How to Automate Shadow DOM in Selenium WebDriver
Faisal Khatri
Posted On: January 14, 2024
![]() 369408 Views
369408 Views
![]() 20 Min Read
20 Min Read
In one of my past projects, I encountered a test scenario where I had to click a button to navigate to the next page. I searched for the element locator of the button on the page and ran the tests, hoping it would click the button and navigate to the next page.
But to my surprise, the test failed as it couldn’t locate the element, and I received NoSuchElementException in the console logs, considering it was a simple button I was trying to click, and there was no complexity.
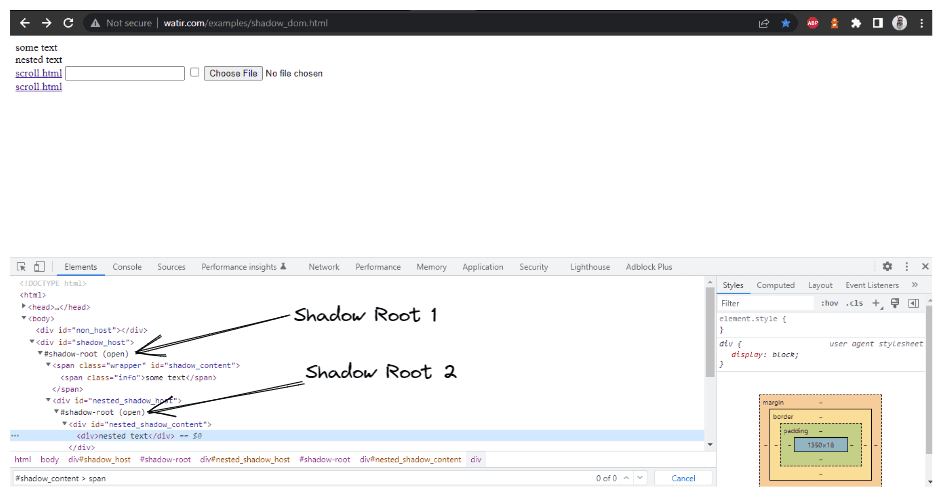
On analyzing the issue further, expanding the DOM, and checking the root elements, I found that the button locator was inside the #shadow-root(open) tree node, which made me realize that it needs to be handled in a different way as it is a Shadow DOM element.
In this Selenium WebDriver tutorial, we will discuss Shadow DOM elements and how to automate Shadow DOM in Selenium WebDriver. Before we move on to automating Shadow DOM in Selenium, let’s first understand what Shadow DOM is and why it is used.
If you’re looking to improve your Selenium interview skills, check out our curated list of Selenium interview questions and answers.
TABLE OF CONTENTS
What is a Document Object Model (DOM)?
The Document Object Model (DOM) represents the way a web page is accessed and manipulated. It defines the logical structure of the documents and represents the HTML document with a logical tree where each branch of the tree ends and each node contains objects.
DOM methods allow you to programmatically access the tree and change the document’s structure, style, or content.
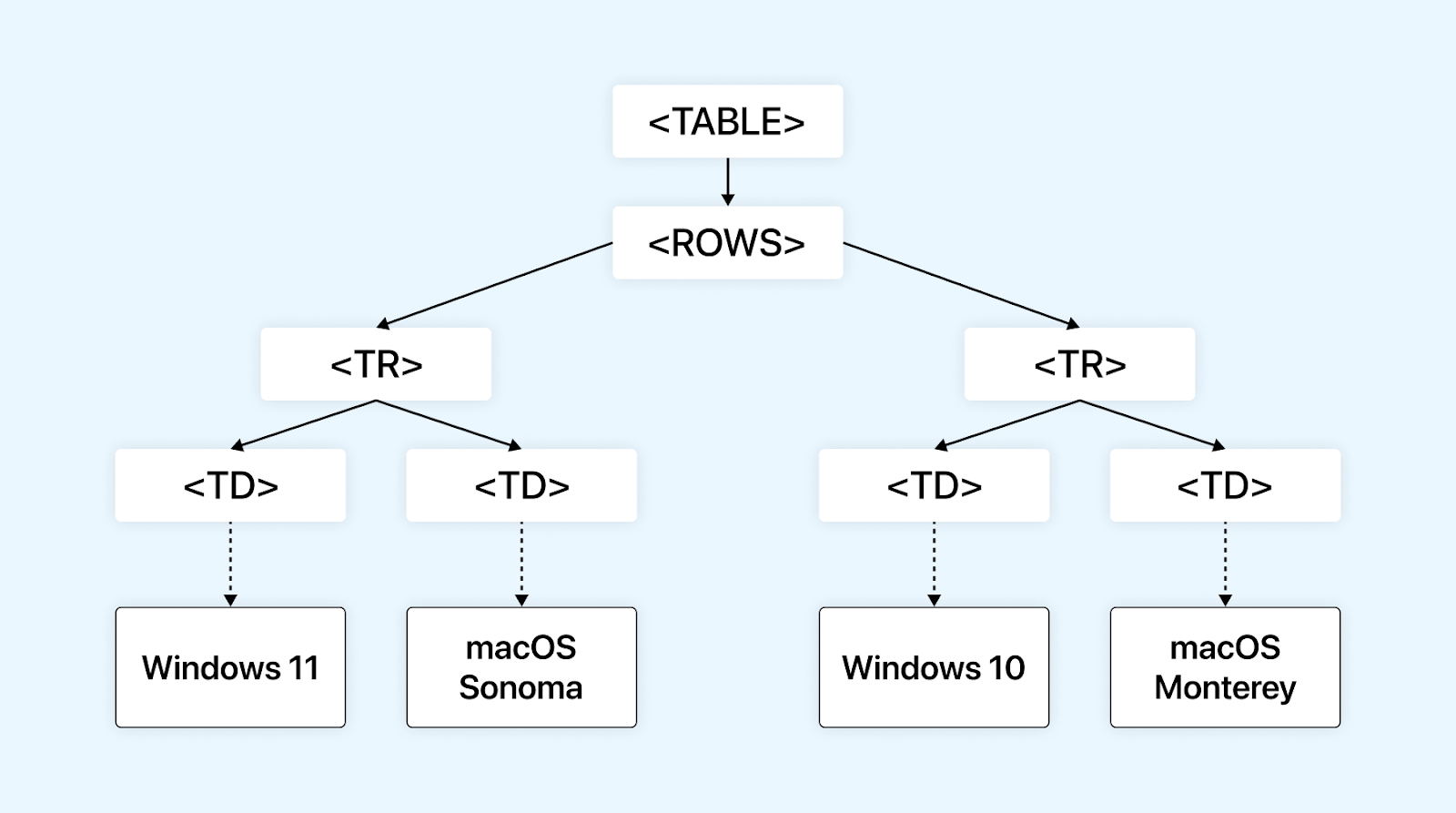
Following is an example of the DOM taken from an HTML document:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<TABLE> <ROWS> <TR> <TD>Windows 11</TD> <TD>macOS Sonoma</TD> </TR> <TR> <TD>Windows 10</TD> <TD>macOS Monterey</TD> </TR> </ROWS> </TABLE> |
Below is the representation of the above table
What is Selenium WebDriver?
Selenium WebDriver is a component of Selenium that helps in automating web browsers. It supports all the popular browsers like Chrome, Firefox, Edge, and Safari. WebDriver enables testers and developers to write web automation tests easily in multiple programming languages, like Java, Ruby, NodeJS, Python, C#, PHP, Perl, etc.
With the release of Selenium 4, multiple new features were introduced in Selenium, like an automated browser and driver management.
To get more details about Selenium WebDriver 4, you can refer to our earlier blog on Selenium 4 WebDriver hierarchy, which provides detailed insight into Selenium WebDriver’s architecture and related interfaces, classes, and interfaces.
Now let’s take a look at what is Shadow DOM.
What is Shadow DOM?
Shadow DOM is a functionality that allows the web browser to render DOM elements without putting them into the main document DOM tree. This creates a barrier between what the developer and the browser can reach; the developer cannot access the Shadow DOM the same way they would with nested elements, while the browser can render and modify that code the same way it would with nested elements.
The Shadow DOM is a way to achieve encapsulation in the HTML document. By implementing it, you can keep the style and behavior of one part of the document hidden and separate from the other code of the same document so that there is no interference.
Shadow DOM allows hidden DOM trees to be attached to elements in the regular DOM tree — the Shadow DOM tree starts with a Shadow Root, underneath which you can attach any element in the same way as the normal DOM.
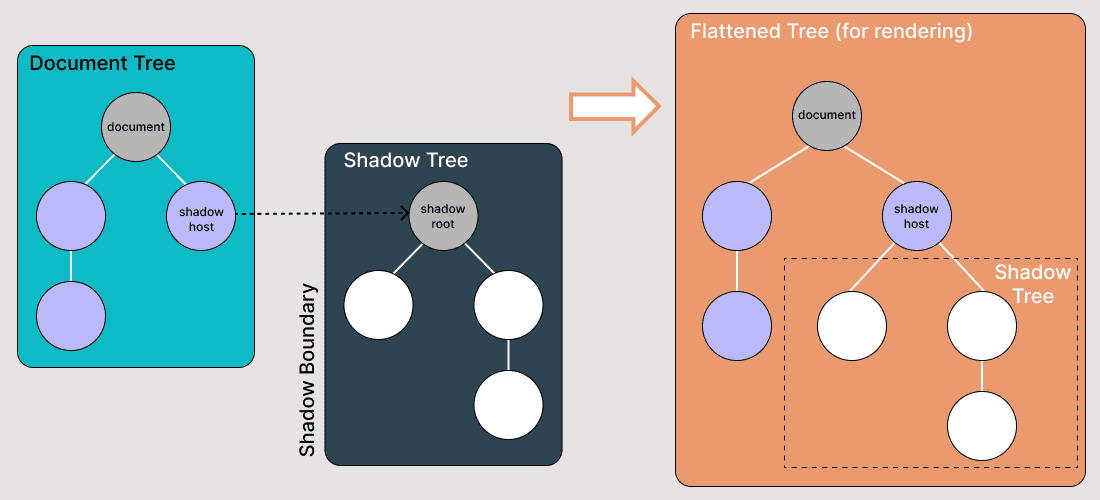
There are some bits of Shadow DOM terminology to be aware of:
- Shadow Host: The regular DOM node to which the Shadow DOM is attached.
