Python Asyncio Tutorial: A Complete Guide
Himanshu Sheth
Posted On: October 4, 2024
![]() 298212 Views
298212 Views
![]() 52 Min Read
52 Min Read
Test execution time plays a key role in speeding up releases, especially when testing at scale. It largely depends on how well the test suites are designed, their ability to run tests concurrently, and the efficiency of the test infrastructure used.
When fetching build details for the last 500 tests, large API responses can delay execution. To avoid blocking other tasks, it’s ideal to run API calls asynchronously, improving overall test efficiency.
In this Python asyncio tutorial, we will dive deep into the nuances of asynchronous programming with Python using the asyncio (asynchronous I/O) library that was introduced in Python 3.4. The learnings of this Python asyncio tutorial will help you make the most of coroutines, tasks, and event loops for realizing concurrent execution.
TABLE OF CONTENTS
Note: Async IO, AsyncIO, and asyncio are used interchangeably throughout this Python asyncio tutorial.
What Is Asynchronous Programming in Python?
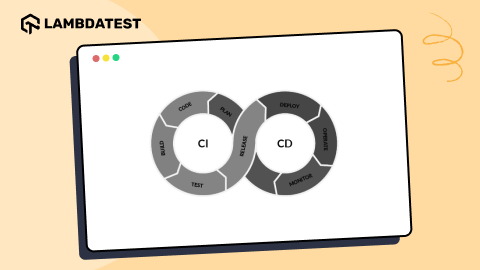
As the name indicates, asynchronous programming is an approach where different tasks can be executed concurrently. What this essentially means is that the main (or single) thread need not be blocked when other tasks are performing I/O operations, making HTTP requests, and more.

As seen in the image representation above, tasks waiting for I/O operations or network requests do not block the other tasks, thereby minimizing the idle time and reducing the overall execution time. The Python asyncio library allows concurrency by using coroutines that run in an event loop which itself executes in a single thread.
As stated in the official documentation of asyncio, the implementation of this library, which was previously called Tulip, is now a part of the Python standard library since Python 3.4. In case you are running a Python version earlier than 3.4 (which is not recommended), you can install the Python asyncio library by triggering the pip install asyncio command on the terminal.

Here are some of the use cases where asynchronous execution in Python asyncio can be highly beneficial:
- Web applications (e.g., streaming, e-commerce, etc.) that need to handle a large number of simultaneous requests
- Every web application that uses REST APIs that involve I/O operations (e.g., handling HTTP requests & responses)
- Web applications using the Microservices architecture, where asynchronous execution can help accelerate the handling of network calls, interacting with databases, and more.
In further sections of the Python asyncio tutorial, we will be deep-diving into the core concepts of the Python asyncio library, i.e., coroutines, event loops, tasks, and async/await syntax.
 Note
NoteRun Python asyncio tests across 3000+ real desktop browsers. Try LambdaTest Today!
Essentials of Python Asyncio
The async and await keywords form the fundamentals of asynchronous programming in Python via the Python asyncio library. With Python asyncio, a normal function (i.e., def function_name) becomes an asynchronous (or a coroutine) function using the async keyword (i.e., async def function_name).
The async def change lets the current function temporarily pause its execution while the execution of respective (e.g., I/O, network requests, etc.) operations is in progress.

The control is yield to the event loop when a coroutine (or task) encounters the await keyword or a coroutine awaits another coroutine or future. Let’s look at each of the components of the Python asyncio library in more detail!
Coroutines
In the context of the Python asyncio library, coroutines can be defined as functions that provide the flexibility to temporarily pause the execution of waiting tasks. This lets the other tasks execute concurrently while waiting for the completion of blocking time-consuming operations like I/O, network requests, file operations, database operations, etc.
In simple terms, the CPU is less utilized (or might be free) when I/O (or similar operations) are in progress. For instance, copying data to an external hard drive is an I/O operation where the CPU only initiates and accepts the I/O requests. The CPU can be better utilized in such cases for performing other tasks! The same rationale also applies to coroutines in the Python asyncio library.
A normal function in Python becomes a coroutine when it is defined with the async def syntax. Upon the usage of async def, the said function yields a coroutine object. When the await keyword is encountered, the current coroutine is paused, and the control is yielded back to the event loop.
The event loop continuously monitors the awaitable (e.g., coroutine, Task, a Future) until its completion. Once the execution of the awaitable or the newly picked-up task is complete, the event loop restores the execution of the paused coroutine.
It is important to note that coroutines do not make the code multi-threaded; rather coroutines run in an event loop that executes in a single thread.
Shown below is an example showcasing the usage of coroutine in Python:
The test_1() and test_2() are defined as asynchronous functions (or coroutines). During the execution of test_1(), an await keyword is encountered with an async sleep of 2 seconds. This pauses the coroutine and yields control back to the event loop.
With this, the execution of test_1() is paused until the completion of the test_2() coroutine. Post the execution of test_2(), the execution of test_1() coroutine is resumed and the return value of test_1 is printed on the terminal.

Lastly, the asyncio.run() is used for running the main coroutine until its completion. asyncio.run() also sets up the event loop, executes the coroutine, and closes the event loop when the main finishes.
Event Loop
Event loop in the Python asyncio library primarily manages the scheduling of asynchronous tasks, callbacks, I/O operations, and more. As stated earlier, the event loop manages and schedules asynchronous operations without blocking the main thread.
Since the event loop continuously runs, it monitors the awaitable (e.g., coroutine, Task, a Future) until its execution is complete. As soon as the await keyword is encountered, the current coroutine is temporarily paused, and the control is yield to the event loop.

Once the execution of the awaited task (or awaitable) is complete, the event loop resumes the execution of the paused routine. In a nutshell, the event loop in the Python asyncio library plays a pivotal role in catalyzing the asynchronous (or concurrent) execution of tasks.
Shown below is an example showcasing an event loop in Python:
A new event loop object is created using the new_event_loop() method of the Python asyncio library. As stated in this Stack Overflow Question, a new event loop creation is required if the event loop needs to run out of the main thread or a custom policy needs to be used in a single application.
This set_event_loop(loop) sets the newly created loop (named loop) as the current event loop. This ensures that the get_event_loop() method returns this loop. In case you encounter the DeprecationWarning: There is no current event loop warning, we would suggest going through this Stack Overflow thread for more information.
Shown below is the execution of the code, which indicates that the execution of the test_1() coroutine was paused when the await keyword was encountered in the code. Post the async sleep of 2 seconds, the second coroutine test_2() is executed till its completion. The total execution time is 4 seconds.

