

A Deep Dive into the Challenges of Generative AI in Software Testing
Matt Heusser
Posted On: October 20, 2023
![]() 31050 Views
31050 Views
![]() 13 Min Read
13 Min Read
Last time, we talked about some potential uses for AI in testing. The breadth of the coverage meant we couldn’t get very deep on any particular use case. Since we barely scratched the surface, it made sense to come back for a deeper dive.
How about three?
Finding right-sized examples was a bit of a challenge. Most of our code is copyrighted; trivial examples often hide underlying flaws. Complex examples are more suited to a long video format. Even a long video is unlikely to be fully, clearly understood. For the examples today, we strove for a mixture of real-world complexity yet understandable and reasonably short.
The code samples that we follow are in Ruby, but we’ve tried to make them accessible by anyone with familiarity with at least one modern object-oriented or structured programming language.
Example One – Generative AI to Summarize Code
I asked ChatGPT to summarize bits of code from popular (but not too popular) open source projects on github with various levels of comments, cutting and pasting and removing identifying information. The most illustrative example is probably the chef token authenticator module. Here’s the summary:
This code appears to be a part of the Chef framework, specifically the Chef::HTTP::Authenticator class. This class is responsible for handling authentication and signing requests for HTTP communication within the Chef infrastructure.
Here’s a high-level overview of what this code does:
- The code includes required libraries/modules, such as chef/mixin/powershell_exec, openssl, and various custom classes/modules.
- It defines the Chef::HTTP::Authenticator class and sets up some constants, attributes, and accessors.
- The initialize method is responsible for setting up the object with the necessary authentication credentials and configuration options.
- The handle_request method prepares the HTTP request headers for sending, including adding authentication headers if required.
- The handle_response method is a placeholder, and it does not perform any specific response handling.
- The stream_response_handler and handle_stream_complete methods are also placeholders that don’t perform any specific actions.
- The request_version method determines the server API version to use for the request.
- The sign_requests? method checks if request signing is enabled and if valid authentication credentials are available for signing.
- Various helper methods are provided to detect and manage certificate keys on Windows platforms.
- The authentication_headers method generates the necessary authentication headers for signing requests.
It’s important to note that this code is just a part of the overall Chef framework and may interact with other components to perform its intended functionality fully.
If you have specific questions or concerns about this code or would like me to analyze any particular aspects of it, please let me know!
This breakdown is missing a lot of important methods, such as create_and_store password, load_signing_key, get_cert_password, encrypt_pfx_pass_with_vector. Enough that one might say ChatGPT “misses the point” of the module. It’s totally understandable. The methods it does describe are small and simple. It’s reasonable to infer that ChatGPT listed the methods it could figure out.
In other words, the tool appears to generate essays in a manner similar to that of a college freshman – someone who recognizes certain keywords and can reproduce them. It’s essential to understand the underlying process of generative AI; it employs a fit-to-curve algorithm with words, akin to how Microsoft Excel might utilize a few data points to estimate a line. This isn’t so much insight as it is a correlation. At first glance, one could argue that this is a better alternative to having nothing at all. It certainly shows potential. Instead of dismissing it with laughter, I would suggest giving it more trials, training it further, and observing the results it can yield.
While traditional AI tools like ChatGPT can summarize code, they often miss critical details or provide incomplete insights. For instance, when summarizing the Chef token authenticator module, ChatGPT’s output highlighted some methods but overlooked others, revealing the limitations of AI in handling complex, nuanced code.
This is where advanced tools come into play. Some newer solutions are specifically engineered to navigate the complexities and dependencies of code more effectively. They offer a deeper understanding of context, ensuring that essential methods and functionalities are captured comprehensively. One such tool is KaneAI, offered by LambdaTest.
KaneAI is a GenAI native QA Agent-as-a-Service platform to address the limitations seen in traditional AI tools. By leveraging sophisticated algorithms and an advanced understanding of context, KaneAI ensures that summaries and insights are not only comprehensive but also accurately capture critical methods and functionalities. This enables it to provide a more detailed and reliable analysis, overcoming the gaps often left by simpler tools.