- Shadow Tree: The DOM tree inside the Shadow DOM.
- Shadow Boundary: The place where the Shadow DOM ends and the regular DOM begins.
- Shadow Root: The root node of the Shadow tree.
Watch this video to learn what Shadow DOM is in Selenium 4.
In the next section of this Shadow DOM in Selenium tutorial, let’s see the usage of Shadow DOM.
What is the Use of Shadow DOM?
Shadow DOM serves for encapsulation. It allows a component to have its own “shadow” DOM tree that can’t be accidentally accessed from the main document, may have local style rules, and more.
Here are some of the essential properties of Shadow DOM:
- Have their own ids space.
- Invisible to JavaScript selectors from the main document, such as querySelector.
- Use styles only from the shadow tree, not from the main document.
In the next section of this tutorial on Shadow DOM in Selenium, we will look at how to find Shadow DOM elements using Selenium WebDriver.
Finding Shadow DOM Elements Using Selenium WebDriver
When we try to find the Shadow DOM elements using Selenium locators, we get NoSuchElementException as it is not directly accessible to the DOM.
We would use the following strategy to access the Shadow DOM locators:
- Using Selenium WebDriver getShadowRoot() method.
- Using JavaScriptExecutor.
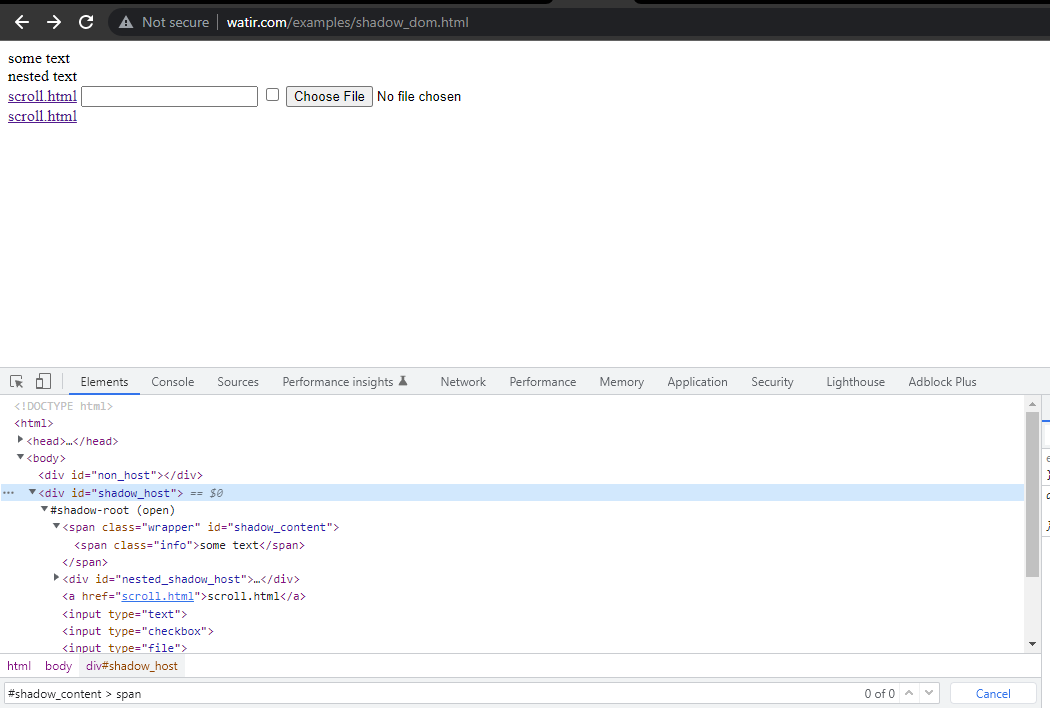
In this blog section on automating Shadow DOM in Selenium, let’s take an example of the Watir Homepage and try to assert the Shadow DOM and the nested Shadow DOM text with Selenium WebDriver. Note it has 1 Shadow Root element before we reach text -> some text, and there are 2 Shadow Root elements before we reach the text -> nested text.
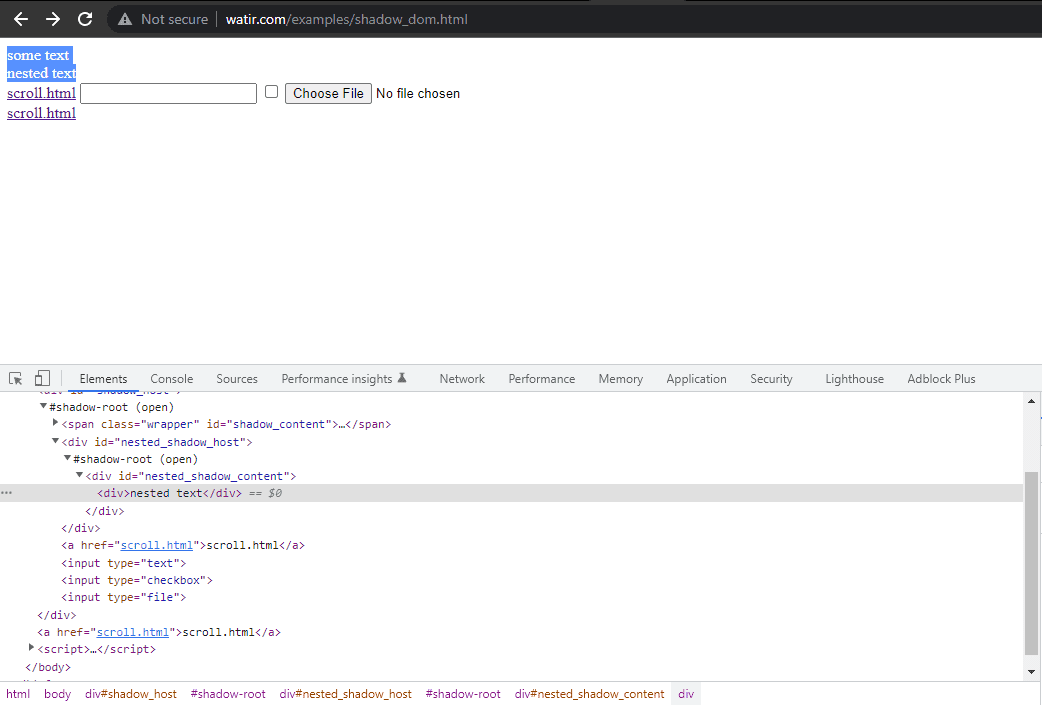
Now, if we try to locate the element using the cssSelector(“#shadow_content > span”), it
doesn’t get located, and Selenium WebDriver will throw NoSuchElementException.
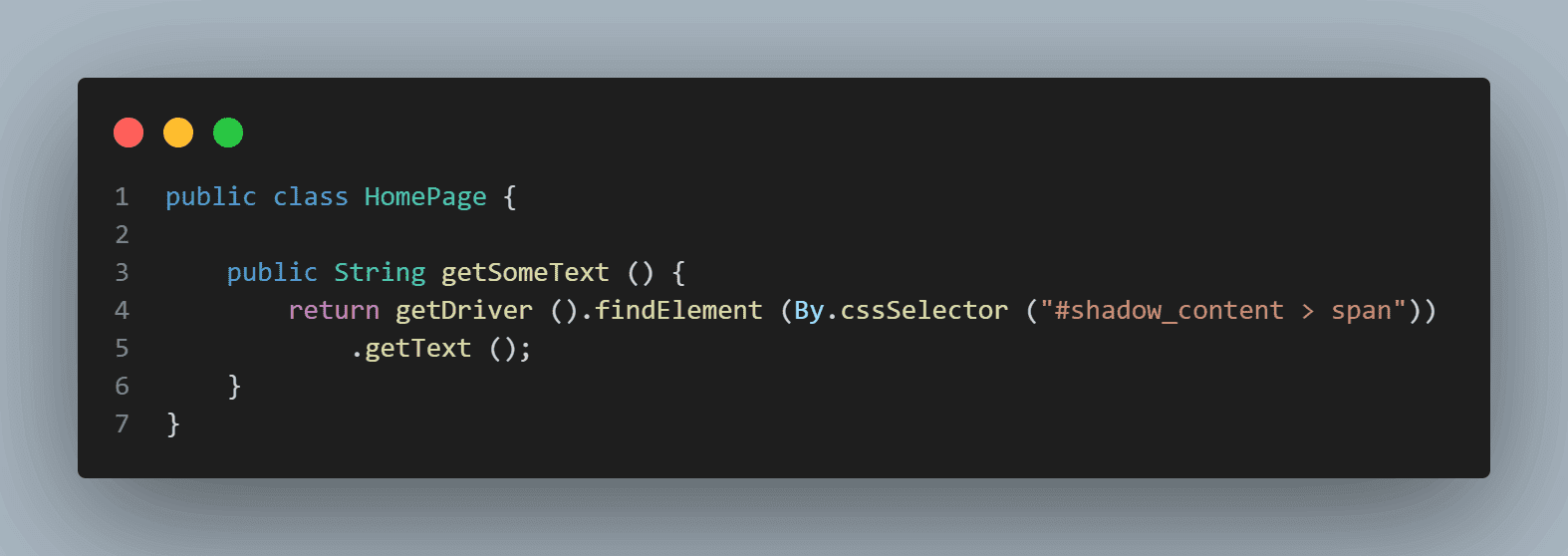
Here is the screenshot of the Homepage class, which has the code that tries to get text using
cssSelector(“#shadow_content > span”).
Here is the screenshot of the tests where we try to assert the text (“some text”).