The close() method of the Python asyncio library closes the event loop (named loop) created earlier once all the tasks are completed. Next up, we see how we can further leverage the benefits of tasks in Python asyncio for running tasks at the event loop at the same time!
Tasks
So far, we have seen that the await keyword is used to suspend the execution of the current coroutine until the execution of the awaitable (could be coroutines, tasks, or futures) is complete. Hence, it is used for cooperative multitasking, whereby multiple coroutines can run parallel in a single-thread environment.
However, tasks are a more efficient way of managing the concurrent execution of coroutines. A task is a wrapper around a coroutine that is scheduled for execution by the event loop.
Though both sound very similar, there is a thin line of difference when you opt for tasks instead of merely using the await keyword!
As seen in the earlier example for Event Loop, the current coroutine [e.g., test_1()] yields the control back to the event loop once the await keyword is encountered in the coroutine. As soon as this occurs, the current coroutine is temporarily paused (or suspended), and the event loop picks up the next available coroutine/Task/Future (e.g., [e.g., test_2()] for execution. Once the execution of the awaited coroutine [i.e., test_2()] is complete, the suspended coroutine [i.e., test_1()] is resumed for execution.
However, tasks let you manage concurrent execution of the coroutines more efficiently. Unlike coroutines that are temporarily paused using await, tasks can start coroutines without waiting for them to complete. Tasks in the Python asyncio library let you run/schedule multiple coroutines concurrently on a single thread.
Let’s consider the earlier example where we have two coroutines – test_1() and test_2(). When converted into tasks, both tasks can run concurrently instead of one waiting for the other to complete execution. In a nutshell, tasks wrapping coroutines test_1() and test_2() not only run in tandem but the event loop is also able to utilize the CPU more efficiently!
Coroutines can be wrapped into a task by invoking the create_task() method, which returns a Task object. As stated in the official documentation, the wait_for() method of the Python asyncio library waits for the single Future (or coroutine) to complete with a timeout.
On a lighter note, tasks and await in the Python asyncio library are two sides of the same coin 
With await, control is transferred back to the event loop that schedules the next awaitable to be run. Though it does provide concurrency, there is still massive room for performance improvement!
This is where tasks come into the picture, as this wrapper around a coroutine lets you concurrently run multiple coroutines. The usage of tasks ups the overall efficiency of the Event Loop, thereby improving the performance & responsiveness of the code.
The example shown in the Event Loop section is ported in a manner where normal coroutines are converted into Tasks.
There are two simple coroutines test_1() and test_2(), where a sleep of 2 seconds is added in each of them. In main(), the two coroutines are wrapped as tasks by invoking the create_task(co_name) method of the Python asyncio library.
Now that the tasks are created, the await keyword [on the task wrapping test_1()] pauses the current coroutine and schedules the other task [wrapping test_2()]. Both tasks are scheduled to run instantly on the event loop at the same time.
The event loop can schedule other tasks during the sleep period. The execution time is 2 seconds (which was earlier 4 seconds) since task2 runs concurrently with task1.


Tasks should be prioritized over normal coroutines if there is no dependency (e.g. result of one coroutine used in the other one) between coroutines. Invoking multiple API requests (e.g., LambdaTest APIs) and clubbing the results, performing parallel I/O operations, logging data, and running background tasks are some of the scenarios where tasks should be preferred over coroutines.
On the whole, concurrent execution of tasks reduces the overall execution time along with improving the efficiency of the code.
Running tasks concurrently using asyncio.gather()
There could be scenarios where you would want a series of awaitables (e.g., tasks) to be executed concurrently, with the result being an aggregate list of the returned values. One such example is testing multiple API endpoints in a single go where the API response is aggregated in a list. Similarly, batch processing (i.e., extracting and processing data concurrently) is much more efficient using the asyncio.gather() method.
As stated in the official documentation, asyncio.gather() lets you run awaitable objects in the aws sequence concurrently.
All coroutines (i.e., aws) are automatically converted into tasks. The coroutines passed to the gather() method are executed concurrently, and the results are retrieved after the completion of all the coroutines.
In case two coroutines [e.g., coroutine_1() and coroutine_2()] are passed to the gather() method, they are first converted into tasks and executed concurrently. The return value is a list of execution results in the order of the original sequence, not necessarily the order of results arrival. return_exceptions parameter, which is False by default, lets you tweak the manner in which raised exceptions are handled during the gather operation. We will cover return_exceptions in more detail in the further sections of this Python asyncio tutorial.
Shown below is a port of the create_task() example which we demoed earlier. The two coroutines – coroutine_1() & coroutine_1() are inherently converted into tasks by the asyncio.gather() method.
The coroutines/tasks are scheduled and run concurrently by the gather() method of the Python asyncio library. The return value of the task(s) execution is captured in variables ret_info_1 & ret_info_2, respectively.
Apart from the gathering of tasks, the rest of the execution & test logic remains unchanged. The total execution time is 2 seconds even though the execution of both the concurrently-running coroutines was paused for 2 seconds using the asyncio.sleep() method.

To summarize, gather() in Python asyncio helps improve performance by reducing wait times, provides robust error handling & improved result collection in a list.
Handling Exceptions in asyncio.gather()
Exceptions could occur during the execution; either it could be an exception raised in one or more tasks, or it could be a task(s) that was canceled, raising the CancelledError exception. The manner in which exceptions are handled is controlled by the return_exceptions parameter in gather().
By default, return_exceptions is False, hence, any raised exception is propagated to the task that awaits on the gather(). In the below snippet, a list consisting of four coroutines is passed to gather(). Since return_exceptions is set to False, exceptions raised by any coroutine/task would be propagated to the next one, resulting in a cancellation of the said tasks (and other future awaitables).
In case an exception is raised in coroutine_1, it will be propagated to other tasks, thereby canceling all of them (i.e., coroutine_2, coroutine_3, and coroutine_4).
If return_exceptions is True, all the tasks (or coroutines) complete the execution, even if one or more tasks raise an unhandled exception. Exceptions raised, if any, are provided as a return value in the results list returned from gather().
Like the earlier scenario, coroutine_1 raises an exception. Since this time around return_exceptions is set to True, the assertion raised by coroutine_1 will be added to the return list, and all the other awaitables (i.e., coroutine_2, coroutine_3, and coroutine_4) will complete their execution.

In the below example, we have four coroutines which are passed as a list to the asyncio.gather() method. The coroutine_1() throws the ValueError exception, whereas the coroutine_2() throws the SystemError exception.
When return_exceptions in the gather() method is set to False, coroutine_1 raises ValueError, and all other tasks in the list – coroutine_2, coroutine_3, & coroutine_4 are canceled as the execution value is propagated to the tasks. The execution story is entirely different when return_exceptions is set to True. Here, all four coroutines complete the execution even though ValueError & SystemError are raised by coroutine_1 and coroutine_3, respectively.

