How To Find Broken Links Using Selenium WebDriver?
Himanshu Sheth
Posted On: December 18, 2020
![]() 107806 Views
107806 Views
![]() 22 Min Read
22 Min Read
What thoughts come to mind when you come across 404/Page Not Found/Dead Hyperlinks on a website? Aargh! You would find it annoying when you come across broken hyperlinks, which is the sole reason why you should continuously focus on removing the existence of broken links in your web product (or website). Instead of a manual inspection, you can leverage automation for broken link testing using Selenium WebDriver.

When a particular link is broken and a visitor lands on the page, it affects that page’s functionality and results in a poor user experience. Dead links could hurt your product’s credibility, as it ‘might’ give an impression to your visitors that there is a minimal focus on the experience.
If your web product has many pages (or links) that result in a 404 error (or page not found), the product rankings on search engines (e.g., Google) will also be badly affected. Removal of dead links is one of the integral parts of SEO (Search Engine Optimization) activity.
In this part of the Selenium WebDriver tutorial series, we deep dive into finding broken links using Selenium WebDriver. We have demonstrated broken link testing using Selenium Python, Selenium Java, Selenium C#, and Selenium PHP.
Starting your journey with Selenium WebDriver? Check out this step-by-step guide to perform Automation testing using Selenium WebDriver. If you’re looking to improve your Selenium interview skills, check out our curated list of Selenium interview questions and answers.
TABLE OF CONTENT
Introduction to Broken Links in Web Testing
In simple terms, broken links (or dead links) in a website (or web app) are links that are not reachable and do not work as anticipated. The links could be temporarily down due to server issues or wrongly configured at the back end.
Apart from pages that result in 404 error, other prominent examples of broken links are malformed URLs, links to content (e.g., documents, pdf, images, etc.) that have been moved or deleted.
Prominent Reasons for Broken Links
Here are some of the common reasons behind the occurrence of broken links (dead links or link rots):
- Incorrect or misspelled URL entered by the user.
- Structural changes in the website (i.e., permalinks) with URL redirects or internal redirects are not properly configured.
- Links to content like videos, documents, etc. that are either moved or deleted. If the content is moved, the ‘internal links’ should be redirected to the designated links.
- Temporary website downtime due to site maintenance making the website temporarily inaccessible.
- Broken HTML tags, JavaScript errors, incorrect HTML/CSS customizations, broken embedded elements, etc., within the page leading, can lead to broken links.
- Geolocation restrictions prevent access to the website from certain IP addresses (if they are blacklisted) or specific countries in the world. Geolocation testing with Selenium helps ensure that the experience is tailor-made for the location (or country) from where the site is accessed.
Why should you check Broken Links?
Broken links are a big turn-off for the visitors who land on your website. Here are some of the major reasons why you should check for broken links on your website:
- Broken Links can hurt the user experience.
- Removal of broken (or dead) links is essential for SEO (Search Engine Optimization), as it can affect the site’s rankings on search engines (e.g., Google).
Broken links testing can be done using Selenium WebDriver on a web page, which in turn can be used to remove the site’s dead links.
Broken Links and HTTP Status Codes
When a user visits a website, a request is sent by the browser to the site’s server. The server responds to the browser’s request with a three-digit code called the ‘HTTP Status Code.’
An HTTP Status Code is the server’s response to a request sent from the web browser. These HTTP Status Codes are considered equivalent to the conversation between the browser (from which URL request is sent) and the server.
Though different HTTP Status Codes are used for different purposes, most of the codes are useful for diagnosing issues in the site, minimizing site downtime, the number of dead links, and more. The first digit of every three-digit status code begins with numbers 1~5. The status codes are represented as 1xx, 2xx.., 5xx for indicating the status codes in that particular range. As each of these ranges consists of a different class of server response, we would limit the discussion to HTTP Status Codes presented for broken links.
Here are the common status code classes that are useful in detecting broken links with Selenium:
| Classes of HTTP Status Code | Description |
|---|---|
| 1xx | The Server is still thinking through the request. |
| 2xx | The request sent by the browser was successfully completed and expected response was sent to the browser by the server. |
| 3xx | This indicates that a redirect is being performed. For example, 301 redirect is popularly used for implementing permanent redirects on a website. |
| 4xx | This indicates that either a particular page (or complete site) is not reachable. |
| 5xx | This indicates that the server was unable to complete the request, even though a valid request was sent by the browser. |
HTTP Status Codes presented on detection of Broken Links
Here are some of the common HTTP Status Codes presented by the web server on encountering a broken link:
| HTTP Status Code | Description |
|---|---|
| 400 (Bad Request) | The server is unable to process the request as the mentioned URL is incorrect. |
| 400 (Bad Request – Bad Host) | This indicates that the host name is invalid due to which the request cannot be processed. |
| 400 (Bad Request – Bad URL) | This indicates that the server cannot process the request as the entered URL is malformed (i.e. missing brackets, slashes, etc.). |
| 400 (Bad Request – Timeout) | This indicates that the HTTP requests have timed out. |
| 400 (Bad Request – Empty) | The response returned by the server is empty with no content and no response code. |
| 400 (Bad Request – Reset) | This indicates that the server is unable to process the request, as it is busy in processing other requests or it has been misconfigured by the site owner. |
| 403 (Forbidden) | A genuine request is sent to the server but it is refusing to fulfill the same, as authorization is required. |
| 404 (Page Not Found) | The resource (or the page) is not available on the server. |
| 408 (Request Time Out) | The server has timed-out waiting for the request. The client (i.e. browser) can send the same request within the time that the server is prepared to wait. |
| 410 (Gone) |
An HTTP Status Code that is more permanent than 404 (Page Not Found). 410 means that the page is Gone. The page is neither available on the server, nor any forwarding (or redirection) mechanism has been set up. The links pointing to a 410 page are sending visitors to a dead resource. |
| 503 (Service Unavailable) | This indicates that the server is temporarily overloaded, due to which it cannot process the request. It can also mean that maintenance is being carried out at the server, indicating the search engines about the site’s temporary downtime. |
How to Find Broken Links Using Selenium WebDriver?
