

Generative AI for Efficient Test Data Generation and Management
Bharath Hemachandran
Posted On: July 13, 2023
![]() 18427 Views
18427 Views
![]() 9 Min Read
9 Min Read
Imagine a painter gearing up to create a masterpiece but being stuck with a limited palette. Can they create something beautiful? Absolutely! This is quite similar to the world of software testing, where we don’t have access to diverse and rich test data. Luckily, generative AI can be the game-changer in this scenario.
Generative AI works much like an art student who observes, absorbs, and then recreates paintings that can compete with the works of seasoned painters. This AI learns the patterns within the input data and then generates new data mirroring these patterns. The added benefit is that it can be trained not to breach any governance, privacy, security, or ethical norms that could prevent the use of original data.
Understanding Generative AI and Synthetic Data
Generative AI, a subset of artificial intelligence, is like a creative apprentice. It learns the patterns in the input data and then produces new data that echoes these patterns. Synthetic data is created and crafted to closely mirror the characteristics of the original data.
Harnessing Generative AI for Fraud Detection: A Use Case
Imagine Alpha Inc., a financial institution, developing a fraud detection system—a machine learning model trained to differentiate between fraudulent and legitimate transactions. To train this model effectively, they require a large and diverse dataset that sufficiently represents both types of transactions.
Challenges with Real Data
In reality, fraudulent transactions are like finding a needle in a haystack—they’re rare. Therefore, generating a real-world dataset with a significant number of fraudulent transactions is tricky. Governance and ethical constraints may further complicate and limit the available data for training the model.
As a result, training the model on such a dataset could produce a system that’s good at predicting legitimate transactions but fails to identify fraudulent ones. This bias towards the majority class (legitimate transactions) is a common problem known as “class imbalance.”
Generative AI to the Rescue
Here is where generative AI can step in. Assume that out of a dataset of a million transactions, only 1,000 are fraudulent. A generative AI model can be trained on this dataset to identify the characteristics of both fraudulent and legitimate transactions.
Once properly trained, the model can churn out synthetic transactions that closely resemble real ones. A standout feature of generative AI is that it can be instructed to produce data in specific ratios. Here, the AI can generate a dataset with both fraudulent and non-fraudulent transactions. This new synthetic dataset, enriched with fraudulent transactions, closely mirrors real-world scenarios.
The fraud detection system, when trained on this dataset, is less likely to be biased and more competent at identifying both fraudulent and non-fraudulent transactions since the dataset is balanced.
Real-world Impact
By using generative AI to create a balanced dataset, Alpha Inc. can build a more effective fraud detection system. A system that performs better can potentially save the institution millions by catching fraudulent transactions that might otherwise slip through the cracks. Moreover, it can boost customer trust and satisfaction. By curbing such incidents, the institution can retain its customers’ trust and loyalty.
Additionally, the use of synthetic data allows rigorous testing and development without compromising customer privacy or breaching data protection regulations. This could save the institution from potential legal issues and reputational damage.
In essence, the application of generative AI not only enhances the technical capabilities of the institution’s fraud detection system but also significantly boosts its business objectives and customer relations.
Generative AI for Streamlining Test Data Management
Imagine trying to maintain an enormous, chaotic library—that is what managing a mountain of test data can feel like sometimes. Generative AI offers a smarter solution; it can generate test data as and when we need it, reducing the need for extensive storage and ensuring the data is always fresh.
In a continuous testing environment, running multiple tests a day using static test data can lead to ineffective testing due to outdated data. However, with Generative AI, testing teams can generate a fresh set of data for each test run, ensuring a wide variety of scenarios are covered.
A Real-life Example: E-commerce Testing
Consider a globally renowned e-commerce company, Alpha Corp., which manages a complex website serving millions of customers worldwide. The platform boasts a plethora of features, including product browsing, customer reviews, cart management, and complex checkout and payment processing. To ensure smooth functioning, Alpha Corp. employs continuous testing to promptly identify and resolve issues.
The testing teams at Alpha Corp. run numerous tests every day to verify the functionality, performance, and security of the system. For these tests to be effective, they need diverse and updated data that can mimic real-world customer interactions.
Challenges with the Traditional Setup
In a traditional setup, the testing team would use a static dataset duplicated from production data. However, this approach has two main issues:
Data Staleness: With ever-changing market dynamics and customer behaviors, static data can quickly become outdated, leading to less effective testing.
Storage Issues: Keeping a large static test dataset that matches the diversity and volume of production data requires significant storage and constant management, adding complexity and cost.
Generative AI to the Rescue
However, Alpha Corp. has roped in Generative AI into their testing process to tackle these challenges. Before each test run, the Generative AI model, trained on production data patterns, creates a fresh set of synthetic data closely resembling real-world data.
For instance, while testing the payment processing system, the Generative AI model generates synthetic data for different types of credit cards, purchase amounts, user locations, and transaction times, mimicking current customer transaction behavior.
For organizations looking to streamline test data generation, advanced AI-driven platforms can step in to offer a solution. One such tool is KaneAI, which analyzes real-world patterns and creates synthetic data that mimics actual user behavior. By doing so, KaneAI ensures that testing processes remain relevant and efficient without violating privacy or security. Tools like these allow companies to scale their testing efforts while keeping data management complexities low, with KaneAI generating test data on demand, making continuous testing smoother and more Agile.