With return_exceptions set to True, exceptions raised are provided as a return value in the list returned from the gather() method of the Python asyncio library.
Async/Await in Asyncio
We have used the async/await combination extensively throughout this Python asyncio tutorial! To put it in simple terms, async/await are the guiding pillars for realizing concurrent code execution using the Python asyncio library.
The async keyword converts a Python function into a coroutine, whereby the coroutine can be executed asynchronously. The async keyword returns a coroutine object that is run by the event loop.
What this essentially means is that the coroutine can momentarily pause its execution under the following circumstances:
- Waiting for I/O operations – making network requests, interacting with databases, and more.
- Waiting for external events – specific test conditions before proceeding with actions, monitoring & logging server-side issues, and more.
- Achieving better concurrency – yielding control to the event loop when there are waits (or sleep), running multiple coroutines using asyncio.gather()
Coroutines can pause their execution using the await keyword. The await keyword suspends the currently executing coroutine, and the control is yielded to the event loop. The suspend coroutine/task is again scheduled for execution when the awaitables (i.e. I/O, timer expiry, etc.) completes. With the current task suspended, the event loop now schedules and executes coroutines that are ready for execution.
Once the awaited task is completed, the earlier suspended coroutine resumes execution from the point where it was paused. Now that we have covered the major aspects of the Python asyncio library let’s look at an example that showcases the usage of async/await keywords in Python:
In the above example, we have two async functions:
| Test – Async Function (Coroutine) | Purpose |
|---|---|
| test_fetch_lambdatest_sessions() | Fetches details of the sessions of the tests executed on LambdaTest. |
| test_fetch_reddit_threads() | Fetches top Reddit threads matching certain topics using the API provided by Reddit. |
Let’s deep dive into the integral aspects of the code:
To get started, we import all the essential libraries & modules – pytest, asyncio, aiohttp, and others that are used for asynchronous programming, test execution, and more. Since the LambdaTest & Reddit APIs provide output in the JSON format, hence the json module is also imported into the code.
Since LambdaTest APIs are used in the tests, the user name & access key obtained from the LambdaTest Profile > Password & Security section are exposed as LT_USERNAME & LT_ACCESS_KEY environment variables, respectively.
There are four async functions (or coroutines) in the example, out of which two are helper functions used by the respective tests.
Coroutine 1 (Helper) : get_json()
The above coroutine fetches the data in a JSON format using the respective URL. First, we create a dictionary containing the accept header, which specifies that the client expects a response in the JSON format.
Next up, an asynchronous GET request to the specified URL (i.e., LambdaTest URL or Reddit API), including the headers.
The status variable of the response object indicates whether the request was successful or not. You can also get HTTP status code via Apache Client! Any response other than 200 means that the client’s request made to the server was not successful.
The read method of the response object returns the content of the response.
The try…except loop is used to catch or handle exceptions.
Coroutine 2 (Helper) : get_lambdatest_sessions()
This particular coroutine returns the meta-data related to test sessions for the tests executed on the LambdaTest platform. We are using the LambdaTest REST API for fetching session details for the last 40 tests executed on LambdaTest.
In order to use LambdaTest, you need to create an account and export the environment variables LT_USERNAME & LT_ACCESS_KEY mentioned earlier.
Since we need session information for only the last 40 sessions, the limit parameter in the LambdaTest sessions API is set to 40. LambdaTest user name & access key are appended to the URL for authentication purposes.
Next, the HTTP session object and constructed URL are supplied as input parameters to the get_session() coroutine that we discussed earlier. The get_session() coroutine returns the LambdaTest session meta-data in the JSON format.
Once we have the byte-encoded data, it is then decoded into a string of UTF-8 format. The loads() method of the json module parses the JSON string into a Python dictionary.
Once we have the data in the JSON decoded dictionary, we loop through each item in the data key.

As seen from the API response, each test session comprises a unique test_id, a build_name, and a status_ind indicator. All these respective entries for each test session are printed on the console.
Coroutine 3 (Helper) : get_top_reddit_threads()
This helper function provides the top Reddit topics for a particular subreddit (e.g., ‘Selenium‘, ‘Playwright‘, ‘Python‘, ‘asyncio‘). The subreddit is passed as an argument to the get_top_reddit_threads() coroutine.
Like the other helper functions, we first construct the URL along with the query parameters sort=top, t=day, and limit=20 to get the top 20 posts of the day.
The get_json() helper is invoked here as well in order to perform the GET request on the URL created in the earlier step. The byte-encoded response data is then decoded into a string of UTF-8 format. The loads() method parses the JSON string into a Python dictionary.
Now that we have the decoded JSON, we loop through each item in the children list, which is under the data key. Each item represents a Reddit post.
For testing, just head over to the Python subreddit URL (for Python) and it is seen that entries score, title, and link are present in the children list, which is under the data key.

The meta-data (i.e., score, title, and sub-reddit link) are finally printed on the console.
With the helper functions all covered, let’s look at the test functions/coroutines used in the example.
Coroutine 1 (Test Function): test_fetch_lambdatest_sessions()
Since this is an asynchronous test function (or coroutine), it is marked with the @pytest.mark.asyncio decorator. With this, the test_fetch_lambdatest_sessions() function is executed as an asyncio task in the event loop provided by pytest-asyncio.
Next, a default SSL context is created using the create_default_context() method of the SSL library. During the implementation, we came across a few errors related to SSL verification, and the Stack Overflow thread on SSL in Python helped resolve those errors.
The path to the system CA certificate bundle is provided via the certifi.where() method. The certificate is then passed to the SSL context to ensure a secure connection.
ClientSession is the entry point for all the client API operations. Since we are using custom SSL parameters, an ssl.SSLContext instance is created and used for the entire session with ClientSession(connector=TCPConnector(ssl=ssl_context)).
The connector parameter in ClientSession is set to aiohttp.TCPConnector with the ssl parameter set to ssl_context. With this, the session uses the SSL context (ssl_context) for secure connections.
Finally, the helper function/coroutine get_lambdatest_sessions() is invoked with the newly created session passed as a parameter to it.
As seen from the example, we are creating a new session object for each test, this could have been further optimized by using pytest fixtures with asyncio.
Coroutine 2 (Test Function): test_fetch_reddit_threads()
Most of the implementation of test_fetch_reddit_threads() remains the same as that of test_fetch_lambdatest_sessions(), barring a few changes.
First, we create a list of all the subreddits (i.e., Selenium, Playwright, Python, and asyncio) whose top threads need to be fetched. Next up, we create a list of tasks/coroutine objects by invoking the helper get_top_reddit_threads() for each subreddit in the list. The session object that was created in the earlier step is passed in the helper function along with the subreddit.
All four tasks run concurrently via the gather() method of the Python asyncio library. The return_exceptions parameter in asyncio.gather() is set to False, which means that an exception raised by any task will result in cancellation of the other tasks/awaitables.
Execution
Invoke the following command on the terminal to execute the tests:
pytest --verbose --capture=no tests/sample-examples/5_async_await.py
As seen in the execution snapshot, both the tests executed successfully, and the top 20 LambdaTest test sessions and the top 40 Reddit threads are printed on the console.


