precise, and adaptable locators across different automation scenarios.
- and: It combines multiple conditions to match elements only when all are true. Ensures targeted selection for elements requiring strict matching of multiple attributes simultaneously.
- or: It matches elements that satisfy either of the listed conditions. Useful for identifying components across UI variations or fallback attributes that differ between environments.
- not: It excludes elements that meet certain criteria. Useful when filtering hidden fields, ads, or inactive inputs to focus only on visible, actionable web elements.
Example:
|
1 |
//input[@type='text' and @name='username'] |
Example:
|
1 |
//input[@type='submit' or @name='login'] |
Example:
|
1 |
//input[not(@type='hidden')] |
What Are XPath Axes in Selenium?
XPath axes help navigate related elements in the DOM when attributes aren’t sufficient. They’re vital for dynamic UIs where element identifiers change frequently across builds.
- following: It selects all nodes appearing after the current element in the document. Ideal for locating input fields following labels or sequential items in structured forms and tables.
- following-sibling: It finds elements at the same hierarchy level that come after the current node. Commonly used for locating adjacent fields, containers, or validation messages beside labels.
- preceding: It retrieves all nodes before the current element. Helpful when targeting inputs or sections appearing before a recognizable reference point such as a button or heading element.
- preceding-sibling: It selects sibling nodes located before the current element. Perfect for associating error messages, hints, or labels that appear immediately before related interactive fields.
- child: It targets direct child elements of a specific parent node. Frequently used for working with lists, menu items, or table rows that share one immediate container.
- parent: It moves one level up from the current element to its parent container. Useful when accessing wrapper divs around inputs, labels, or grouped form components.
- descendant: It selects all nested child nodes under the current element. Ideal for identifying elements deep within hierarchies, like inputs inside forms or tables within modals.
- ancestor: It moves upward through the DOM to find parent elements at any level. Commonly used to identify containing forms or panels for deeply nested elements.
Example:
|
1 |
//label[text()='Password']//following::input[1] |
Example:
|
1 |
//div[@class='field-label']//following-sibling::div |
Example:
|
1 |
//button[@id='submit']//preceding::input[@type='password'] |
Example:
|
1 |
//div[@class='error-message']//preceding-sibling::label |
Example:
|
1 |
//ul[@class='menu']//child::li |
Example:
|
1 |
//input[@id='email']//parent::div |
Example:
|
1 |
//div[@class='user-section']//descendant::input[@type='text'] |
Example:
|
1 |
//input[@id='username']//ancestor::form |
What Is Chained XPath in Selenium?
Chained XPath in Selenium lets you locate nested elements. It links multiple XPath queries through parent-child paths, helping you narrow the search instead of selecting elements directly from the root.
This approach is especially helpful when:
- Multiple elements share similar attributes or classes.
- The element you want is deeply nested inside a specific section of the web page.
- You want your XPath to remain stable even if unrelated parts of the DOM change.
In a chained XPath, you start by locating a parent or container element, and then you move down to the child element inside it using the double slash //.
Syntax:
|
1 |
//parentTag[@attribute='value']//childTag[@attribute='value'] |
Example:
Suppose you have the following HTML:
|
1 2 3 4 5 |
<div class="signup-section"> <form> <input id="email" type="text" placeholder="Enter your email"> </form> </div> |
To locate the email input field inside the div with class signup-section, you can write:
|
1 |
//div[@class='signup-section']//input[@id='email'] |
How to Create Dynamic XPath in Selenium?
You create Dynamic XPath in Selenium to handle changing attributes or DOM shifts. Use functions like contains() or starts-with(), combine logical operators, apply axes for structure-based navigation, and use wildcards for flexibility.
Here are the ways using which you can create dynamic XPath:
Use XPath Functions
Functions like contains(), starts-with(), and text() handle variable attributes effectively. They keep locators reliable when identifiers change slightly across builds or runtime sessions.
Example:
|
1 |
//button[contains(@class, 'submit')] |
Combine Logical Operators
Merge multiple conditions with and or or for adaptability. Ensures element identification remains stable when one attribute changes or becomes optional.
Example:
|
1 |
//input[@type='email' or @name='userEmail'] |
Use Axes for Structural Flexibility
Axes allow element discovery through structural relationships instead of static paths. This keeps locators valid even when sibling or surrounding nodes are added dynamically.
Example:
|
1 |
//label[text()='Password']//following::input[1] |
Leverage Indexes Carefully
Indexing helps select specific elements among multiple matches but should be used sparingly. Changing DOM order may break indexed locators in future builds.
Example:
|
1 |
//div[@class='row']//input[2] |
Wildcards for Tag Flexibility
When tag names vary or are uncertain, use wildcards (*). They ensure locators focus on reliable attributes instead of unstable or framework-generated tag names.
Example:
|
1 |
//*[@data-testid='login'] |
Pro-Tip: To learn more about XPath, follow this XPath locator cheat sheet to learn and use all the various ways of locating WebElement efficiently, making your automation testing process faster.