Irrespective of the language used with Selenium WebDriver, the guiding principles for broken link testing using Selenium remains the same. Here are the steps for broken links testing using Selenium WebDriver:
- Use the < a > tag to collect details of all the links present on the webpage.
- Send an HTTP request for every link.
- Verify the corresponding response code received in response to the request sent in the previous step.
- Validate whether the link is broken or not based on the response code sent by the server.
- Repeat steps (2-4) for every link present on the page.
In this Selenium WebDriver tutorial, we would demonstrate how to perform broken link testing using Selenium WebDriver in Python, Java, C#, and PHP. The tests are conducted on (Chrome 85.0 + Windows 10) combination, and the execution is carried out on the cloud-based Selenium Grid provided by LambdaTest.
To get started with LambdaTest, create an account on the platform and note the user-name & access-key available from the profile section on LambdaTest. The browser capabilities are generated using LambdaTest Capabilities Generator.
Here is the test scenario used for finding broken links on a website using Selenium:
Test Scenario
- Go to LambdaTest Blog i.e. https://www.lambdatest.com/blog/ on Chrome 85.0
- Collect all the links present on the page
- Send HTTP request for each link
- Print whether the link is broken or not on the terminal
It is important to note that the time spent in broken links testing using Selenium depends on the number of links present on the ‘web page under test.’ The more the number of links on the page, the more time will be spent finding broken links. For example, LambdaTest has a huge number of links (~150+); hence, the process of finding broken links might take some time (approx a few minutes).

RUN YOUR TESTING SCRIPT ON SELENIUM GRID
2000+ Browsers AND OS
Broken Link Testing Using Selenium Java
Implementation
Code WalkThrough
1. Import the required packages
The methods in the HttpURLConnection package are used for sending HTTP requests and capturing the HTTP Status Code (or response).
The methods in the regex.Pattern package check if the corresponding link contains an email address or telephone number using a specialized syntax held in a pattern.
|
1 2 |
import java.net.HttpURLConnection; import java.util.regex.Pattern; |
2. Collect the links present on the page
The links present on the URL under test (i.e., LambdaTest Blog) are located using tagname in Selenium. The tag name used for identification of the element (or link) is ‘a’.
The links are placed in a list to iterate through the list to check broken links on the page.
|
1 |
List<WebElement> links = driver.findElements(By.tagName("a")); |
3. Iterate through the URLs
The Iterator object is used for looping through the list created in Step (2)
|
1 |
Iterator<WebElement> link = links.iterator(); |
4. Identify and Verify the URLs
A while loop is executed till the time Iterator (i.e., link) does not have more elements to iterate. The ‘href’ of the anchor tag is retrieved, and the same is stored in the URL variable.
|
1 2 3 |
while (link.hasNext()) { url = link.next().getAttribute("href"); |
Skip checking the links if:
a. The link is null or empty
|
1 2 3 4 5 |
if ((url == null) || (url.isEmpty())) { System.out.println("URL is either not configured for anchor tag or it is empty"); continue; } |
b. The link contains mailto or telephone number
|
1 2 3 4 5 |
if ((url.startsWith(mail_to)) || (url.startsWith(tel))) { System.out.println("Email address or Telephone detected"); continue; } |
When checking for the LinkedIn page, the HTTP status code is 999. A Boolean variable (i.e., LinkedIn) is set to true to indicate that it is not a broken link.
|
1 2 3 4 5 |
if(url.startsWith(LinkedInPage)) { System.out.println("URL starts with LinkedIn, expected status code is 999"); bLinkedIn = true; } |
5. Validate the links through the Status Code
The methods in HttpURLConnection class provide the provision for sending HTTP requests and capturing the HTTP Status Code.
The openConnection method of the URL class opens the connection to the specified URL. It returns a URLConnection instance representing a connection to the remote object that is referred by the URL. It is type-casted to HttpURLConnection.
|
1 2 3 4 5 6 7 |
HttpURLConnection urlconnection = null; .............................................. .............................................. .............................................. urlconnection = (HttpURLConnection) (new URL(url).openConnection()); urlconnection.setRequestMethod("HEAD"); |
The setRequestMethod in HttpURLConnection class sets the method for URL request. The request type is set to HEAD so that only Headers are returned. On the other hand, request type GET would have returned the document body, which is not required in this particular test scenario.