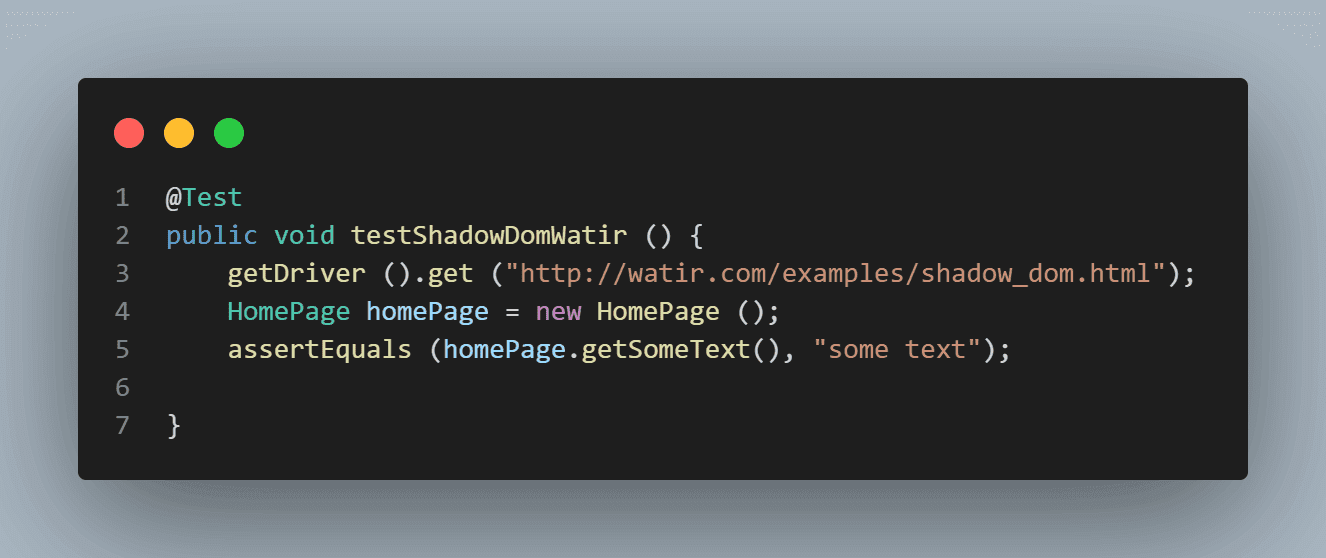
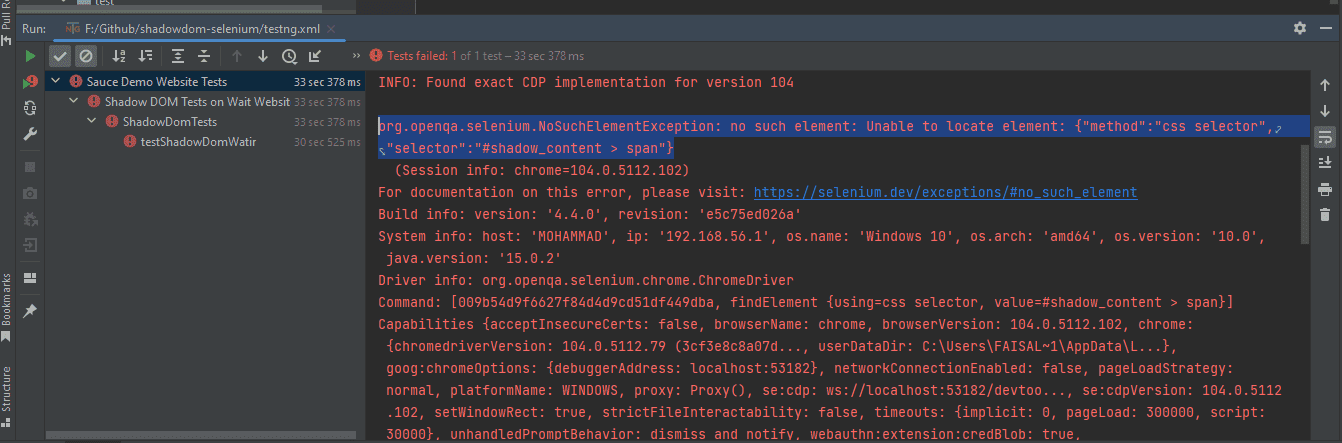
To locate the element correctly for the text, we need to go through the Shadow Root elements. Only then would we be able to locate “some text” and “nested text” on the page.
How to Find Shadow DOM Using The getShadowRoot Method?
With the release of Selenium WebDriver’s version 4.0.0 and above, the getShadowRoot() method was introduced and helped locate Shadow Root elements.
Here is the syntax and details of the getShadowRoot() method:
|
1 2 3 4 5 6 7 |
default SearchContext getShadowRoot() Returns: The ShadowRoot class represents the shadow root of a web component. With a shadow root, you can access the shadow DOM of a web component. Throws: NoSuchShadowRootException - If shadow root is not found. |
As per the documentation, the getShadowRoot() method returns a representation of an element’s Shadow Root for accessing the Shadow DOM of a web component.
In case Shadow Root is not found, it will throw NoSuchShadowRootException.
Before we begin writing the tests and discussing the code, let me tell you about the tools we would use to write and run the tests:
The following programming language and tools have been used in writing and running the tests:
- Programming Language: Java 17
- Web Automation Tool: Selenium WebDriver
- Test Runner: TestNG
- Build Tool: Maven
- Cloud Platform: LambdaTest.
In this section of the Shadow DOM in Selenium tutorial, we will look at how to get started with finding Shadow DOM in Selenium WebDriver.
Demo: Finding Shadow DOM Using The getShadowRoot Method
As discussed earlier, this project on Shadow DOM in Selenium has been created using Maven. TestNG is used as a test runner. To learn more about Maven, you can go through this blog on getting started with Maven for Selenium testing.
Once the project is created, we need to add the dependency for Selenium WebDriver and TestNG in the pom.xml file.
Versions of the dependencies are set in a separate properties block. This is done for maintainability, so if we need to update the versions, we can do it easily without searching the dependency throughout the pom.xml file.

Let’s move on to the code now. The Page Object Model (POM) has been used in this project as it helps reduce code duplication and improve test case maintenance.
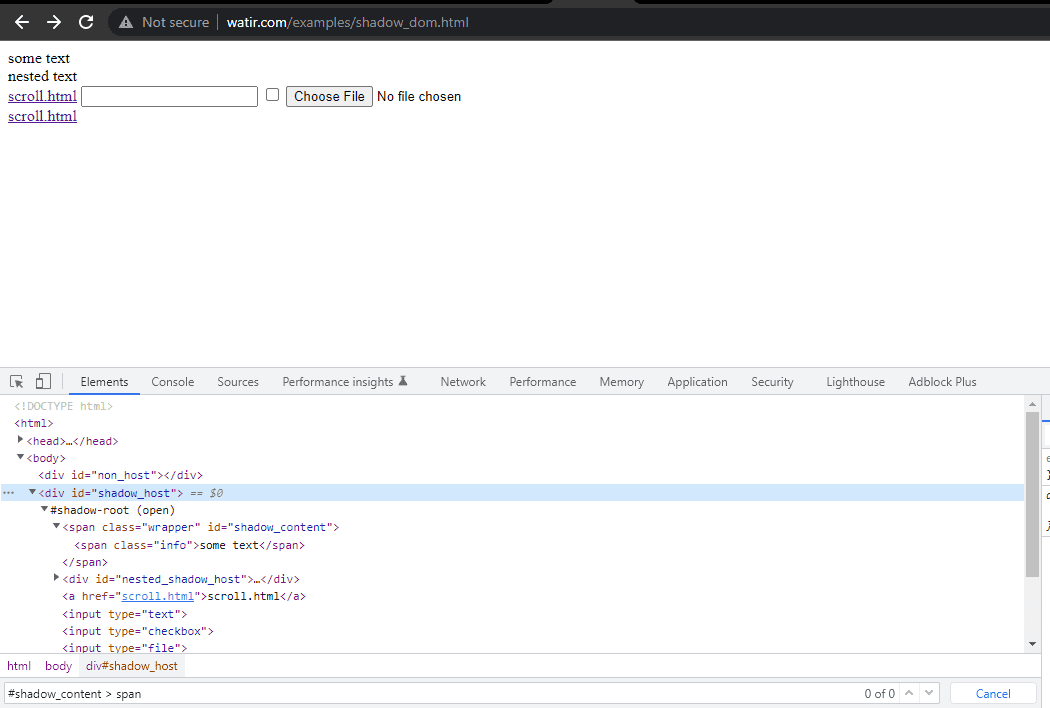
First, we would find the locator for “some text” and “nested text” on HomePage.
Code Walkthrough
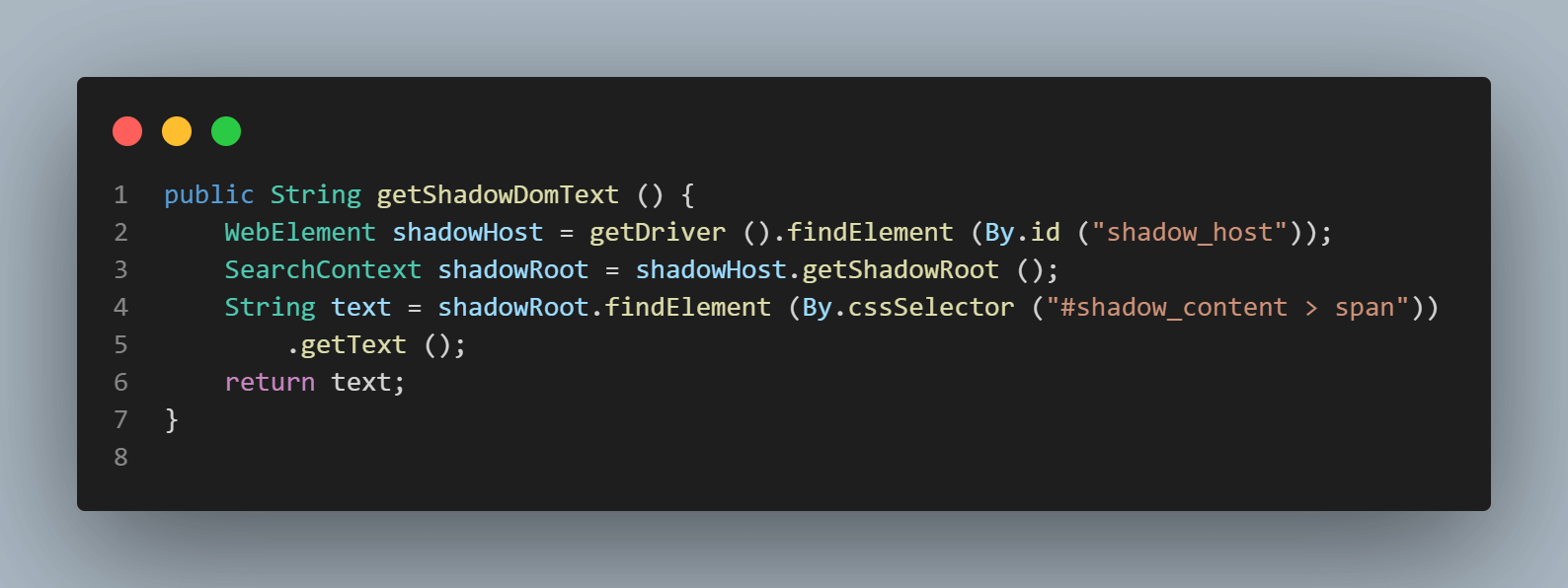
The first element we would be locating is the < div id = "shadow_host" > using locator strategy – id.
|
1 |
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host")); |
Next, we search for the first Shadow Root in the DOM next to it. For this, we have used the SearchContext interface. The Shadow Root is returned using the getShadowRoot() method. If you check in the screenshot above, #shadow-root (open) is next to the < div id = "shadow_host" >
For locating the text – “some text” there is only one Shadow DOM element we need to get through.