To summarize, the combination of async/await, tasks, and more can be leveraged for handling concurrent execution and freeing up the CPU when I/O bound operations, network requests, etc. are in progress. All of this allows the application to remain responsive while accelerating the speed of test execution!
How to Make Python Code Asynchronous?
Before getting into how to make the code asynchronous, it is important to identify the scenarios for which async should be preferred over the sync mode! Here are some considerations that should be taken into account when opting for asynchronous code in Python:
Identify Operations Involving External Resources
Till now, it is very evident that asynchronous execution is the way to go when the application involves operations with external resources – network requests, database queries, I/O, etc.
In such scenarios, the CPU would be less loaded whereby it can pick up other tasks that require its attention. Here, we are not referring to CPU-bound tasks for which Python asyncio has to be integrated with executors to improve application responsiveness & performance.
For CPU-bound tasks or blocking I/O, Python asyncio can be used with ThreadPoolExecutor for offloading tasks from the asyncio event loop. Also, Python asyncio with ProcessPoolExecutor offers the benefits of parallelism by making the best use of multi-CPU cores.
Concurrent Test Execution
Secondly, asynchronous execution should be opted if the application has independent tasks that can be executed concurrently. We looked into one such scenario where we made multiple API calls (i.e., LambdaTest APIs & Reddit APIs) in parallel, and async/await & tasks helped in faster test execution!
Libraries like Python asyncio, aiohttp, aiomysql, aiopg, etc., can be leveraged to concurrently execute applications built using the event-driven microservices architecture.

You can also refer to our blog on Microservices Design Principles for a quick refresher on design patterns that best suit your microservices-based application.
Mark Functions As Coroutines
Functions with I/O-bound operations are the ideal contenders for asynchronous execution. These functions can be converted into coroutines using the async/await keywords.

Replacing blocking calls with await allows other tasks to execute while the awaited operation is in progress. As seen above, two simple tests that sleep for 2 seconds execute concurrently using the gather() method of the Python asyncio library.
While the sync equivalent of the above snippet takes 6 seconds to execute, the async variant executes in 4 seconds!


To summarize, it is recommended to accelerate execution time with asyncio by replacing tasks/functions that involve operations pertaining to I/O, servers, databases, and more.

Demonstration: Asyncio in Python
Now that we have covered most of the essential concepts of Python asyncio, let’s dive deep into real-world scenarios. Before doing the same, let’s set up the project and execution environment.
Project Structure
The project structure is where the tests demonstrating the usage of the Python asyncio library are located in the tests folder.
Let’s do a deep dive into the project structure:
- pageobject – Contains locators used in the respective tests. Primarily created for realizing the needs of Page Object Model in Selenium Python.
- tests/fetching_pokemon_names – Sync and async fetching of Pokemon information using Pokemon APIs.
- tests/fetching_weather_information – Sync and async fetching of current weather of US cities using OpenWeather APIs.
- tests/get_automation_builds – Fetching metadata of sessions created for running tests on the LambdaTest Cloud Grid. LambdaTest Sessions API is used to fetch the respective information.
- tests/url_health_checking – Sync and async implementation for checking the health of links present on LambdaTest Selenium Playground.
- tests/web_scraping – Scraping of items on LambdaTest eCommerce Playground using sync and async programming in Python.
Apart from the above-mentioned directories, the project also contains the following files in the project’s root directory:
- conftest.py – Configuration file in pytest used for sharing fixtures, hooks, and other configuration settings across test files in the suite.
- Makefile – Contains commands used for executing tests in sync and async mode in Python.
- pyunitsetup.py – Implementation for setting up the browser instance, setUp, and tearDown functions.
- requirements.txt – Contains a list of packages or libraries (e.g., bs4, aiohttp, etc. required for the implementation & execution.
As stated earlier, it is recommended to have Python 3.4 (or later) since the Python asyncio library is available out of the box in those versions of Python.
Project Prerequisites
It is recommended to use a virtual environment (venv) since it helps in better management of dependencies and environments. In a nutshell, the virtual environment provides isolation from the packages in the base environment.
Note: Please replace pip3 with pip depending on the pip version installed on your machine.
Run the commands virtualenv venv and source venv/bin/activate on the terminal to create the virtual environment.
Now that the virtual environment is ready let’s install the required libraries present in requirements.txt. Invoke the command pip3 install -r requirements.txt on the terminal.
Here is the list of libraries that we have installed for the demonstration:
| Library | Description | GitHub Link |
|---|---|---|
| pytest-xdist | Helps realize parallel test execution with pytest | https://pypi.org/project/pytest-xdist/ |
| pytest-asyncio | Provides support for coroutines as test functions. | https://pypi.org/project/pytest-asyncio/ |
| requests | HTTP library used for making HTTP requests in a synchronous manner | https://pypi.org/project/requests/ |
| pytest-order | Allows customization of the order in which the tests in Pytest are executed | https://pypi.org/project/pytest-order/ |
| bs4 | Allows scraping of information from HTML and XML documents | https://pypi.org/project/beautifulsoup4/ |
| aiohttp | Asynchronous HTTP client/server framework. Used for accelerated web scraping in Python | https://pypi.org/project/aiohttp/ |
| python-dotenv | Reads key-value pairs from a .env file | https://pypi.org/project/python-dotenv/ |
In the interest of time, we will be deep-diving into the following scenarios in the further sections of this Python asyncio tutorial:
- Web scraping
- URL health checking
- Fetching weather information
- Getting session details on LambdaTest
We will be benchmarking async with sync using the Hyperfine command-line tool. In case you are using macOS, run the common brew install hyperfine on the terminal for installing Hyperfine in the execution environment.
At the time of writing this Python asyncio tutorial, the latest version of Hyperfine is 1.18.0. Run the command hyperfine –help in case you need more information about the usage of Hyperfine.
Asynchronous Web Scraping in Python
Web scraping in Python is one of the popular use cases where libraries like requests, BeautifulSoup (bs4), etc., can be leveraged for scraping information from a document. In this Python web scraping repo, I have used the synchronous approach to scraping.
Though synchronous web scraping with requests and bs4 does the job well, it might falter in performance (or scraping time) if information has to be scraped from a large number of pages. We will be scraping content from LambdaTest eCommerce Playground like it is done in the repo where we have used bs4 and requests for sync web scraping.
Since we will be benchmarking the sync vs. async performance, we first scrap content on the eCommerce Playground using the sync approach (using bs4 & requests libraries in Python).
Implementation (Synchronous Web Scraping in Python)