The connect method in HttpURLConnection class establishes the connection to the URL and sends an HTTP request.
|
1 |
urlconnection.connect(); |
The getResponseCode method returns the HTTP Status Code for the previously sent request.
|
1 |
responseCode = urlconnection.getResponseCode(); |
For HTTP Status Code is 400 (or more), the variable containing broken links count (i.e., broken_links) is incremented; else, the variable containing valid links (i.e., valid_links) is incremented.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
if (responseCode >= 400) { if ((bLinkedIn == true) && (responseCode == LinkedInStatus)) { System.out.println(url + " is a LinkedIn Page and is not a broken link"); valid_links++; } else { System.out.println(url + " is a broken link"); broken_links++; } } else { System.out.println(url + " is a valid link"); valid_links++; } |
Execution
For broken links testing using Selenium Java, we created a project in IntelliJ IDEA. The basic pom.xml file was sufficient for the job!
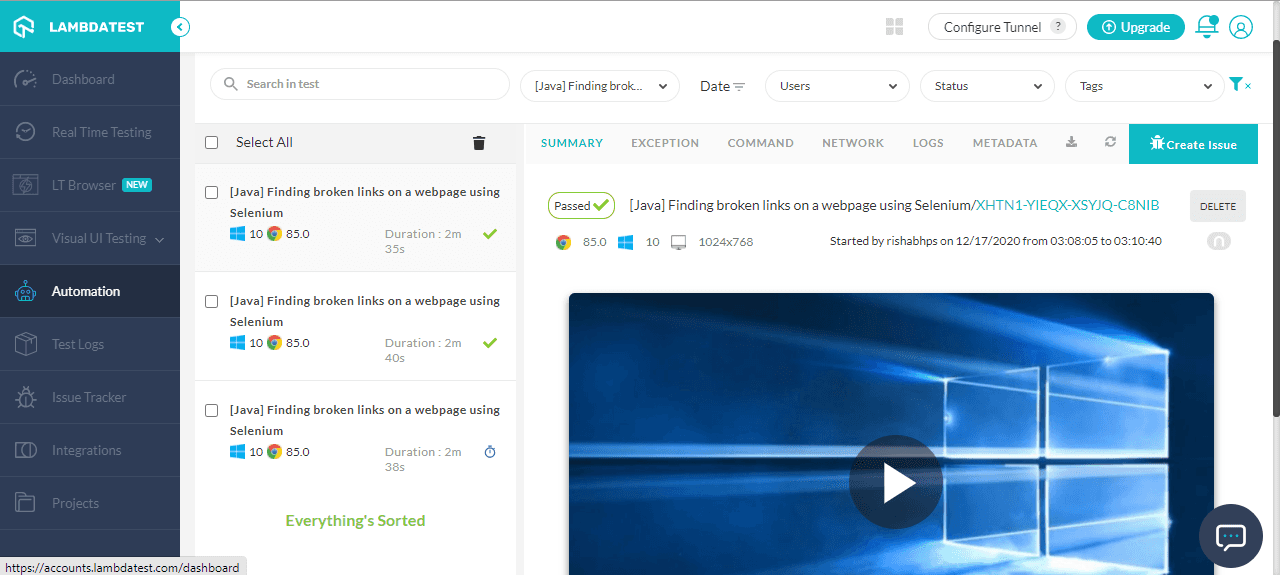
Here is the execution snapshot, which indicates 169 valid links and 0 broken links on the LambdaTest Blog Page.
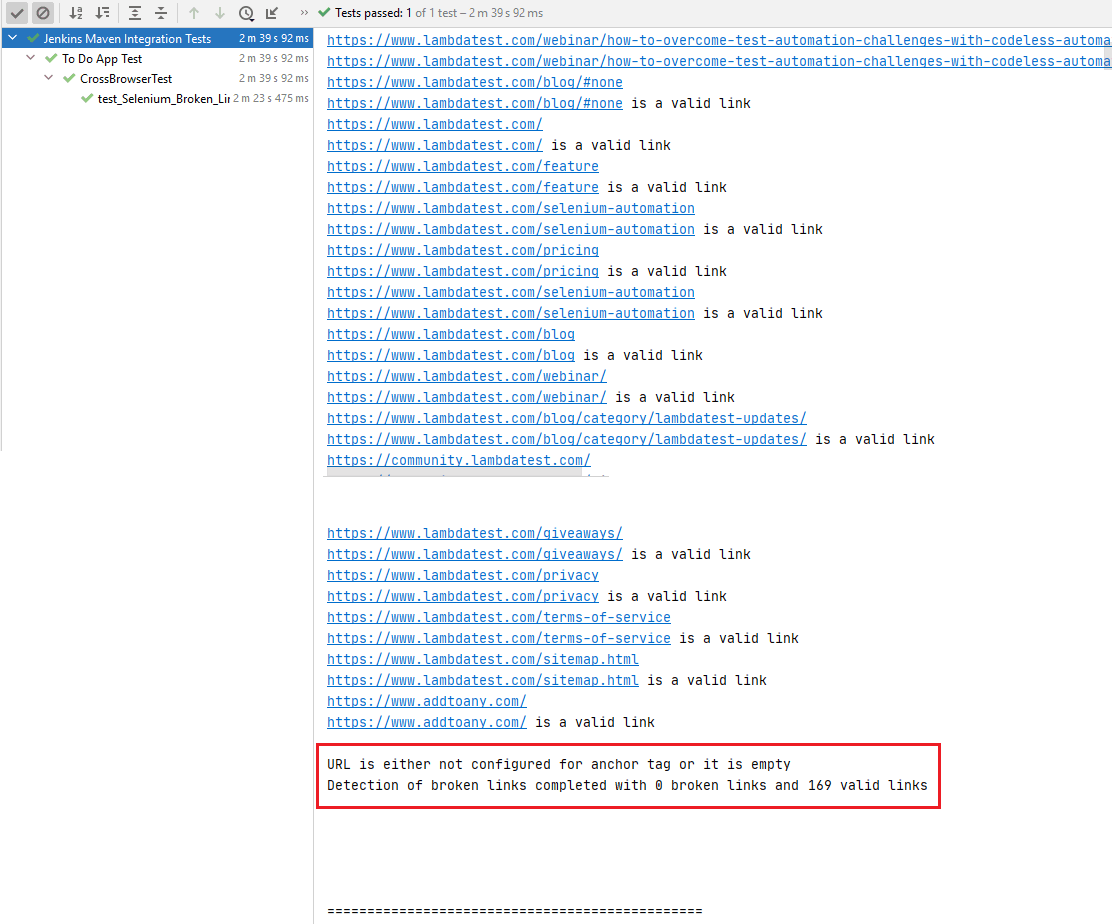
The links containing the email addresses and phone numbers were excluded from the search list, as shown below.
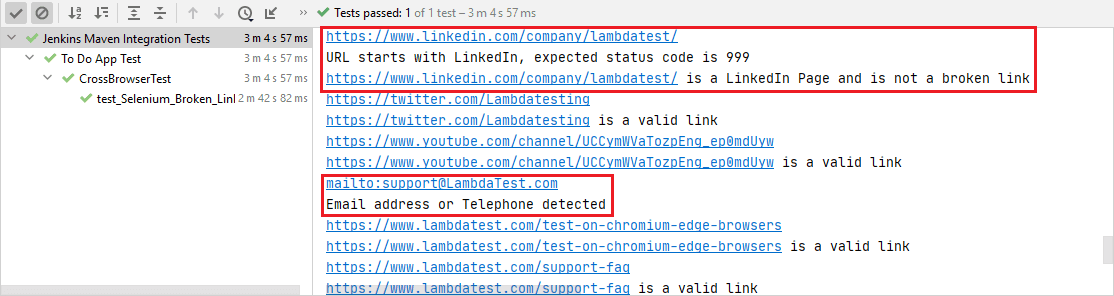
You can see the test being run in the below screenshot and getting completed in 2 min 35 seconds, as shown on LambdaTest’s automation logs.
Broken Link Testing Using Selenium Python
Implementation
Code WalkThrough
1. Import Modules
Apart from importing the Python modules for Selenium WebDriver, we also import the requests module. The requests module lets you send all kinds of HTTP requests. It can also be used for passing parameters in URL, sending custom headers, and more.
|
1 2 3 |
import requests import urllib3 from requests.exceptions import MissingSchema, InvalidSchema, InvalidURL |
2. Collect the links present on the page