Real-world Impact
The freshness of the data ensures that it mirrors the latest trends and patterns in customer behaviors, leading to more effective and relevant testing. And since the synthetic data is created on demand and can be discarded after testing, the need for extensive storage and data management infrastructure is significantly reduced.
By integrating Generative AI into their test data management, Alpha Corp. has ensured more effective and efficient continuous testing, leading to improved system reliability and an enhanced customer experience.
Challenges and Considerations
Adopting Generative AI comes with its own set of challenges. The quality of the data that the AI is trained on ultimately affects the quality of the output. Unless we are aware of the data sources used to train the AI model for data generation, there will always be questions raised about the quality of the created data. Plus, generating test data using Generative AIs requires significant computational resources, which may not be feasible for all organizations.
As we delve into the complexities and potential of generative AI in test data management, it’s crucial to also consider the perspectives and concerns of those in the field. To gain a broader understanding, we conducted a social media poll asking professionals, “What’s your biggest concern about using AI in test automation?
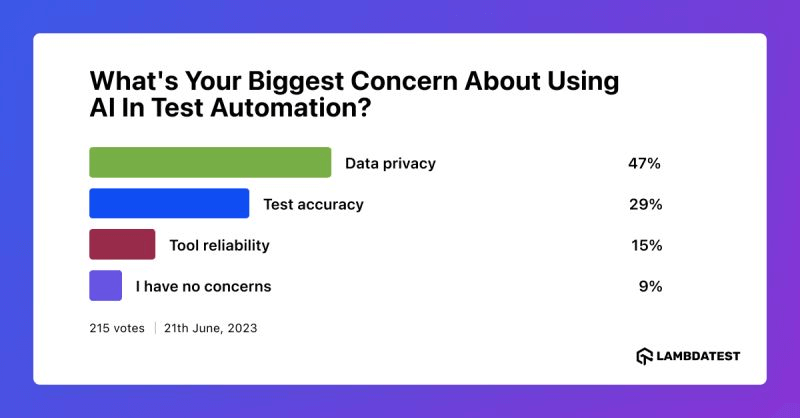
On the ethical front, even though synthetic data does not contain any sensitive information, it’s crucial to ensure that it doesn’t accidentally reveal any information about the individuals in the training data. Navigating these challenges responsibly is key.
Generative AI is set to transform the landscape of software testing. By enabling us to create diverse and realistic synthetic data, it heralds a new era of software testing—one that’s more efficient, comprehensive, and adaptable.
Looking Ahead
The future of Generative AI is exciting. The advancements in this technology could potentially reshape current workflows and practices. Organizations must stay updated and ready to adapt.
While the road to integrating Generative AI may have its bumps, the potential rewards—more efficient, comprehensive, and adaptable software testing—make it a journey worth taking. Let’s navigate this path responsibly and embrace the promising future that Generative AI has to offer.
Footnotes
Goodfellow, Ian, et al., “Generative Adversarial Nets,” Advances in Neural Information Processing Systems, 2014. [papers.nips.cc/paper/5423-generative-adversarial-nets]
Toraskar, Kshitij, et al., “Synthetic Data for Deep Learning.” IBM Developer, 24 Aug. 2020, [developer.ibm.com/technologies/artificial-intelligence/articles/synthetic-data-for-deep-learning/]
Duman, Evrim, and M. Hamit Serin. “Detecting credit card fraud by decision trees and support vector machines.” International MultiConference of Engineers and Computer Scientists, Vol. 1, 2011. [www.iaeng.org/publication/IMECS2011/IMECS2011_pp442-447.pdf]
Horton, Bob. “Class Imbalance, Redux.” Microsoft Developer Blogs, 29 Dec. 2016, [developer.microsoft.com/en-us/microsoft-365/blogs/class-imbalance-redux/]
Ghosh, Souvik. “Data Generation With Generative Adversarial Networks (GANs).” Medium, Towards Data Science, 23 Mar. 2020, [towardsdatascience.com/data-generation-with-generative-adversarial-networks-gans-977bdc2a89a0]
Reich, Gary. “The Hidden Cost of Stale Data in Your Automation Scripts.” Applitools, 27 Nov. 2018, [applitools.com/blog/stale-test-data]
Ching, Andrew, et al. “On the Computational Requirements for Production Machine Learning Services.” Medium, Towards Data Science, 18 Jul. 2018, [towardsdatascience.com/on-the-computational-requirements-for-production-machine-learning-services-208b311dbf6e]
Mehta, Anjali. “Privacy and Ethics in AI.” Medium, Becoming Human: Artificial Intelligence Magazine, 2 Jun. 2020, [becominghuman.ai/privacy-and-ethics-in-ai-d0d21a624018]


Author’s Profile
Bharath Hemachandran
Bharath Kumar Hemachandran is a Principal Consultant at Thoughtworks India, where he leads the Data & AI SL Ops, the Data Academy Program, and the India QA teams. He has over 18 years of experience in the software industry, working in various roles from developer to IT head. He is an innovative technologist and thought leader in the fields of cloud-native platform infrastructure, public cloud deployment, highly scalable and available infrastructure, and Generative AI. He is also an accomplished writer, with several published articles and blog posts on topics such as data and AI quality, data mesh, and generative AI.
Blogs: 2
Got Questions? Drop them on LambdaTest Community. Visit now