We will not be divulging the source code since a detailed explanation is available in the Scraping eCommerce Playground section of the Python web scraping blog!
For simplification, we will be porting the sync code to its async equivalent by doing the following modifications:
| Porting Sync Implementation to Asyncio |
|
Though BeautifulSoup/bs4 is not recommended due to its synchronous nature, we are using it to simply parse the HTML content from the eCommerce Playground.
Implementation (Asynchronous Web Scraping in Python)
To get started, we first import all the required libraries in the project. We came across aiohttp.client_exceptions.ClientConnectorCertificateError is the solution that we discovered in this Stack Overflow thread. Hence, the certifi library that validates the trustworthiness of SSL certificates is imported into the code.
The aiohttp and bs4 libraries are also imported for asynchronous HTTP communication with Python asyncio & parsing HTML content, respectively.
Like the earlier example of sync web scraping, the locators are separated from the core implementation to make the ideal use of the Page Object Model in Python. On similar lines, helpers.py contains the helper functions that would be used in the tests.
All the functions in the async-based implementation are marked with the async def keyword. The scrap_ecommerce() coroutine does the scraping of the content from the LambdaTest E-Commerce Playground. The URL to be scraped is passed as a parameter to the coroutine.
As mentioned earlier, we encountered SSL certificate verification errors. To counter the same, we have created a custom SSL context that includes a trusted certificate authority (CA) bundle. It is used to verify SSL certificates.
The create_default_context() method of the SSL library creates a new SSL context with the default settings. certifi.where() returns the path to the CA bundle – a file that contains root and intermediate certificates.
The custom SSL context (i.e., ssl_context) will be used in further sections of the code.
The ssl_context created in the earlier step is now passed to the TCPConnector() method of the aiohttp library for creating a ClientSession (named session). HTTP requests made within the session are always secure with the trusted CA bundle.
The fetch_url() coroutine is a helper that takes the URL to be scraped and the currently active session as the input parameters. It asynchronously fetches data (with async HTTP GET request) from the specified URL using the aiohttp library.
With await response.text(), completion of reading the response content is awaited, and the same is converted into HTML content (of string format).
BeautifulSoup(html, ‘html.parser’) returns a BeautifulSoup object that is used further for scraping. As mentioned earlier, this is not a time-consuming operation hence, bs4 is used in asynchronous web scraping.
The select() method of bs4 finds elements using the CSS Selector property – .product-layout.product-grid.no-desc.col-xl-4.col-lg-4.col-md-4.col-sm-6.col-6
As seen below, 15 elements match the CSS Selector, as there are 15 products on the said product page. The method returns a list that is used later for scraping meta-data (i.e., name, price, description, etc.) of every product on the page.

It is important to note that the same logic is also used for synchronous web scraping. A loop is run for scraping information of all the 15 products (or elements) under the div located in the earlier step.
The product link is obtained by locating the element using the find() method of bs4. The first argument is the tag that needs to be searched for (i.e., ‘a’ – anchor tag), and the second is the CSS Class attribute.
Along similar lines, the price of the product/element is obtained by locating the element using the find() method of bs4 along with the Class selector (i.e., price_new).
The get_text() method of bs4 provides the product name & price when used with the respective elements.
Every dictionary entry (i.e., meta_data_dict representing product name, product link, name, and product price is finally appended to a list in Python.
Since we have to scrap product information from Page – 1 through Page – 5, we first create tasks for scraping information from the said pages in a concurrent fashion.
The tasks created in the earlier step are run concurrently by invoking the gather() method of the Python asyncio library. return_exceptions parameter in the method is set to FALSE (by default), which means that failure in scraping content from any page would result in the cancellation of other tasks. The final result is available in the results list.

It is the above step that leverages the advantages offered by tasks in Python asyncio and aiohttp library for concurrent scraping of multiple pages (Page -1 through’ Page – 6). Shown below is its sync equivalent, where the scrap_commerce() method is called for every page but in a synchronous manner.

Now that the content is scraped, we invoke the helper print_scrapped_content()
for printing scraped content on the console. asyncio.run() is invoked for executing the main() coroutine synchronously.
Benchmarking – Sync and Async web scraping
Invoke the command make perform-web-scraping for benchmarking the scraping use case using the Hyperfine command-line utility. The warmup option in Hyperfine is set to 3. Hence, the actual benchmarking starts after three warm-up runs! The show-output option in Hyperfine shows the command output/execution on the terminal.

As seen from the benchmarking results, asynchronous web scraping is close to 2.93 times faster than its synchronous counterpart! Though the number looks a tad smaller, it is something that can make a huge performance impact when used in scraping a large number of documents (or pages)!
FastAPI With Asyncio for High-Performance APIs
FastAPI is a popular modern and high-performance web framework that is used for building APIs with Python. The framework is designed for optimizing the overall developer experience whereby you can build production-ready APIs keeping the best practices in mind.
As stated in the FastAPI official documentation, the performance of FastAPI is on-par with NodeJS and Go. It is built on open standards for APIs, i.e., OpenAPI (earlier known as Swagger) and JSON Schema. Like other Python frameworks, FastAPI also increases developer productivity and minimizes duplication of code.
FastAPI, when combined with Python asyncio results in improved throughput and faster response times, as Python asyncio helps in better handling of simultaneous incoming requests. This makes the application more scalable, as Python asyncio does the job of effectively managing the system resources. With Python asyncio, you can build high-performance and low-latency APIs that are capable of handling high loads with ease!
To install FastAPI, you need to trigger pip3 install fastapi uvicorn on the terminal. uvicorn is the server that will use the API you build to serve requests.

At the time of writing this Python asyncio tutorial, the latest versions of FastAPI & uvicorn are 0.112.2 & 0.30.6 respectively.