The links present on the URL under test (i.e., LambdaTest Blog) are found by locating the web elements by the CSS Selector “a” property.
|
1 |
links = driver.find_elements(By.CSS_SELECTOR, "a") |
Since we want the element to be iterable, we use the find_elements method (and not the find_element method).
3. Iterate through the URLs for validation
The head method of the requests module is used to send a HEAD request to the specified URL. The get_attribute method is used on every link for getting ‘href’ attribute of the anchor tag.
The head method is primarily used in scenarios where only status_code or HTTP headers are required, and contents of the file (or URL) are not needed. The head method returns requests.Response object which also contains the HTTP Status Code (i.e. request.status_code).
|
1 2 3 4 |
for link in links: try: request = requests.head(link.get_attribute('href'), data ={'key':'value'}) print("Status of " + link.get_attribute('href') + " is " + str(request.status_code)) |
The same set of operations are performed iteratively till all the ‘links’ present on the page have been exhausted.
4. Validate the links through the Status Code
If the HTTP response code for the HTTP request sent in step(3) is 404 (i.e., Page Not Found), it means that the link is a broken link. For links that are not broken, the HTTP Status Code is 200.
|
1 2 3 4 |
if (request.status_code == 404): broken_links = (broken_links + 1) else: valid_links = (valid_links + 1) |
5. Skip irrelevant requests
When applied on links that do not contain the ‘href’ attribute (e.g., mailto, telephone, etc.), the head method results in an exception (i.e., MissingSchema, InvalidSchema).
|
1 2 3 4 5 6 |
except requests.exceptions.MissingSchema: print("Encountered MissingSchema Exception") except requests.exceptions.InvalidSchema: print("Encountered InvalidSchema Exception") except: print("Encountered Some other execption") |
These exceptions are caught, and the same is printed on the terminal.