The following line of code helps us get the Shadow Root element.
|
1 |
SearchContext shadowRoot = downloadsManager.getShadowRoot(); |
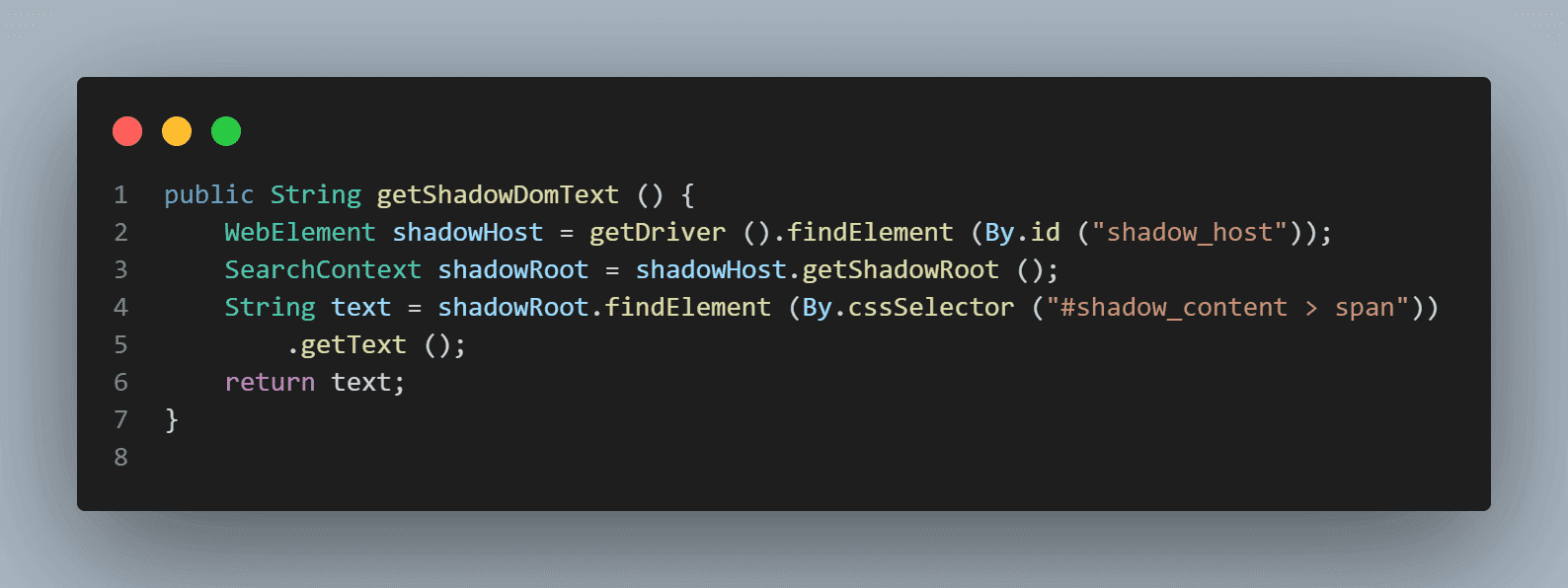
Once Shadow Root is found, we can search for the element to locate the text – “some text”. The following line of code helps us get the text:
|
1 2 |
String text = shadowRoot.findElement (By.cssSelector ("#shadow_content > span")) .getText (); |
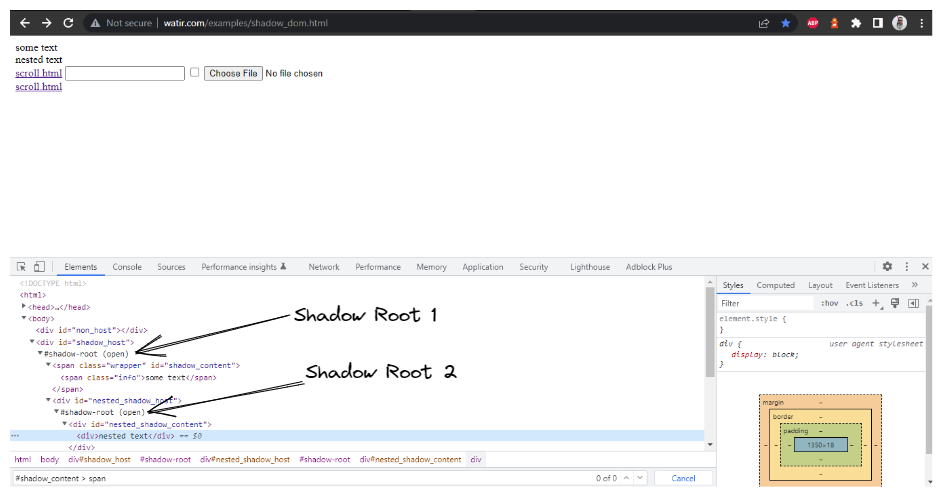
Next, let’s find the locator of “nested text” which has a nested Shadow Root element, and find out how to locate its element.
Starting from the top, as discussed in the above section, we need to locate
|
1 |
<div id = "shadow_host"> |
by using locator strategy – id.
|
1 |
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host")); |
After that, we need to find the Shadow Root element by using the getShadowRoot() method, once we get the Shadow Root element, we will need to get into finding the second Shadow Root by using cssSelector for locating:
|
1 |
<div id ="nested_shadow_host"> |
|
1 2 |
SearchContext shadowRoot = shadowHost.getShadowRoot (); WebElement shadowContent = shadowRoot.findElement (By.cssSelector ("#nested_shadow_host")); |
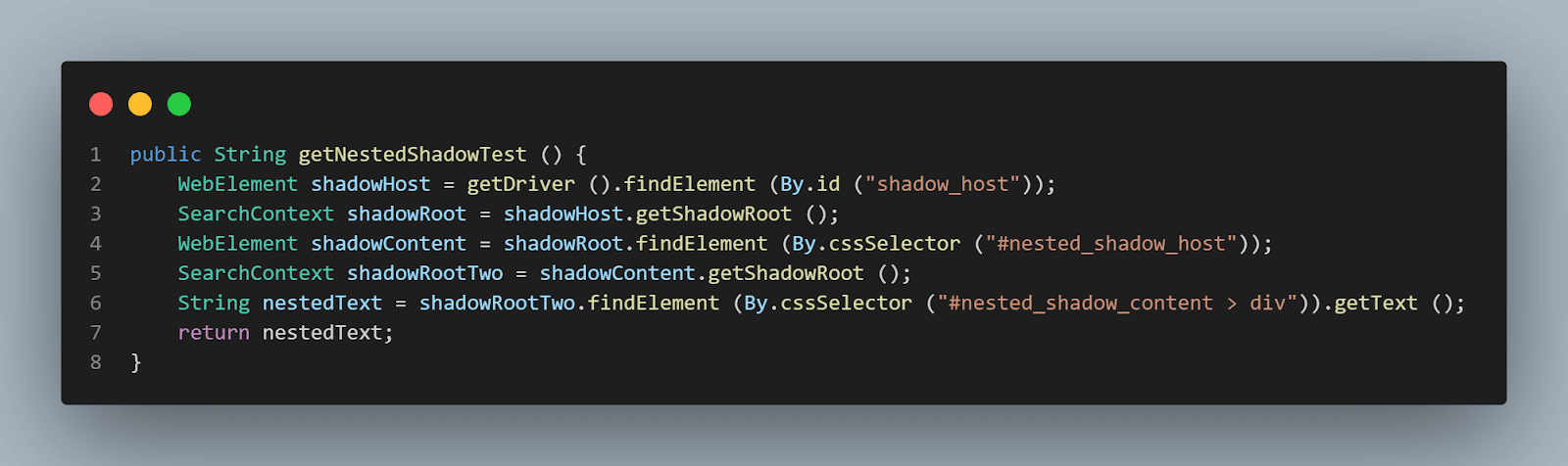
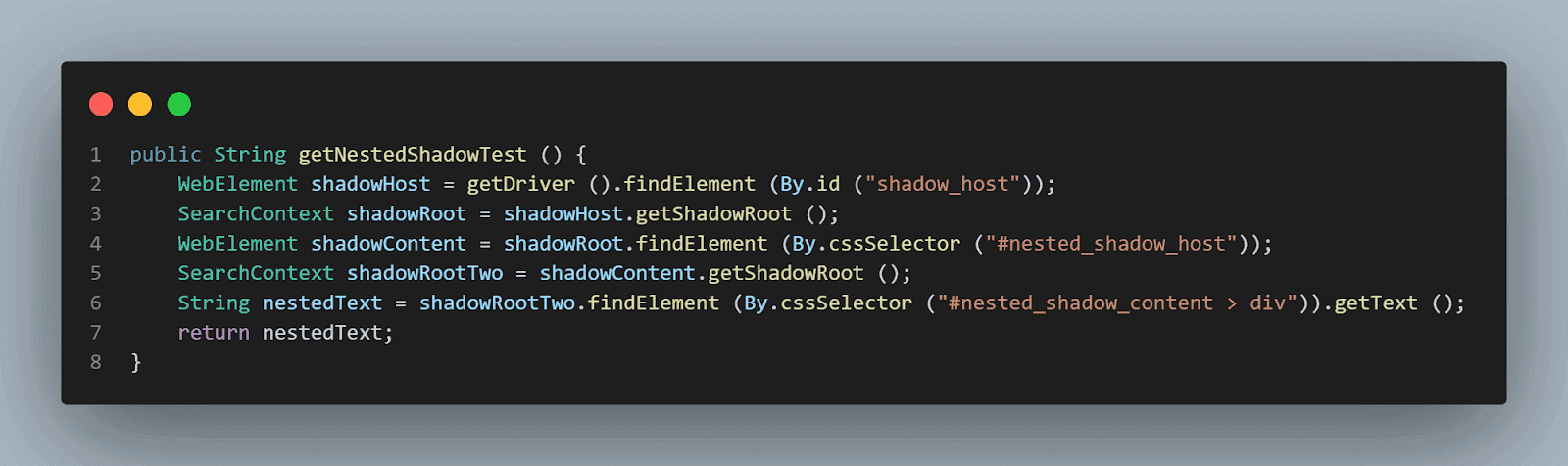
Next, we need to find the second Shadow Root element by using the getShadowRoot() method. Finally, it is time to locate the actual element for getting the text – “nested text”.