With KaneAI, you get a solution that enhances the accuracy of code summaries and insights, making it a valuable asset for developers seeking thorough and actionable analysis of their codebase.

Example Two – Generative AI to Create Test Code (Boilerplate)
At times, all you require is a simple script to initiate a task that runs smoothly. For instance, launching a web browser to perform an end-to-end automated check by clicking buttons. However, I’ve often found myself spending hours trying to make it work in my specific environment, especially because I use Linux while most examples are for Windows, or vice versa.
At times, all you require is a simple script to initiate a task that runs smoothly. For instance, launching a web browser to perform an end-to-end automated check by clicking buttons. However, I’ve often found myself spending hours trying to make it work in my specific environment, especially because I use Linux while most examples are for Windows, or vice versa. This often happens due to minor configuration differences or compatibility issues between software versions. Another common requirement is identifying unique locators, like buttons or links on a webpage, to interact with them. As an illustration, I once asked Google’s Bard, which claimed to have access to the current internet, to visit the Excelon Development homepage, locate the search button, and provide me with the XPATH locator. Strangely, even with this information, Selenium IDE, a browser-based plugin recorder, becomes perplexed and records fine but fails to execute the playback properly. Bard claimed to find it, suggesting //input[@id='search_button‘]as well as this code to launch a browser and click the button:
button:
The code, of course, does not work. The search button doesn’t have an HTML attribute of @id; it’s a lot more complex than that. I used google chrome to inspect the element and found a structure like this:
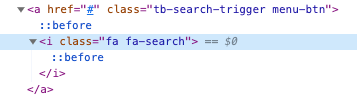
My attempts to click an element of class “fa fa-search” failed, so I tried XPATH – //a[@class=’tb-search-trigger menu-btn’]. For some reason this took close to a minute to run; the browser seems to be looping through every element of the document to find the link. To move forward I gave the outer HTMl, which is < A href= "#" class="tb-search-trigger-menu-btn" > – to bard directly. Google’s bar came up with CSS of a.tb-search-trigger.menu-button which is found in about a half a second.
It appears that Bard can only access Google search results, not analyze entire web pages.
This story did skip the interesting part, where the Chromedriver tool encountered difficulties launching Chrome. Chromedriver is an executable that sits between the code and the browser, sending commands into the browser for processing. It turned out that the latest stable release of Chromedriver didn’t work on macOS. This is a common problem that often requires searching on Google to find a solution, involving a process of exploration and trial and error until a resolution is discovered.
Bard wasn’t particularly helpful in this instance, as it provided a summary of the initial search results, none of which addressed the issue. Eventually, through my independent research, I identified the problem, installed an earlier version of Chromedriver, and successfully ran the code.
In a similar vein, Tim Western, a software developer and tester who reviewed this article, mentioned his difficulties in obtaining accurate syntax assistance from ChatGPT when dealing with specific problems. Conversely, Blake Link, a developer at Excelon Development, shared that one of his most valuable applications of generative AI is in generating regular expressions or crafting simple Unix commands.
As for using the tool to generate boilerplate code, that’a a pretty mixed bag.
Example Three – Unit Test Generator
“FizzBuzz” is a classic problem in computer science that turns numbers into words, with a bit of a twist. When a number can be evenly divided by 3, it gets converted to “Fizz,” and if it can be evenly divided by 5, it becomes “Buzz.” If neither condition is met, there is no change. The challenge arises when a number is divisible by both three and five, which is where some ambiguity might emerge, whether in the requirements or the code. (The answer, of course, is the word “FizzBuzz”).
I passed chatGPT this code, which contains the bug – it will exit at “Fizz” for 15, 30, 45, and so on.
While the initial tests that were generated were confirmatory, by the code, I asked ChatGPT to find bugs, and it generated these test ideas:
The divisible-by-15 case is well documented on the internet; it is unclear how the tools would do with requirements that are harder to infer. In another example, the Roman Numeral Kata had to check if the next number was larger, as “IV” is four but “VI” is “six.” Here’s the solution:
One if statement – “if (input[index + 1].nil?)” was missing from the chatGPT generated code. Instead, the code just executed the else block, and crashed on initial run. It took about as much time to debug and fix as it would have to have it work correctly in the first place.