Execution
We have used the PyUnit (or unittest) here, the default test framework in Python for broken links testing using Selenium. Run the following command on the terminal:
|
1 |
python Broken_Links.py |
The execution would take around 2-3 minutes since the LambdaTest Blog page consists of approximately 150+ links. The execution screenshot below shows that the page has 169 valid links and zero broken links.
You would witness the InvalidSchema exception or MissingSchema exception at some places, which indicates that those links are skipped from the evaluation.
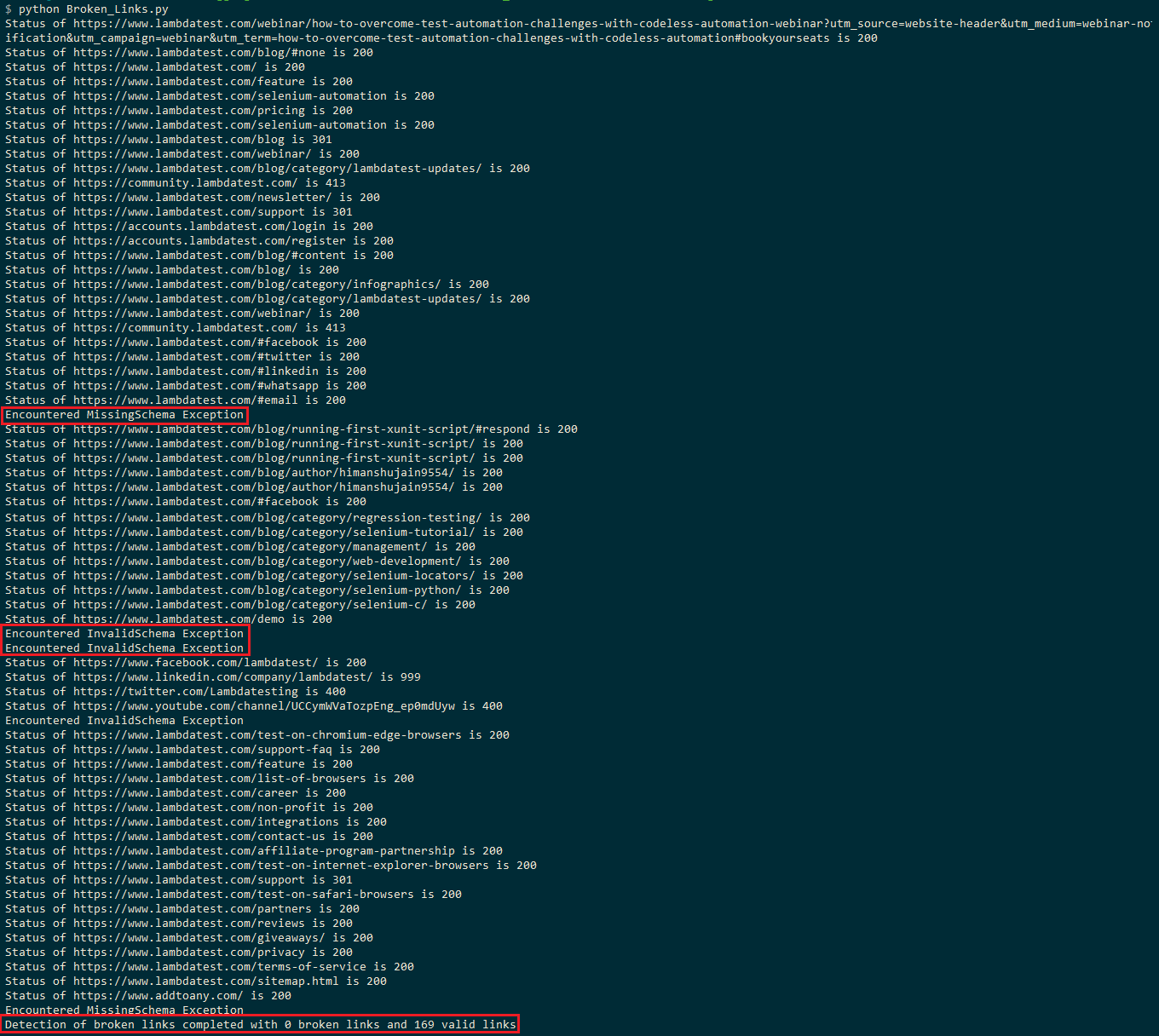
The HEAD request to LinkedIn (i.e.) results in an HTTP Status Code of 999. As stated in this thread on StackOverflow, LinkedIn filters the requests based on the user-agent, and the request resulted in ‘Access Denied’ (i.e., 999 as HTTP Status Code).

We verified whether the LinkedIn link present on the LambdaTest blog page is broken or not by running the same test on the local Selenium Grid, which resulted in HTTP/1.1 200 OK.
Broken Link Testing Using Selenium C#
Implementation
Code WalkThrough
The NUnit framework is used for automation testing; our earlier blog on NUnit Test automation with Selenium C# can help you get started with the framework.