The following line of code will help us locate text:
|
1 2 |
SearchContext shadowRootTwo = shadowContent.getShadowRoot (); String nestedText = shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")).getText (); |
Writing the code in a fluent way
In the above section of this blog on Shadow DOM in Selenium, we saw a long way from where we have to locate the actual element we want to work with. We have to do multiple initializations of WebElement and SearchContext interfaces and write multiple lines of code to locate a single element to work with.
We have a fluent way of writing this whole code as well. Here is how you can do that:
|
1 2 3 4 5 6 7 8 |
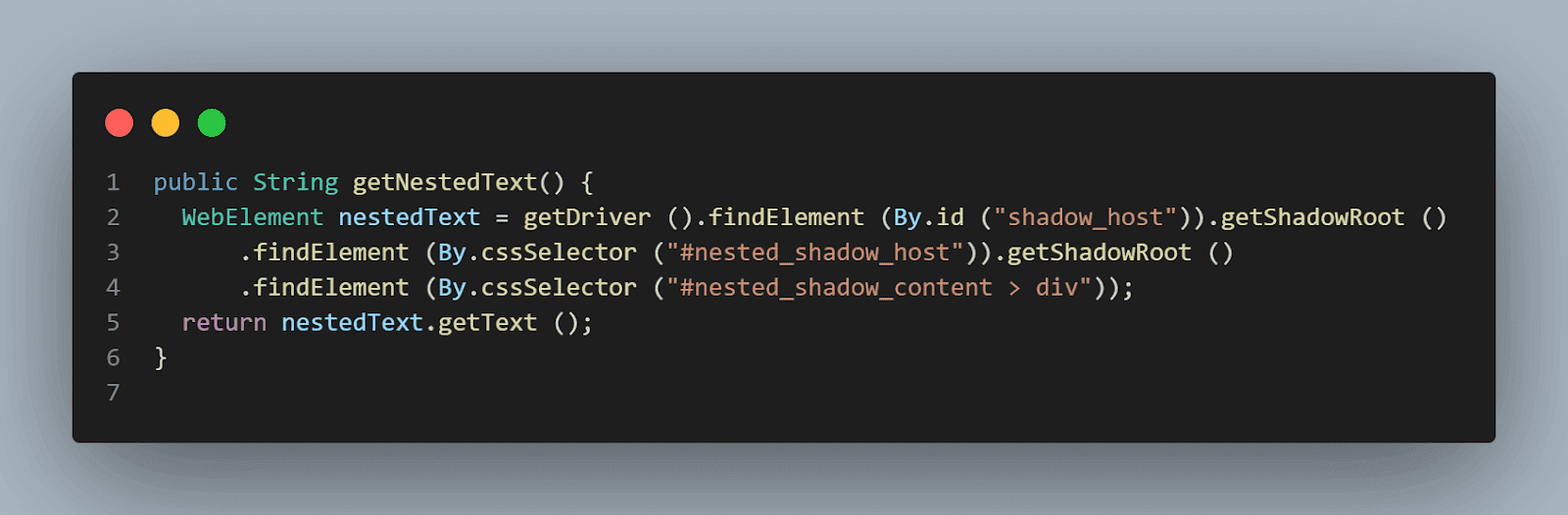
public String getNestedText() { WebElement nestedText = getDriver ().findElement (By.id ("shadow_host")) .getShadowRoot () .findElement (By.cssSelector ("#nested_shadow_host")) .getShadowRoot () .findElement (By.cssSelector ("#nested_shadow_content > div")); return nestedText.getText (); } |
Fluent Interface’s design relies extensively on method chaining. A Fluent Interface pattern helps us write an easy-readable code that can be understood without putting effort into technically understanding the code. This term was coined first in 2005 by Eric Evans and Martin Fowler.
This is a method of chaining we would be performing to locate the element.
This code does the same thing as we did in the above steps.
- First, we would locate the shadow_host element using its id, after which we would get the Shadow Root element using the getShadowRoot() method.
- Next, We would search for the nested_shadow_host element using the cssSelector and get the Shadow Root element using the getShadowRoot() method.
- Finally, we would get the “nested text” text using the cssSelector – nested_shadow_content > div.
Another example is the LambdaTest Selenium Playground website, which has a demo page with the Shadow DOM elements.
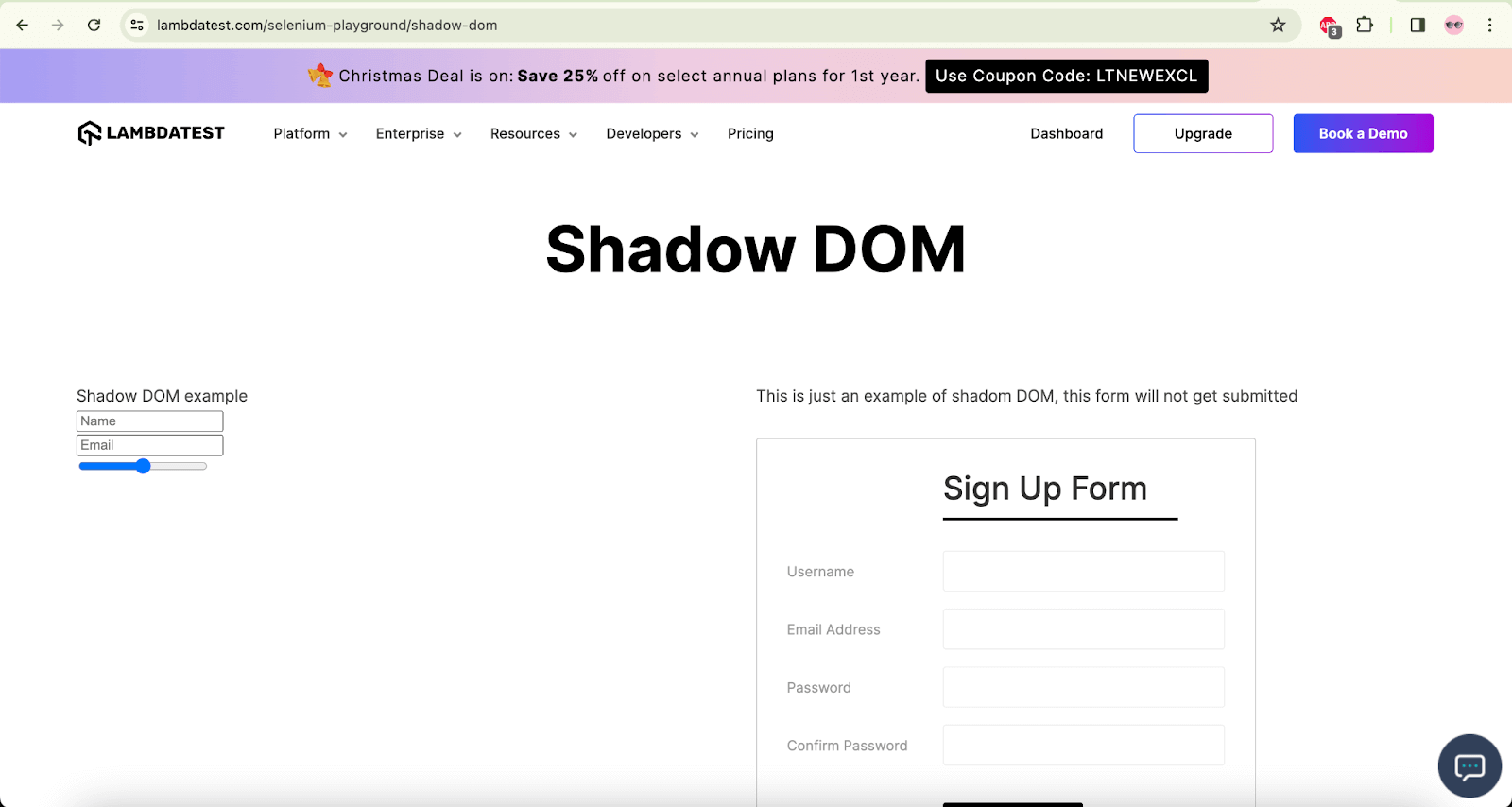
In this window, we will be locating the Name and Email fields that are located inside the Shadow Root.