Incorporating Gen AI into test automation can be challenging as it requires careful attention to integrate it into the testing flow. However, AI-generated test automation significantly enhances the speed of the testing process.

Summary – It’s a start
It’s essential to bear in mind that chat tools are explicitly designed to facilitate conversation. When they make an error, such as failing to locate an element entirely, you can correct them, and the tool will respond with something like, “I apologize” and appear to understand where it went wrong. However, the answer it provides might essentially be the same, missing the mark. When it offers an apology, it’s essentially echoing your words back with slight rephrasing, all while employing a knowledge of how humans communicate. On occasion, after investing five to thirty minutes of effort, I managed to coax the tools into providing improved responses by altering the way I phrased my questions. For queries that served as “gotchas” and weren’t easily searchable on the public internet, the tools struggled to find a solution.
Additionally, it’s worth noting that these are exceedingly straightforward, prepackaged exercises. As mentioned earlier, Blake Link has devised his own methods for using CoPilot, the AI tools integrated with the IDE at Excelon. He recommends instructing the tool to construct GUI and end-to-end workflows before the code is created, thus averting the problems outlined in our previous example. In such cases, ChatGPT can generate named IDs that can be reused. He also advises pasting the HTML into the tool, allowing it to generate accurate code. In real-world scenarios with more extensive web pages, the tool often struggles with pages that are overly complex, containing intricate JavaScript. It’s noteworthy that Facebook has a model called Llama, which operates on a local server (thereby avoiding uploading your source code to someone else’s cloud) and can handle a more substantial volume of data in your queries, accommodating longer web pages, additional code, and more extensive data.
Talking about data it’s crucial to address the potential risks associated with handling sensitive information within the testing process. As AI tools like CoPilot and models such as Llama operate on data provided to them, there is a need for caution when dealing with proprietary or confidential content. In the context of extensive web pages and intricate JavaScript, where tools might struggle, the integration of AI into test automation could inadvertently expose critical data.
The type of data being processed should also be taken into account, particularly when dealing with sensitive business logic or sensitive personal data. Encryption protocols and AI models that operate in a controlled environment can help reduce the chances of data leakage or unauthorized access.
In conclusion, when also considering the examples discussed in previous articles, such as searching for errors in requirements and generating test data, it is reasonable to assume that we’ve moved beyond the initial phase of inflated expectations and have traversed the trough of disillusionment. This article may represent the low point of that trough, but we might discover workarounds and practices to address these challenges. At the very least, I hope we have injected a sense of realism into what is currently achievable with Large Language Models for AI in testing.
It may be time to start climbing the slope of enlightenment.
Acknowledging the Credit
In this series I’ve come to use the term “we” because my peer reviewers offered so much value. I’d like to thank Harry Robinson, Andy Hird, Jeff Nadelman, Taran Rampersad, Titus Fortner, Timothy “Tim” Western, Wouter Lagerweij and Yury Makedonov for their peer review. They were tough; they made the work better. If you’d like to be involved in reviewing Matt’s work, email matt@xndev.com. Matt’s current goal is to make the writing more accessible, which means being a little junior or having a non-traditional test/CS background is a good thing for review.


Author’s Profile
Matt Heusser
As the Managing Director of Excelon Development, Matt Heusser, consults, trains, and does software delivery while helping others do it. Probably best known for his writing, Matt is the lead editor of "How to Reduce The Cost of Software Testing" (Taylor and Francis, 2011), editor for Stickyminds.com, and recipient of the 2015 Most Popular Online Contributor to Agile at the Agile Awards. A 2014 recipient of the Most Influential Agile Test Professional Person Award (MAITPP) in Potsdam, Germany, Matt also served as the lead organizer of the Software Testing World Cup. He is a former member of the board of directors of the Association for Software Testing and creator of Lean Software Testing family of methods.
Blogs: 6
Got Questions? Drop them on LambdaTest Community. Visit now