1. Include HttpClient
The HttpClient namespace is added for usage through the using directive. The HttpClient class in C# provides a base class for sending HTTP requests and receiving the HTTP response from a resource that is identified by URI.
Microsoft recommends using System.Net.Http.HttpClient instead of System.Net.HttpWebRequest; HttpWebRequest could also be used to detect broken links in Selenium C#.
|
1 2 |
using System.Net.Http; using System.Threading.Tasks; |
2. Define an async method that returns a task
An async test method is defined as using the GetAsync method that sends a GET request to the specified URI as an asynchronous operation.
|
1 2 |
public async Task LT_Broken_Links_Test() { |
3. Collect the links present on the page
Firstly, we create an instance of HttpClient.
|
1 |
using var client = new HttpClient(); |
The links present on the URL under test (i.e., LambdaTest Blog) are collected by locating the web elements by the TagName “a” property.
|
1 |
var links = driver.FindElements(By.TagName("a")); |
The find_elements method in Selenium is used for locating the links on the page as it returns an array (or list) that can be iterated to verify the workability of the links.
4. Iterate through the URLs for validation
The links located using the find_elements method are verified in a for loop.
|
1 2 |
foreach (var link in links) { |
We filter the links that contain /email-addresses/telephone numbers/LinkedIn addresses. The links with no Link Text are also filtered out.
|
1 2 |
if (!(link.Text.Contains("Email") || link.Text.Contains("https://www.linkedin.com") || link.Text == "" || link.Equals(null))) { |
The GetAsync method of HttpClient class sends a GET request to the corresponding URI as an asynchronous operation. The argument to the GetAsync method is the value of the anchor’s ‘href’ attribute collected using the GetAttribute method.
The evaluation of the async method is suspended by the await operator until the completion of the asynchronous operation. On completion of the asynchronous operation, the await operator returns the HttpResponseMessage that includes the data and status code.
|
1 2 3 |
/* Get the URI */ HttpResponseMessage response = await client.GetAsync(link.GetAttribute("href")); System.Console.WriteLine($"URL: {link.GetAttribute("href")} status is :{response.StatusCode}"); |
5. Validate the links through the Status Code
If the HTTP response code (i.e. response.StatusCode) for the HTTP request sent in step(4) is HttpStatusCode.OK (i.e., 200), it means that the request was completed successfully.
|
1 2 3 4 5 6 7 8 9 |
System.Console.WriteLine($"URL: {link.GetAttribute("href")} status is :{response.StatusCode}"); if (response.StatusCode == HttpStatusCode.OK) { valid_links++; } else { broken_links++; } |
NotSupportedException and ArgumentNullException exceptions are handled as a part of exception handling.
|
1 2 3 4 5 6 7 8 |
catch (Exception ex) { if ((ex is ArgumentNullException) || (ex is NotSupportedException)) { System.Console.WriteLine("Exception occured\n"); } } |
Execution
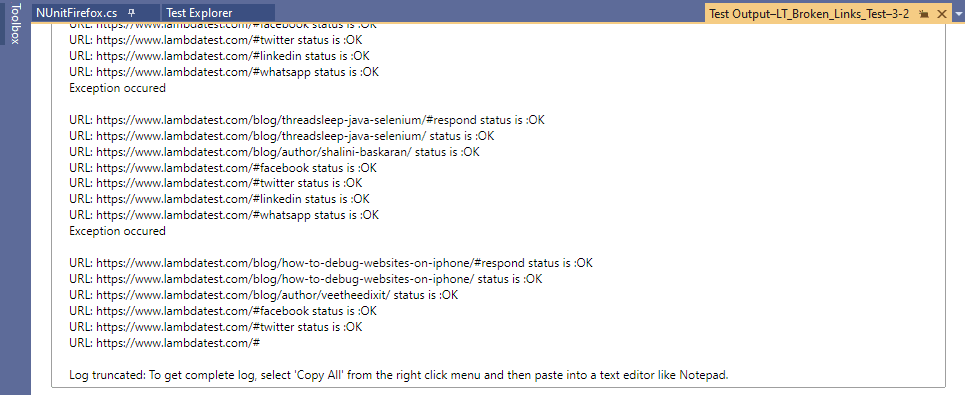
Here is the execution snapshot, which shows that the test was executed successfully.

Exceptions have occurred for links to the ‘share icons,’ i.e., WhatsApp, Facebook, Twitter, etc. Apart from these links, the rest of the links on the LambdaTest blog page return HttpStatusCode.OK (i.e. 200).
Broken Link Testing Using Selenium PHP
Implementation
Code WalkThrough
1. Read the page source
The file_get_contents function in PHP is used for reading the page’s HTML source into a String variable (e.g. $html).
|
1 2 |
$test_url = "https://www.lambdatest.com/blog/"; $html = file_get_contents($test_url); |
2. Instantiate the DOMDocument class
The DOMDocument class in PHP represents an entire HTML document and serves as the document tree’s root.
|
1 |
$htmlDom = new DOMDocument; |
3. Parse HTML of the page
The DOMDocument::loadHTML() function is used for parsing the HTML source that is contained in $html. On successful execution, the function returns a DOMDocument object.
|
1 |
@$htmlDom->loadHTML($html); |
4. Extract the links from the page
The links present on the page are extracted using the getElementsByTagName method of DOMDocument class. The elements (or links) are searched based on the ‘a’ tag from the parsed HTML source.