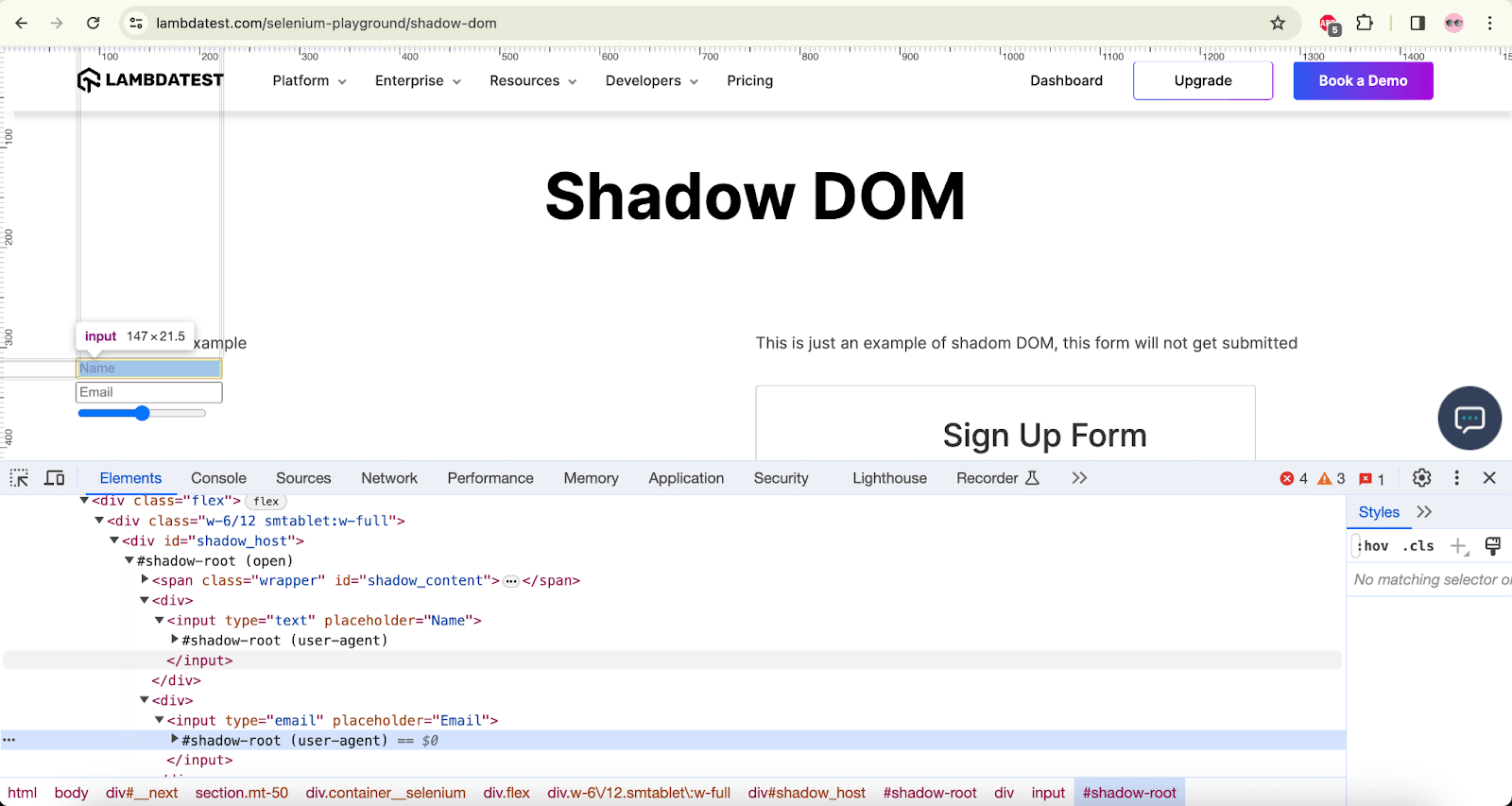
The following code created inside the ShadowDomPage class, available in the seleniumplayground package within the test folder, will help us locate the shadow host, which we will eventually use to locate the Name and Email fields.

The getShadowHost() method mentioned in the above code snippet will locate the shadow host.
Next, let’s locate and find the Name and the Email fields. Once the shadow host is located, it is pretty much easy to locate the Name and Email fields that are located within the Shadow Root.
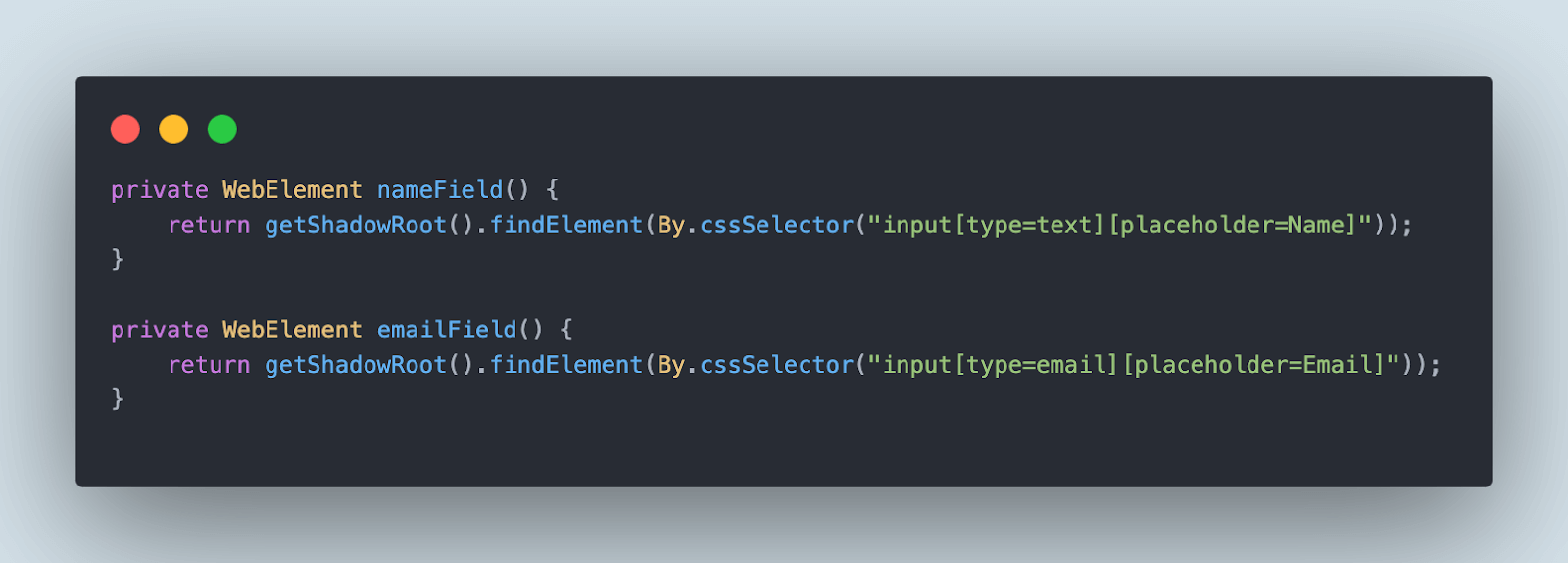
The nameField() and the emailField() methods will locate the name and the email fields, respectively, using the getShadowRoot() method
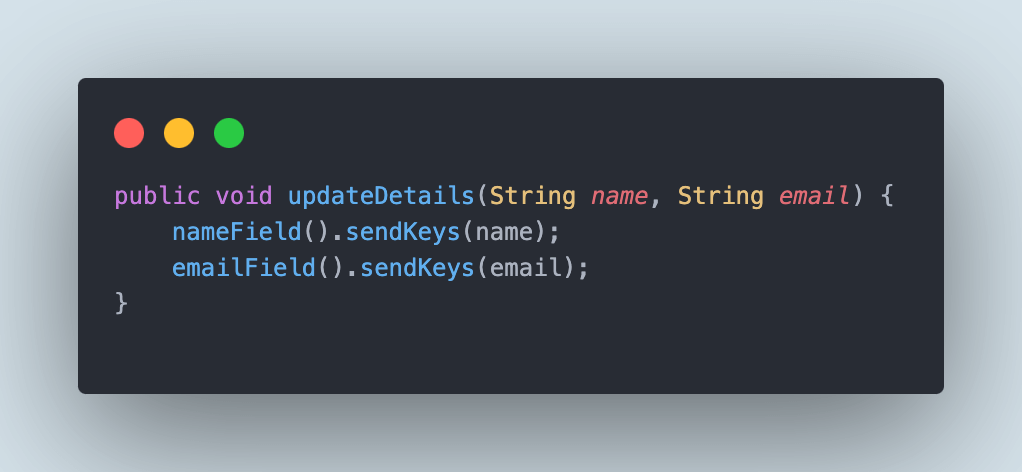
After these fields are located, we can use these fields in the updateDetails() method to actually pass on the values in the field.
Finally, we will make use of the getNameText() and getEmailText() methods, as shown in the below screenshot.
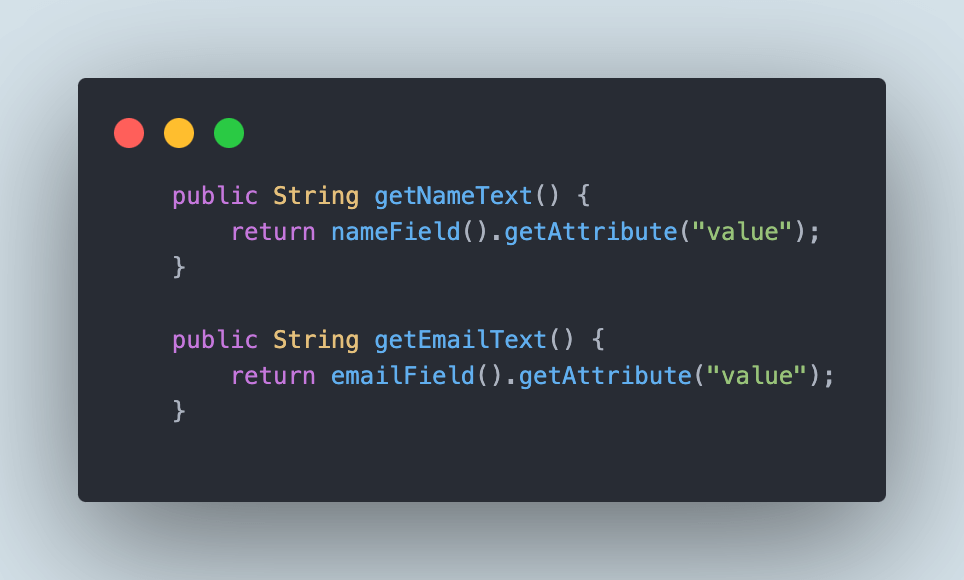
These methods will return the values that we will be entering in the Name and Email fields, respectively, so we can perform assertions and check that the value we supplied is actually passed in the field correctly.
How to Find Shadow DOM Using JavaScriptExecutor?