It is recommended to separate the tests from the core application logic, very similar to what we normally do in the Page Object Model in Python. For FastAPI, the core application logic (i.e., routines, dependencies, configurations, etc.) is normally placed in the app folder, whereas the test logic is placed in the tests folder.
However, you can have a different directory structure depending on the project requirements. In a nutshell, opt for a directory structure that makes the code more maintainable and scalable in the long run.
Demonstration: FastAPI With Asyncio
In order to demonstrate the capabilities of FastAPI with Python asyncio, we would be developing a simple FastAPI application that interacts with the LambdaTest APIs. The APIs are used for fetching details associated with the builds and sessions executed from my account.
The core application logic is in app/main.py, and the tests that use the application logic are placed in the tests/test_main.py
The APIs that fetch the build and session information asynchronously are located in tests/fastAPI/app/main.py.
| import os | |
| import ssl | |
| import certifi | |
| import aiohttp | |
| from fastapi import FastAPI, HTTPException | |
| from dotenv import load_dotenv | |
| load_dotenv() | |
| user_name = os.getenv('LT_USERNAME') | |
| api_key = os.getenv('LT_ACCESS_KEY') | |
| app = FastAPI() | |
| async def get_lambdatest_all_builds(session): | |
| url = f"https://{user_name}:{api_key}@api.lambdatest.com/automation/api/v1/builds?limit=50" | |
| headers = {"accept": "application/json"} | |
| async with session.get(url, headers=headers) as response: | |
| if response.status == 200: | |
| builds_data = await response.json() | |
| print(builds_data) | |
| return builds_data | |
| else: | |
| raise HTTPException(status_code=response.status, detail=await response.text()) | |
| async def get_lambdatest_all_sessions(session): | |
| url = f"https://{user_name}:{api_key}@api.lambdatest.com/automation/api/v1/sessions" | |
| headers = {"accept": "application/json"} | |
| async with session.get(url, headers=headers) as response: | |
| if response.status == 200: | |
| sessions_data = await response.json() | |
| print(sessions_data) | |
| return sessions_data | |
| else: | |
| raise HTTPException(status_code=response.status, detail=await response.text()) | |
| @app.get("/builds/") | |
| async def fetch_builds(): | |
| async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=ssl.create_default_context(cafile=certifi.where()))) as session: | |
| builds_data = await get_lambdatest_all_builds(session) | |
| dashboard_urls = [build['dashboard_url'] for build in builds_data.get('data', [])] | |
| return {"dashboard_urls": dashboard_urls} | |
| @app.get("/sessions/") | |
| async def fetch_sessions(): | |
| async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=ssl.create_default_context(cafile=certifi.where()))) as session: | |
| sessions_data = await get_lambdatest_all_sessions(session) | |
| session_names = [session['build_name'] for session in sessions_data.get('data', [])] | |
| return {"session_names": session_names} | |
| if __name__ == "__main__": | |
| import uvicorn | |
| uvicorn.run(app, host="0.0.0.0", port=8000) |
 by
by Let’s look at some of the most important aspects of the code! First, we import the FastAPI class that is used for creating the FastAPI application. An instance of that class is normally assigned to a variable (e.g., app). The newly created app object would be used to define the web application that includes endpoints, configurations, etc.
As we are fetching information from LambdaTest using LambdaTest REST APIs, the user-name & access-key are read from the environment variables – LT_USERNAME and LT_ACCESS_KEY.
As stated earlier, an object (named app) of the FastAPI class is created using app = FastAPI(). As seen in the implementation, the @app.get(“/”) decorator is used for defining a route/endpoint that responds to GET requests at the root URL (“/”). In our case, it is @app.get(“/builds/”) and @app.get(“/sessions/”).
get_lambdatest_all_builds() & get_lambdatest_all_sessions() are two asynchronous methods for fetching build & session related information respectively. As seen below, we first construct the URL with the combination of user_name, access_key, and LambdaTest API. The limit parameter is set to 50 so that details about the first 50 builds are fetched with the API.
The request headers are set up to specify that the client expects a JSON response from the server.
Next an asynchronous context manager (async with) is used for making a GET request to the LambdaTest API with the session object. It is an instance of an HTTP client session (e.g., aiohttp.ClientSession).
The status code of the response object is checked. If the request is successful, the status of the response is 200.
An exception is raised, and the error message returned by the server is printed in case the execution is not successful.
As stated in the FastAPI official documentation, the @app.get(“/builds”) route decorator tells FastAPI that the function right below is in charge of handling requests that go to the path /builds/ using a get operation.
First, an asynchronous HTTP client session (i.e., ClientSession) is created using the aiohttp library. As seen earlier, the ClientSession object is used for managing the HTTP requests within the session.
The session object is passed to the get_lambdatest_all_builds() method. It returns data in a JSON format in case the LambdaTest API returns build information.
The data field is extracted from the JSON response (i.e., builds_data). An empty list is returned if the data field does not exist.
The uvicorn.run(app, host=”0.0.0.0″, port=8000) runs the FastAPI application (i.e., app) that was created earlier with app = FastAPI() method. The argument host=”0.0.0.0″ tells Uvicorn to listen to all the available IP addresses. The other argument port=8000 specifies the port on which the server should listen for incoming requests.
Now that we have covered the methods that are part of the business logic let’s look at the test methods that would be used for testing the APIs implemented earlier. The test methods are a part of tests/test_main.py
| import pytest | |
| import aiohttp | |
| import sys | |
| import os | |
| # Add the project directory to the system path | |
| sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..', 'app'))) | |
| from fastapi.testclient import TestClient | |
| from main import app # Import the app from app/main.py | |
| client = TestClient(app) | |
| @pytest.mark.asyncio | |
| async def test_fetch_builds(): | |
| async with aiohttp.ClientSession() as session: | |
| response = client.get("/builds/") | |
| assert response.status_code == 200 | |
| data = response.json() | |
| assert "dashboard_urls" in data | |
| assert isinstance(data["dashboard_urls"], list) | |
| @pytest.mark.asyncio | |
| async def test_fetch_sessions(): | |
| async with aiohttp.ClientSession() as session: | |
| response = client.get("/sessions/") | |
| assert response.status_code == 200 | |
| data = response.json() | |
| assert "session_names" in data | |
| assert isinstance(data["session_names"], list) |
We import the TestClient class from the fastapi.testclient module. TestClient helps simulate requests to the FastAPI application and receive responses from the application. After the app directory (i.e., tests/app) is added to the system path, the FastAPI application instance/object (i.e., app) is imported from the module named main.
Next, we create a TestClient for the FastAPI application by invoking client = TestClient(app). In the application code, we created two routes/endpoints – builds and sessions. Here in the test code, we simulate an HTTP GET request on the respective endpoints (i.e., builds and sessions).
If the status of the response is OK (i.e., 200), we parse the body of the HTTP response as JSON. Python assert is raised if the value associated with the dashboard_urls key is not of the type list.
With this, we are all set to execute the FastAPI Python asyncio tests. The tests will run on the LambdaTest platform. It is an AI-powered test execution platform that allows developers and testers to run Python automated tests at scale across various operating systems and web browsers online.

After exporting the environment variables LT_USERNAME & LT_ACCESS_KEY, run the command make fast-api-asyncio on the terminal to execute the tests implemented in tests/test_main.py.
As seen below, the details of the builds and sessions associated with my LambdaTest account are printed successfully.