The getElementsByTagName function returns a new instance of DOMNodeList which contains the elements (or links) of local tag name (i.e. < a > tag)
|
1 |
$links = $htmlDom->getElementsByTagName('a'); |
5. Iterate through the URLs for validation
The DOMNodeList, which was created in Step (4), is traversed for checking the validity of the links.
|
1 2 3 |
foreach($links as $link) { $linkText = $link->nodeValue; |
The details of the corresponding link are obtained using the ‘href’ attribute. The GetAttribute method is used for the same.
|
1 |
$linkHref = $link->getAttribute('href'); |
Skip checking the links if:
a. The link is empty
|
1 2 3 4 |
if(strlen(trim($linkHref)) == 0) { continue; } |
b. The link is a hashtag or an anchor link
|
1 2 3 4 |
if($linkHref[0] == '#') { continue; } |
c. The link contains mailto or addtoany (i.e., social sharing options).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
function check_nonlinks($test_url, $test_pattern) { if (preg_match($test_pattern, $test_url) == false) { return false; } else { return true; } } public function test_Broken_Links() { $pattern_1 = '/\baddtoany\b/'; $pattern_2 = '/\bmailto\b/'; .................................................................... .................................................................... .................................................................... if ((check_nonlinks($linkHref, $pattern_1))||(check_nonlinks($linkHref, $pattern_2))) { print("\nAdd_To_Any or email encountered"); continue; } .................................................................... .................................................................... .................................................................... } |
preg_match function uses a regular expression (regex) for performing a case-insensitive search for mailto and addtoany. The regular expressions for mailto & addtoany are ‘/\bmailto\b/’ & ‘/\baddtoany\b/’ respectively.
6. Validate the HTTP Code using cURL
We use curl to get information regarding the status of the corresponding link. The first step is initializing a cURL session with the ‘link’ on which validation has to be done. The method returns a cURL instance that will be used in the latter part of the implementation.
|
1 |
$curl = curl_init($linkHref); |
The curl_setopt method is used for setting options on the given cURL session handle (i.e. $curl).
|
1 |
curl_setopt($curl, CURLOPT_NOBODY, true); |
The curl_exec method is called for execution of the given cURL session. It returns True on successful execution.
|
1 |
$result = curl_exec($curl); |
This is the most important part of the logic that checks for broken links on the page. The curl_getinfo function that takes the cURL session handle (i.e. $curl) and CURLINFO_RESPONSE_CODE (i.e. CURLINFO_HTTP_CODE) are used for getting information about the last transfer. It returns HTTP Status Code in response.
|
1 |
$statusCode = curl_getinfo($curl, CURLINFO_HTTP_CODE); |
On successful completion of the request, HTTP Status Code of 200 is returned, and the variable holding the valid links count (i.e., $valid_links) is incremented. For links that result in the HTTP Status Code of 400 (or more), a check is performed if the ‘link under test’ was LambdaTest’s, LinkedIn Page. As mentioned earlier, the LinkedIn page’s status code will be 999; hence, $valid_links is incremented.
For all the other links that returned HTTP Status Code of 400 (or more), the variable holding the broken links count (i.e., $broken_links) is incremented.
|
1 2 3 4 5 6 7 8 9 10 |
if (($linkedin_page_status) && ($statusCode == 999)) { print("\nLink " . $linkHref . " is LinkedIn Page and status is " .$statusCode); $validlinks++; } else { print("\nLink " . $linkHref . " is broken link and status is " .$statusCode); $brokenlinks++; } |
Execution
We use the PHPUnit framework for testing for broken links on the page. For downloading the PHPUnit framework, add the file composer.json in the root folder and run composer require on the terminal.
Run the following command on the terminal to check broken links in Selenium PHP.