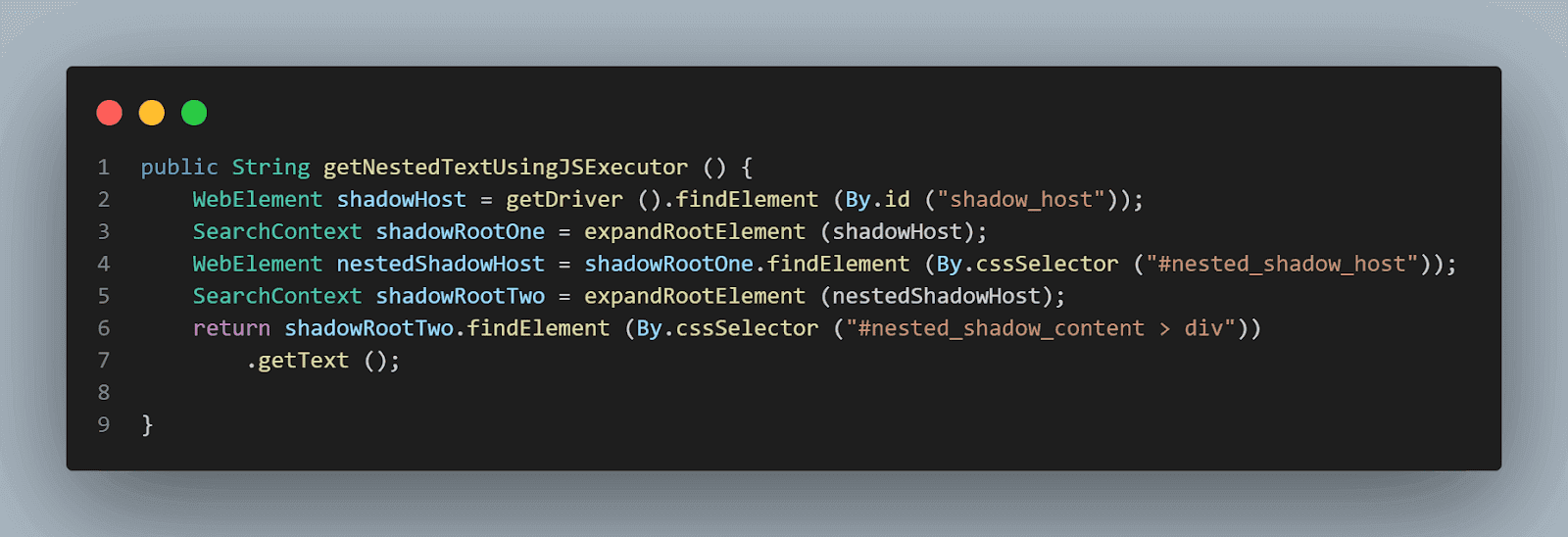
In the above code examples of this Shadow DOM in the Selenium tutorial, we located elements using the getShadowRoot() method. Let’s now see how to locate the Shadow Root elements using JavaScriptExecutor in Selenium WebDriver.
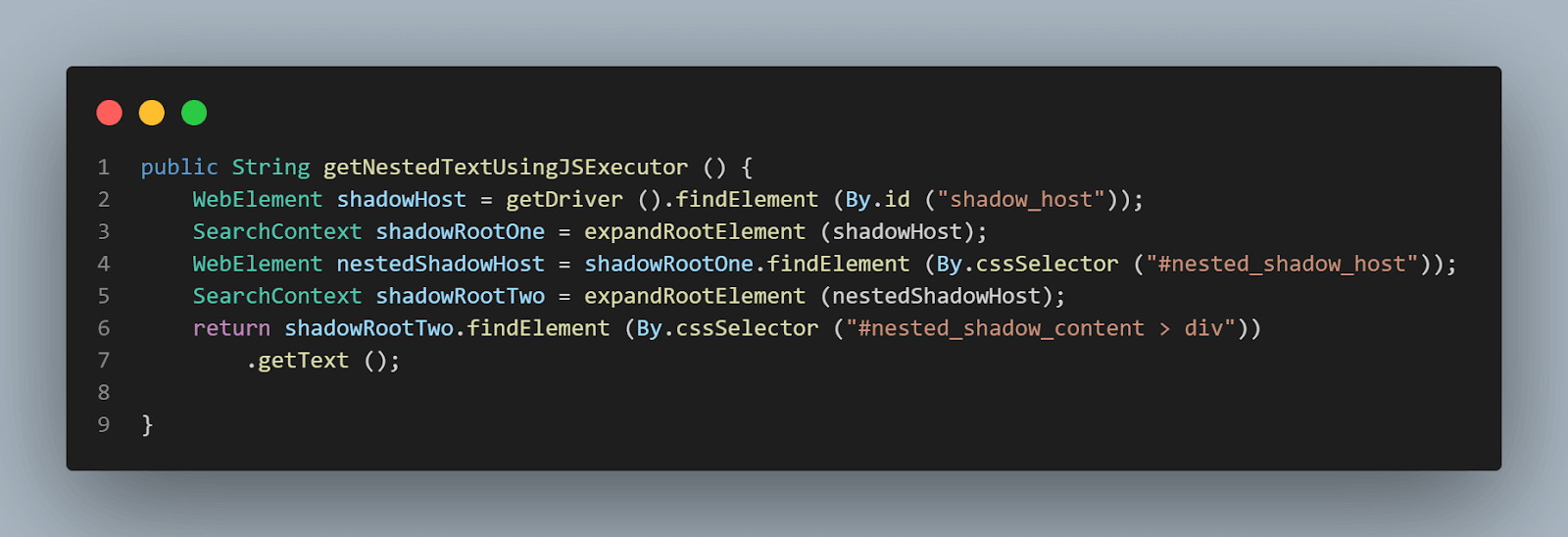
getNestedTextUsingJSExecutor() method has been created inside the HomePage Class, where we would be expanding the Shadow Root element based on the WebElement, we pass in the parameter.
Since in the DOM (as shown in the screenshot above), we saw that there are two Shadow Root elements we need to expand before we get to the actual locator for getting the text – nested text. Hence, the expandRootElement() method is created instead of copy-pasting the same JavaScriptExecutor code every time.
We would implement the SearchContext interface to help us with the JavaScriptExecutor and return the Shadow Root element based on the WebElement we pass in the parameter.
|
1 2 3 4 5 |
public SearchContext expandRootElement (WebElement element) { SearchContext shadowRoot = (SearchContext) ((JavascriptExecutor) getDriver ()).executeScript ( "return arguments[0].shadowRoot", element); return shadowRoot; } |
The first element that we would be locating is the < div id = "shadow_host" > by using locator strategy – id
Next, we would expand the Root Element based on the shadow_host WebElement we searched for.
|
1 2 |
WebElement shadowHost = getDriver ().findElement (By.id ("shadow_host")); SearchContext shadowRootOne = expandRootElement (shadowHost); |
After expanding the Shadow Root one, we can search for another WebElement using cssSelector for locating:
|
1 |
<div id ="nested_shadow_host"> |
|
1 2 |
WebElement nestedShadowHost = shadowRootOne.findElement (By.cssSelector ("#nested_shadow_host")); SearchContext shadowRootTwo = expandRootElement (nestedShadowHost); |
Finally, it is time to locate the actual element for getting the text – “nested text”.
The following line of code will help us in locating text:
|
1 2 |
shadowRootTwo.findElement (By.cssSelector ("#nested_shadow_content > div")) .getText (); |
Demo: Finding Shadow DOM Using JavaScriptExecutor
In this section of Shadow DOM in Selenium tutorial, let’s quickly write a test and check that the locators we found in the previous steps are providing us with the required text, and we can run assertions on the code we wrote to verify what we are expecting from the code is working.
|
1 2 3 4 5 6 7 8 9 10 |
@Test public void testShadowDomWatir () { getDriver ().get ("http://watir.com/examples/shadow_dom.html"); HomePage homePage = new HomePage (); // assertEquals (homePage.getSomeText(), "some text"); assertEquals (homePage.getShadowDomText (), "some text"); assertEquals (homePage.getNestedShadowText (),"nested text"); assertEquals (homePage.getNestedText (), "nested text"); assertEquals (homePage.getNestedTextUsingJSExecutor (), "nested text"); } |
This is just a simple test to assert the texts are displayed as correctly as expected. We would be checking that using the assertEquals() assertion in TestNG.
In actual value, we would provide the method we just wrote to get the text from the page, and in the expected value, we would pass the text “some text” or “nested text” depending on the assertions we would be doing.
There are 4 assertEquals statements provided in the test.
- Checking the Shadow DOM element using the
getShadowRoot()method. - Checking the nested Shadow DOM element using the
getShadowRoot()method. - Checking the nested Shadow DOM element using the
getShadowRoot()method and writing fluently. - Checking the nested Shadow DOM element using JavaScriptExecutor.
Next, let’s discuss the tests we wrote for the Shadow DOM page on the LambdaTest Selenium Playground website.
The testShadowDomSeleniumPlayground() method will perform the check for verifying the Shadow DOM elements. This method is written in the ShadowDomTests class in the test folder.
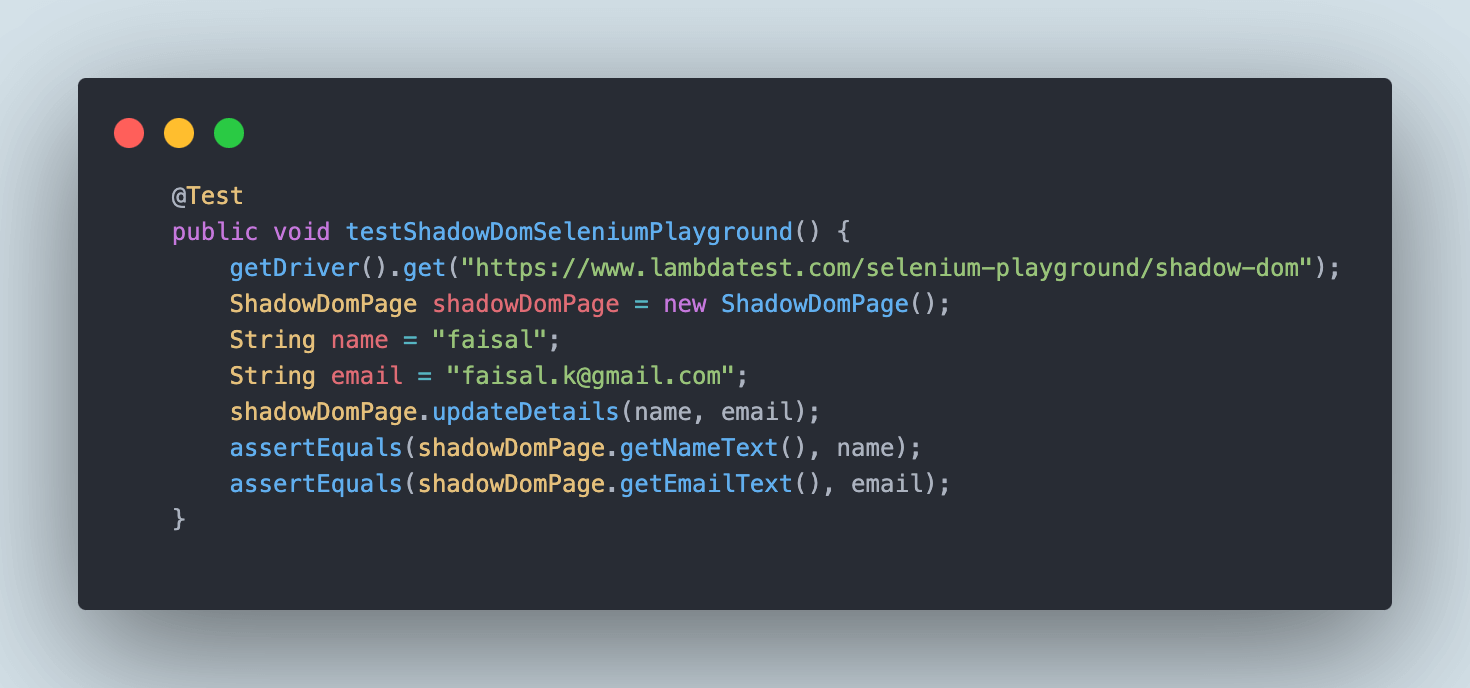
The testShadowDomSeleniumPlayground() will first navigate to the Shadow DOM page on LambdaTest’s Selenium Playground. Next, it will call the updateDetails(), which will locate the Shadow Root element, and next, using the getShadowRoot() method, it will locate the name and email fields and enter values in them.