What we have demonstrated here is just scratching the surface as far as FastAPI with Python asyncio is concerned . Their combination can be harnessed to develop high-performing, scalable, efficient, and fast web applications.
Asynchronous URL Health Check in Python
One of the popular use cases of Python asyncio is checking the health of a web service (or endpoint) by periodically analyzing responses received in requests sent to the specified URL. It could also be used for API testing using different HTTP methods (i.e., GET, POST, PUT, DELETE) supported by the respective API.
Website monitoring and Service Level Agreements (SLAs) are other prominent use cases of URL health checking with Python. In all cases, the first & foremost thing is to check the availability of the URL and verify whether the response received is STATUS_OK (or 200).
For demonstrating the usage of Python asyncio, we would be performing a health check of the URLs present in the LambdaTest Selenium Playground.
Akin to the previous example, we would be benchmarking the performance of sync and async implementation.
Implementation (Synchronous URL Health Checking in Python)

First we scrap all the URLs which are stored in the meta_data_arr array. Now that the URLs are available, a for loop that iterates through every URL in meta_data_arr.
For each URL, an HTTP GET request is sent by invoking the get() method of the requests library. The received response is stored in a variable status_code.
As mentioned earlier, the health of the URL is fine (or is reachable) if the response to GET is 200. For instance, the link to Ajax Form Submit is reachable and should return a response of 200 when it is requested using the GET method. The same principle applies to all the other links present in the Playground.
Finally, an assert is raised if the URL is not reachable (or the status code is not 200)!
Implementation (Asynchronous URL Health Checking in Python)
Let’s port the existing code such that it runs asynchronously. Here are the top-level changes in the implementation:
- [Optional] Marking the tests with the @pytest.mark.asyncio decorator. However, this step is optional as we have already added asyncio_mode = auto in pytest.ini. You can refer to this Stack Overflow thread for more information.
- Replacing synchronous requests library with asynchronous aiohttp library for performing multiple asynchronous HTTP requests concurrently.
- Using the gather() method of the Python asyncio library to run multiple tasks concurrently.
Shown below is the complete implementation of Asynchronous URL health checking in Python:
For this scenario, we have used the pytest framework in Python. The execution is performed on a headless Chrome browser since we won’t be performing interactions with web elements on the page.
Since we are making use of Pytest, the fixtures, and hooks are located in the conftest.py – configuration file housing the required settings. The environment variable EXEC_ASYNC is set to true for async execution. As seen below, the to_thread() method of the Python asyncio library is used for creating Chrome browser instances in a separate thread.
The method [i.e., driver()] used for creating a browser instance is marked with the pytest fixture in Python with the function scope. Hence, the fixture is invoked for test methods where it is being used.
Once headless Chrome is instantiated, we first scrap all the URLs present on the LambdaTest Selenium Playground. The helper method scrap_playground_url() returns an array that contains the scrapped content. Let’s dive deep into it!
We first locate the entire grid housing the links with the find element method in Selenium. The element is located using the XPath Selector – //*[@id=’__next’]/div/section[2]/div/ul
The child elements in loc_parent_elem with class name pt-10 are located using the find_elements() method.
Like the earlier example, we first iterate over each WebElement in the loc_list_elems list. The href attribute of the child element located using CSS Selector .text-black.text-size-14.hover\:text-lambda-900.leading-relaxed contains the link to a page.
All the extracted links final_link are appended to the meta_data_arr array, which is returned by the helper function. Now that we have scraped the URLs present on the page, the next step is to check whether the URL is reachable or not.
Before that, we create an asynchronous session (named session) using the ClientSession class of the aiohttp library. The session is used for managing the HTTP requests & responses.
The check_status() coroutine takes the session (created in the earlier step) and target URL as the input parameters. The method asynchronously fetches data from the specified URL using the aiohttp library.
As seen below, the get method of the library sends an HTTP request to the URL supplied as a parameter. response, which is an instance of aiohttp.ClientResponse contains the client response. The status attribute provides the HTTP status of the response.
Next up, we create a list of tasks that can run asynchronously. The list iterates over each URL in meta_data_arr and creates a coroutine for the URL by invoking the check_status() coroutine.
The gather() method of Python asyncio runs the tasks asynchronously. Tasks are unpacked and passed as separate arguments to gather(). Upon execution, we have the list of status_codes (or response code) for each URL.
Finally, we run a for loop that iterates over two lists containing status_codes and meta_data_arr list. It asserts if the status code for the corresponding URL in meta_data_arr is anything other than STATUS_OK (or 200).
Benchmarking – Sync and Async URL Health Checking
Invoke the command check-url-health for benchmarking the specified usecase using the Hyperfine command-line utility. The benchmark is done after 10 successful runs of sync & async implementation. The show-output option in Hyperfine shows the command output/execution on the terminal.

As seen from the benchmarking results, asynchronous URL health checking is close to 1.70 times faster than its synchronous counterpart! The impact of async URL health checking will be monumental if the page/document (under test) contains a large number of links!
Asynchronous Weather Check in Python
In this example, we would be extracting weather information of US cities using OpenWeather APIs. Once you create an account on OpenWeather, you need to copy the Open Weather API key from the API Keys Section.
Post this, create an environment variable by invoking the following command on the terminal – export OPEN_WEATHER_API=<API-KEY>. As mentioned in the official OpenWeather documentation, gathering weather information for a particular city is possible via the following API:
API: Current Weather Data
https://api.openweathermap.org/data/2.5/weather?lat={lat}&lon={lon}&appid={API key}
- lat: latitude of the location
- lot: longitude of the location
- API key – Open Weather API Key
We tried out the API for a latitude & longitude combination, and it provided the weather information in a JSON format.

Though we would be scraping weather data, the difference here is that there is a relatively big data set when compared to the earlier examples. For demonstration, we would first scrape the City Name, Latitude, and Longitude of US cities mentioned in LatLong.net.