|
1 |
vendor\bin\phpunit tests\BrokenLinksTest.php |
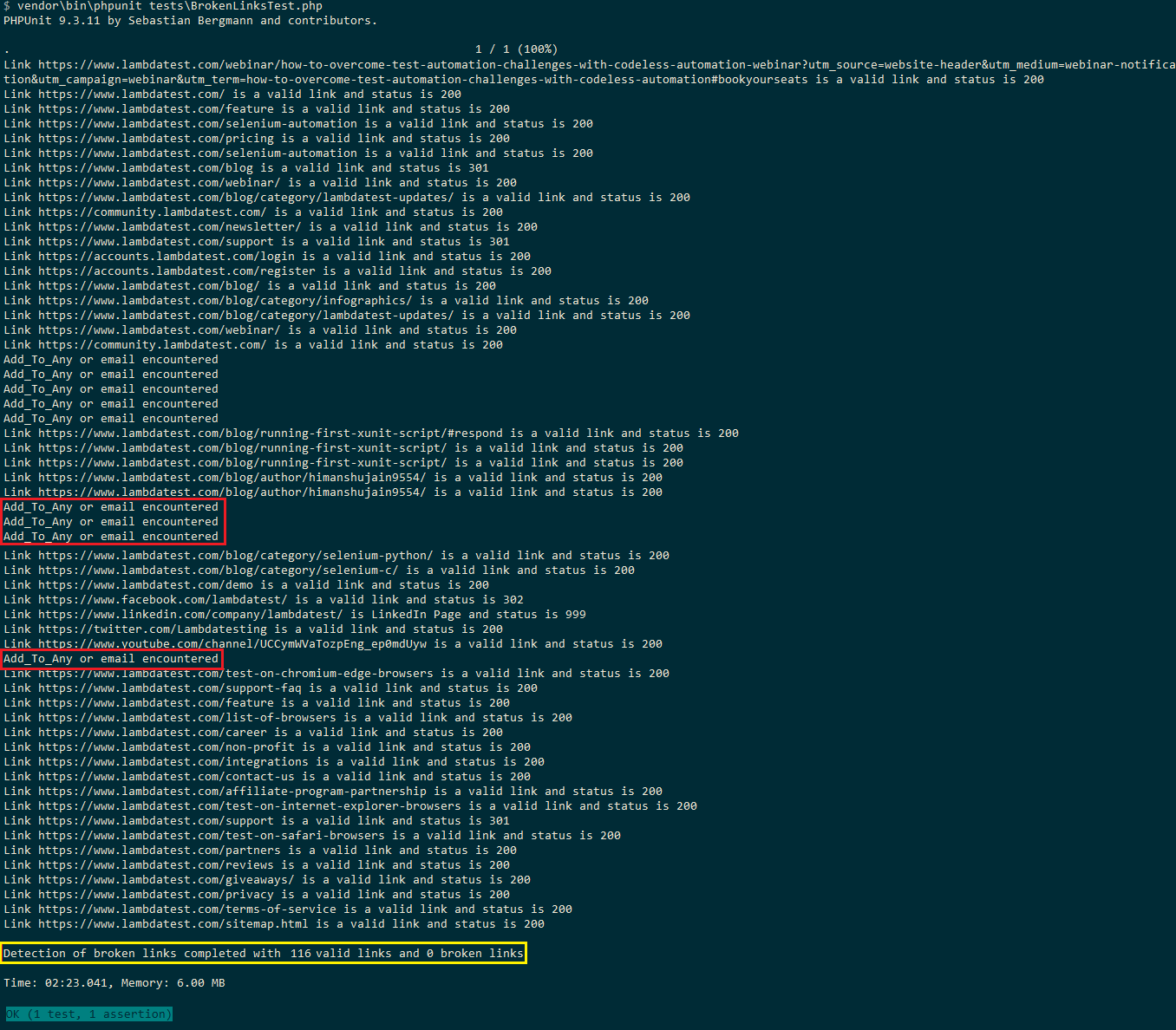
Here is the execution snapshot that shows a total of 116 valid links and 0 broken links on the LambdaTest Blog. As links for social sharing (i.e., addtoany) and email address are ignored, the total count is 116 (169 in the Selenium Python test).
Conclusion

Broken links, also called dead links or rot links, can hinder the user experience if they are present on the website. Broken links can also impact the rankings on search engines. Hence, broken link testing should be carried periodically for activities related to website development and testing.
Rather than relying on third-party tools or manual methods for checking broken links on a website, broken links testing can be done using Selenium WebDriver with Java, Python, C#, or PHP. The HTTP Status Code, returned when accessing any web page, should be used to check broken links using the Selenium framework.
Frequently Asked Questions
How do I find broken links in selenium Python?
For checking the broken links, you will need to collect all the links in the web page based on the < a > tag. Then send an HTTP request for the links and read the HTTP response code. Find out whether the link is valid or broken based on the HTTP response code.
How do I check for broken links?
To continuously monitor your site for broken links using Google Search Console, follow these steps:
- Log in to your Google Search Console account.
- Click the site you want to monitor.
- Click Crawl, and then click Fetch as Google.
- After Google crawls the site, to access the results click Crawl, and then click Crawl Errors.
- Under URL Errors, you can see any broken links that Google discovered during the crawl process.
How do I find broken images on the web using selenium?
Visit the page. Iterate through each image in the HTTP Archive and see if it has a 404 status code. Store each broken image in a collection. Check that the broken images collection is empty.
How do I get all the links in selenium?
You can get all the links present on a web page based on the <a> tag present. Each <a> tag represents a link. Use the selenium locators to find all such tags easily.
Why are broken links bad?
They can hurt the user experience – When users click on links and reach dead-end 404 errors, they get frustrated and may never return. They devalue your SEO efforts – Broken links restrict the flow of link equity throughout your site, impacting rankings negatively.


Author’s Profile
Himanshu Sheth
Himanshu Sheth is a seasoned technologist and blogger with more than 15+ years of diverse working experience. He currently works as the 'Lead Developer Evangelist' and 'Senior Manager [Technical Content Marketing]' at LambdaTest. He is very active with the startup community in Bengaluru (and down South) and loves interacting with passionate founders on his personal blog (which he has been maintaining since last 15+ years).
Blogs: 130
Got Questions? Drop them on LambdaTest Community. Visit now