XPath vs CSS Selectors: When to Choose Which?
When automating tasks like web scraping or testing, identifying the right elements on a webpage is essential. Two of the most common methods for locating elements are XPath and CSS Selectors. Each has its benefits, depending on the scenario.
| Criteria | XPath | CSS Selectors |
|---|---|---|
| Best for | Complex or irregular HTML structures. | Simple, consistent HTML layouts. |
| Navigation | Can move both up and down the DOM tree (parent, sibling, child). | Can only move down the DOM (child elements). |
| Text Matching | Can select elements based on text content. | Cannot match text directly. |
| Performance | Slightly slower in most browsers. | Generally faster and optimized in browsers. |
| Readability | More verbose and harder to read. | Cleaner and easier to understand. |
| Use in XML | Fully compatible with XML and namespaces. | Limited to HTML/CSS environments. |
| Common Use Cases | Web scraping, complex data extraction. | UI testing, front-end automation, quick selectors. |
| Support | Widely supported in automation tools like Selenium. | Natively supported and optimized by browsers. |
For an in-depth comparison, check out this guide on XPath vs CSS Selectors.
Why Use LambdaTest Online Selenium Grid for Scalable Automation?
Cloud based testing platforms such as LambdaTest offers scalable online Selenium Grid to execute Selenium automation tests across thousands of real browser and operating system combinations on demand.
You can run Selenium tests without maintaining any local infrastructure. This approach significantly streamlines setup, accelerates cross‑browser coverage, and reduces overall test execution time.
To get started, check out this guide on Selenium testing with LambdaTest.
Features:
- Parallel Test Execution at Scale: Execute hundreds of Selenium tests concurrently across multiple browsers and operating systems to drastically reduce testing time. Ideal for large test suites.
- Comprehensive Debugging with Logs & Video Playback: Capture full execution details – Selenium logs, network logs, step-by-step screenshots, and video recordings to debug faster and build reliable bug reports.
- Test Insights: Leverage GenAI-native test insights to gain visibility into test trends with an interactive dashboard that shows execution timelines, pass/fail rates, environment breakdowns, and more.
- CI/CD Integration: Integrate effortlessly with tools like Jenkins, GitHub Actions, Azure DevOps for seamless test automation.
Best Practices for Using XPath in Selenium
To write stable and efficient Selenium scripts, using XPath the right way is crucial.
Below are key best practices that you can follow to handle XPath efficiently.
- Prefer Relative XPath Over Absolute XPath: Use relative XPath (//) instead of absolute paths (/html/body/…) to make your locators more resilient to UI changes.
- Use Unique Attributes: Target attributes like id, name, or custom data-* when available to create stable and specific locators.
- Use contains() for Partial Matching: When dealing with dynamic attribute values, use the contains() function to match partial values.
- Use text() to Match Visible Text: If the element’s visible text is consistent and unique, use the text() function to locate it.
- Combine Multiple Conditions: Make your XPath more specific by combining conditions using and or or.
- Use starts-with() for Matching Dynamic Prefixes: For attributes that begin with a consistent prefix, use the starts-with() function.
- Avoid Index-Based XPath When Possible: Using indexes like (//div[@class=’item’])[3] is fragile. DOM changes can break your test.
- Use XPath Axes When Necessary: Axes like following-sibling::, parent::, or ancestor:: help target elements in complex DOMs.
- Keep XPath Short and Readable: Write concise expressions that are easy to read and maintain. Avoid deeply nested or overly complex paths.
- Validate XPath Using Browser DevTools: Use tools like XPath tester or Chrome DevTools with $x(“your_xpath”) to test and validate XPath expressions before using them in scripts.
- Leverage Custom Data Attributes: Prefer data-testid, data-role, or other data-* attributes as they are designed for automation.
- Write Contextual Locators: Use nearby stable elements, like labels, to anchor your XPath reliably.
Common XPath Issues and How to Troubleshoot?
Here are some common XPath issues in Selenium and how to troubleshoot them.
-
Invalid or Malformed XPath: Syntax errors like missing brackets, unclosed quotes, wrong axes, or stray characters.
-
XPath Matches Nothing: The element may not be present in the live DOM (e.g., inside iFrame, Shadow DOM, or is loaded dynamically).
-
XPath Returns Multiple Elements: The XPath is too broad or lacks specific filters.
-
Dynamic Attributes (IDs, Classes): Attributes change between sessions or page loads.
-
Element Inside Shadow DOM or Custom Elements: Standard XPath can’t access elements inside shadow DOM.
-
XPath Works in Browser but Not in Code: Possible timing issue or unhandled frame context.
-
Case Sensitivity and Typos: XPath is case-sensitive; even small mismatches can break it.
Fix: Use browser DevTools or tools like SelectorsHub to validate and correct your XPath.
Fix: Check for iframes using browser DevTools. Use JavaScript like document.querySelector or $x() in console. Add proper waits using WebDriverWait.