Data from Page – 1 through’ Page – 13 is scraped and fed to the OpenWeather API for fetching weather data. Like the previous examples, we would be using requests & bs4 for sync weather fetching and bs4 & tasks (in Python asyncio library) for async fetching of weather data.
Implementation (Synchronous Weather Fetching in Python)
Here, we have two primary methods:
- scrap_weather_site() – Scrap latitude, longitude, and city name from latlong website
- get_weather_info() – Use OpenWeather current data API for fetching weather information using Latitude & Longitude obtained from the earlier step
Since Beautiful Soup (b4) is also used in the async implementation, we will be covering the aspects of code walkthrough in that section!
Implementation (Asynchronous Weather Fetching in Python)
Instead of the requests library, we have used the aiohttp library for asynchronous handling of HTTP requests & responses. Also, asyncio.gather() is leveraged for handling multiple tasks asynchronously.
Here is the complete implementation of Asynchronous Weather Fetching in Python:
Like before, the create_default_context() method of the SSL library is used for creating a new custom SSL context. It is then passed to the TCPConnector() method of the aiohttp library for creating a ClientSession (named session). This session will be used throughout this example.
In the main() function, a for loop is run from 1 through 5 since we would be scraping latitude and longitude information for the first 5 pages on the Latlong website.
The page format is shown below:
- Page 1 – https://www.latlong.net/category/cities-236-15-1.html
- Page 5 – https://www.latlong.net/category/cities-236-15-5.html
Since we have to scrape content from multiple pages, the scraping is performed asynchronously. scrap_weather_site() returns a coroutine object that scrapes content from test_url using the session created in the first step. The coroutine object returned by the method is appended to the tasks list.
Let’s take a quick look at the scrap_weather_site() coroutine. It takes the URL (under test) and current session as the input parameters. First, the fetch_data() is invoked for fetching the HTML content [i.e., response.text()] of the URL provided to the method.
Now that we have the HTML document, we parse it using html.parser parser of BeautifulSoup/bs4.
The first row in the table contains the field titles. Hence, they can be skipped during parsing. Hence, [1:] is added when searching for <tr> elements in the parsed HTML. With this, parsing of rows starts from row number 2, the find_all() method of bs4 is used for searching all the rows matching the request.
A for loop is run iterating every row. The <td> element in each row contains the meta-data: place name, latitude, and longitude. With td_values = [td.get_text(strip=True) for td in td_tags], the leading (& trailing) spaces are removed from each <td> element.
Now that we have the data from every cell, a dictionary (named weather_data_dict) is created with the data. Post that, it is appended to the weather_data_arr array.
Now that we have the tasks list, asyncio.gather() is invoked for running all the tasks asynchronously. At this point, we have successfully scraped latitude and longitude from Page – 1 through Page – 13.
Next, a for loop is run over the weather_data_arr, and get_weather_info() is invoked asynchronously. Let’s dive deep into that particular method.
The get_weather_info() takes the current session, latitude, and longitude as the input parameters. The OpenWeather Current Data API is supplied with the latitude, longitude, and OpenWeather API Key.
The response (in a JSON format) to the API is obtained asynchronously by making an asynchronous GET to the OpenWeather API.
The get_weather_info() that returns a coroutine object is executed asynchronously by invoking the tasks.append() method that adds a new task to the list.
Finally, the tasks (or multiple coroutines) are executed asynchronously via the gather() method of the Python asyncio library. The execution results of the coroutines are aggregated in a single list.
Like before, return_exceptions is set to False (default), which means that the execution is halted if the execution of any of the coroutines fails.
As seen below, the temperature (i.e., temp) key is inside the main dictionary. On similar lines, weather_info[“main”][“temp”] – main field with nested temp field, provides the current temperature of the respective city in the US. The name field in weather_info provides the city name.
Finally, the city name & temperature are printed on the terminal.
Benchmarking – Sync and Async weather check
Invoke the command make fetch-sync-weather-info for fetching weather information of the supplied latitude(s) & longitude(s) synchronously. The operation was completed in approximately 325 seconds.

Invoke the command make fetch-async-weather-info for fetching weather information of the supplied latitude & longitude asynchronously using aiohttp & asyncio. The operation was completed in approximately 7 seconds.

We tried benchmarking with a few more execution cycles and async weather checking was significantly faster than its sync counterpart.
We have more examples – fetching Pokemon names and getting LambdaTest automation session details in the GitHub repository. A plugin named pytest-asyncio-cooperative can also be leveraged for cooperative multitasking to run your I/O bound test suite efficiently and quickly. As stated in the official documentation, the pytest-asyncio plugin is not compatible with the pytest-asyncio-cooperative plugin!
Over & above, FastAPI can also be used to improve the efficiency of the Python asyncio library. The combination helps reduce latency when handling requests, thereby resulting in faster response times. Covering FastAPI is beyond the scope of this Python asyncio tutorial; a separate blog would definitely do justice to the Python asyncio & FastAPI
Discover the top Python frameworks to watch out for in 2025. Stay updated on the tools shaping the future of development.
It’s A Wrap
Thanks for making it this far, it was definitely a long journey! As covered exhaustively in the tutorial, Python asyncio offers significant benefits when it comes to concurrent & accelerated test execution. This plays a major role in boosting the application’s performance.
In case you want to leverage the Python asyncio library for CPU-bound tasks or blocking I/O, we recommend checking out ThreadPoolExecutor. It offloads tasks from the Python asyncio event loop. Prominent use cases like web scraping, operations involving databases, etc., can benefit from asynchronous programming using the Python asyncio library.
Frequently Asked Questions (FAQs)
What is the difference between asyncio and generators in Python?
Python asyncio is a library that provides an event loop for managing asynchronous tasks and non-blocking I/O operations. In contrast, generators, created with the yield keyword, allow for lazy value production but do not handle concurrency. Python asyncio uses async def and await to run tasks concurrently, while generators focus on iteration.
What is the difference between queue and asyncio in Python?
A queue is a data structure used to store and manage items in a first-in-first-out (FIFO) manner. In Python asyncio, asyncio.Queue is an asynchronous queue that supports concurrent access by multiple coroutines, allowing tasks to communicate safely and efficiently without blocking the event loop. Thus, while both involve managing items, asyncio.Queue is specifically designed for use within an asynchronous context.
Why is asyncio better than threads?
Python asyncio is often preferred over threads for I/O-bound tasks because it reduces overhead from thread management, like context switching and synchronization. It enables lightweight concurrency by running multiple coroutines in a single thread, improving performance and reducing memory usage for I/O operations.
What is the asyncio future?
In Python asyncio, a future is a special low-level object that represents a result that may not be available yet. It acts as a placeholder for an eventual result of an asynchronous operation, allowing you to wait for and retrieve the result once it is ready. You can create and manipulate futures to coordinate asynchronous tasks.
How many times should asyncio run() be called?
asyncio.run() should be called once per program, as it is designed to run a single entry point of an asynchronous program. It sets up the event loop, runs the provided coroutine, and then closes the loop. If you need to run multiple coroutines, they should be structured within a single coroutine that you pass to asyncio.run().


Author’s Profile
Himanshu Sheth
Himanshu Sheth is a seasoned technologist and blogger with more than 15+ years of diverse working experience. He currently works as the 'Lead Developer Evangelist' and 'Senior Manager [Technical Content Marketing]' at LambdaTest. He is very active with the startup community in Bengaluru (and down South) and loves interacting with passionate founders on his personal blog (which he has been maintaining since last 15+ years).
Blogs: 129
Got Questions? Drop them on LambdaTest Community. Visit now