Fix: Use indexes like (//div[@class=’item’])[1] or add more conditions such as //div[@class=’item’ and @data-id=’123′].
Fix: Use partial match functions like contains() or starts-with(). Example: //div[contains(@class, ‘btn’)].
Fix: Use JavaScript like element.shadowRoot.querySelector(). Consider tools like Playwright which handle shadow DOM better.
Fix: Wait for elements using explicit waits. Make sure to switch to the correct iframe using driver.switchTo().frame(…).
Fix: Double-check tag names and attributes. Test XPath directly using $x(‘your_xpath’) in browser console.
Conclusion
You’ve now seen how XPath works in Selenium, from the basics to advanced techniques like axes and dynamic locators. We also looked at how to handle specific elements like loaders and how to follow best practices for writing reliable XPath expressions.
To scale your automation, you can use LambdaTest online Selenium Grid. It helps you run tests in parallel, debug faster, and cover multiple browser-OS combinations without managing infrastructure.
Frequently Asked Questions (FAQs)
What is XPath?
XPath helps you locate elements in XML or HTML using structure. You use it with tags, attributes, or text to target nodes. It’s commonly used in automation, like Selenium. Think of it as a precise way to find things on a web page.
Why use XPath?
Use XPath when elements don’t have unique IDs or are nested. It gives you flexibility to locate based on attributes or text. XPath works even when the structure is complex or dynamic. It’s powerful for advanced test automation.
How to find XPath in Chrome?
Right-click the element and choose Inspect to open DevTools. Then right-click the HTML code and select Copy > Copy XPath. Paste it into your test or script to use it. This gives you a full path to that element.
How to write XPath?
Use the format //tagname[@attribute=’value’] to create basic paths. You can also use contains(), text(), or logical conditions. Combine multiple filters to get accurate matches. Always test your XPath in DevTools.
How to find XPath?
Inspect the element in Chrome DevTools and right-click its HTML. Choose Copy XPath to grab its locator. You can also refine it for stability. Use $x(‘your_xpath’) in Console to verify.
How to find XPath of an element?
Open DevTools and inspect the element. Right-click its HTML and choose Copy XPath. You can paste it in your script or validate it with $x(). This helps in writing reliable test cases.
What is XPath syntax in Selenium?
XPath in Selenium uses expressions like //tag[@attr=’value’]. You can use functions like contains() or axes like following. Double slashes (//) mean relative path. It’s powerful for locating dynamic elements.
How to use XPath?
Use XPath to find elements based on structure, text, or attributes. Start with //tagname[@attr=’value’] and build from there. It helps when IDs or class names aren’t unique. It’s widely used in testing and web scraping.
What is XPath in HTML?
XPath helps you select HTML elements using tag names, attributes, or position. It’s useful when IDs aren’t available or consistent. XPath works well in test scripts and scraping. Think of it as a flexible way to find HTML nodes.
How to use contains() method in XPath?
Use contains() to match partial values inside an attribute or text. Example: //input[contains(@placeholder, ‘Email’)]. It’s useful when values change dynamically. This adds flexibility to your locators.
How to write XPath for text?
Use //tagname[text()=’Exact Text’] for exact match. For partial matches, use contains(text(), ‘keyword’). It helps when text is visible but elements lack good attributes. Text-based XPath is useful in many UIs.
What is XPath injection?
XPath injection is a security flaw caused by unvalidated user input in queries. Attackers can manipulate XPath to access data. Always sanitize input in XPath expressions. It’s similar to SQL injection but for XML or HTML.
What is XPath axes in Selenium?
Axes let you navigate from one node to another like parent, sibling, or child. Examples include following, preceding, and ancestor. Use them when direct attributes don’t help. They give you powerful navigation control.
What is XPath in XML?
XPath helps you query and locate elements in XML documents. You can filter by tag, attribute, or node structure. It’s used in parsing, validation, and configuration files. XPath works the same in HTML and XML.
What is the difference between static and dynamic XPath?
Static XPath uses fixed paths and exact values, like //div[@id=’menu’]. Dynamic XPath uses functions like contains() or wildcards. Use dynamic XPath when elements or attributes change. It’s more robust for modern web apps.
Citations
- XPath Wikipedia: https://en.wikipedia.org/wiki/XPath
Author
Vipul Gupta is a Sr. Lead SDET at Zupee with over 9 years of experience in functional and automation testing. He has built 10+ automation projects from scratch covering web, API, and mobile applications. Vipul is skilled in Selenium, Appium, Rest Assured, Playwright, Java, Python, Pytest, BDD, TDD, Maven, Jenkins, TestNG, and JUnit. He has successfully led end-to-end QA efforts, including setting up teams from scratch and managing a 15-member QA team to ensure manual and automation testing run in parallel from day one. Vipul graduated in B.Tech CSE from CGC College of Engineering and is followed by 3,000+ QA and SDET professionals on LinkedIn, reflecting his strong influence in the testing community.
Blogs: 24