Finally, the assertion methods will be called to check that the values entered in the field are correct.
Automating Shadow DOM in Selenium WebDriver
There are two ways to run the tests for automating Shadow DOM in Selenium:
- From the IDE using TestNG.
- From the CLI using Maven.
Automating Shadow DOM Using TestNG
TestNG is used as a test runner. Hence, testng.xml has been created, using which we will run the tests by right-clicking on the file and selecting the option Run ‘…\testng.xml’. This file will be placed inside the root folder of the project.
But before running the tests, we need to add the LambdaTest username and access Key in the Run Configurations since we are reading the username and access key from System Property.
LambdaTest is an AI-powered test orchestration and execution platform that offers an online Selenium grid of over 3000 real browsers and operating systems to help you automate Shadow DOM in Selenium on the cloud. You can accelerate your Selenium testing with Java and reduce test execution time by multiple folds by running parallel tests on multiple browsers and OS configurations.
Subscribe to the LambdaTest YouTube Channel and stay updated with the latest tutorials around automated testing, Playwright, and more.
Add values in the Run Configuration as mentioned below:
- Dusername =
< LambdaTest username > - DaccessKey =
< LambdaTest access key >
The LambdaTest Username and Access Key values can be taken from your Profile > Account Settings > Password and Security tab.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="Shadow DOM Automation Tests"> <test name="Shadow DOM Tests on Watir Website"> <parameter name="browser" value="remote-chrome"/> <classes> <class name="ShadowDomTests"> <methods> <include name="testShadowDomWatir"/> </methods> </class> </classes> </test> <!-- Test --> <test name="Shadow DOM Tests on Selenium Playground Website"> <parameter name="browser" value="remote-chrome"/> <classes> <class name="ShadowDomTests"> <methods> <include name="testShadowDomSeleniumPlayground"/> </methods> </class> </classes> </test> <!-- Test --> </suite> |
Here is the screenshot of the test run locally for Shadow DOM in Selenium using Intellij IDE.
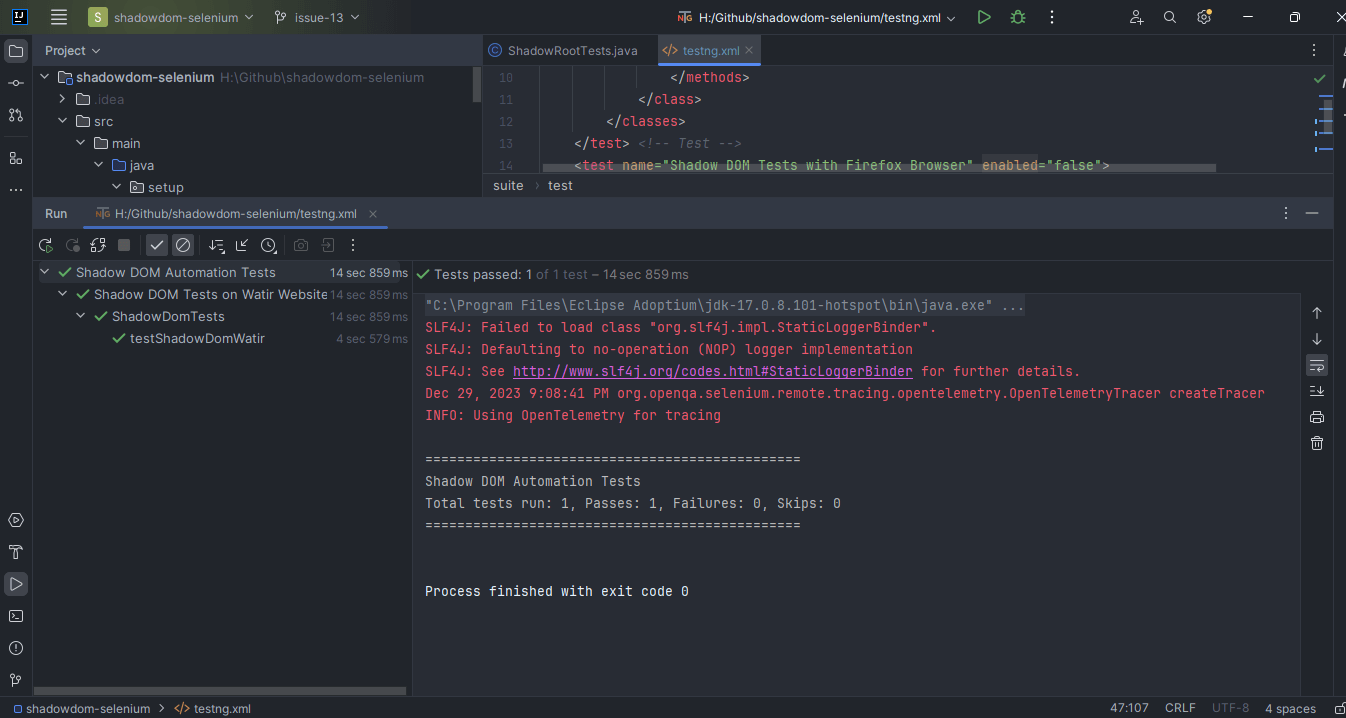
Automating Shadow DOM Using Maven
To run the tests using Maven, the following steps need to be run to automate Shadow DOM in Selenium:
- Open command Prompt/Terminal.
- Navigate to the root folder of the project.
- Type the command:
mvn clean install -Dusername=< LambdaTest username > -DaccessKey=< LambdaTest accessKey >.
Following is the screenshot from IntelliJ, which shows the execution status of the tests using Maven:
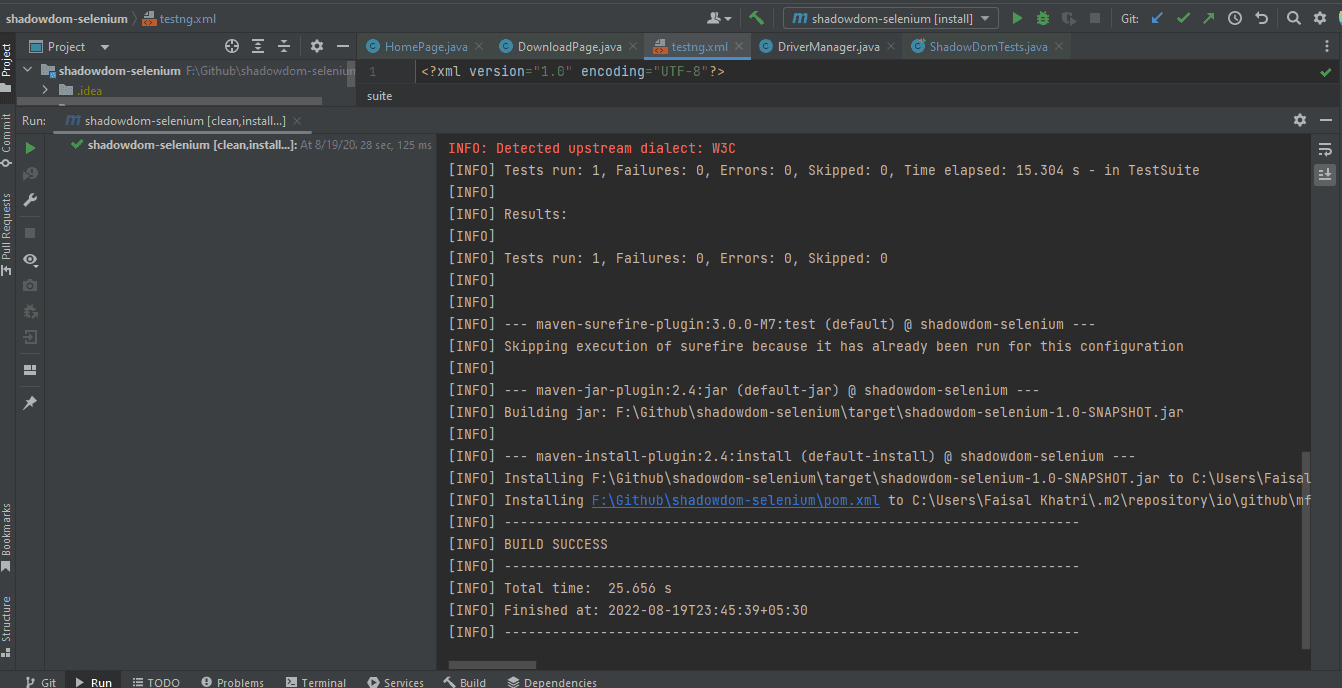
Once the tests are run successfully, we can go to the LambdaTest Web Automation Dashboard and view all the video recordings, screenshots, device logs, and step-by-step granular test run details.
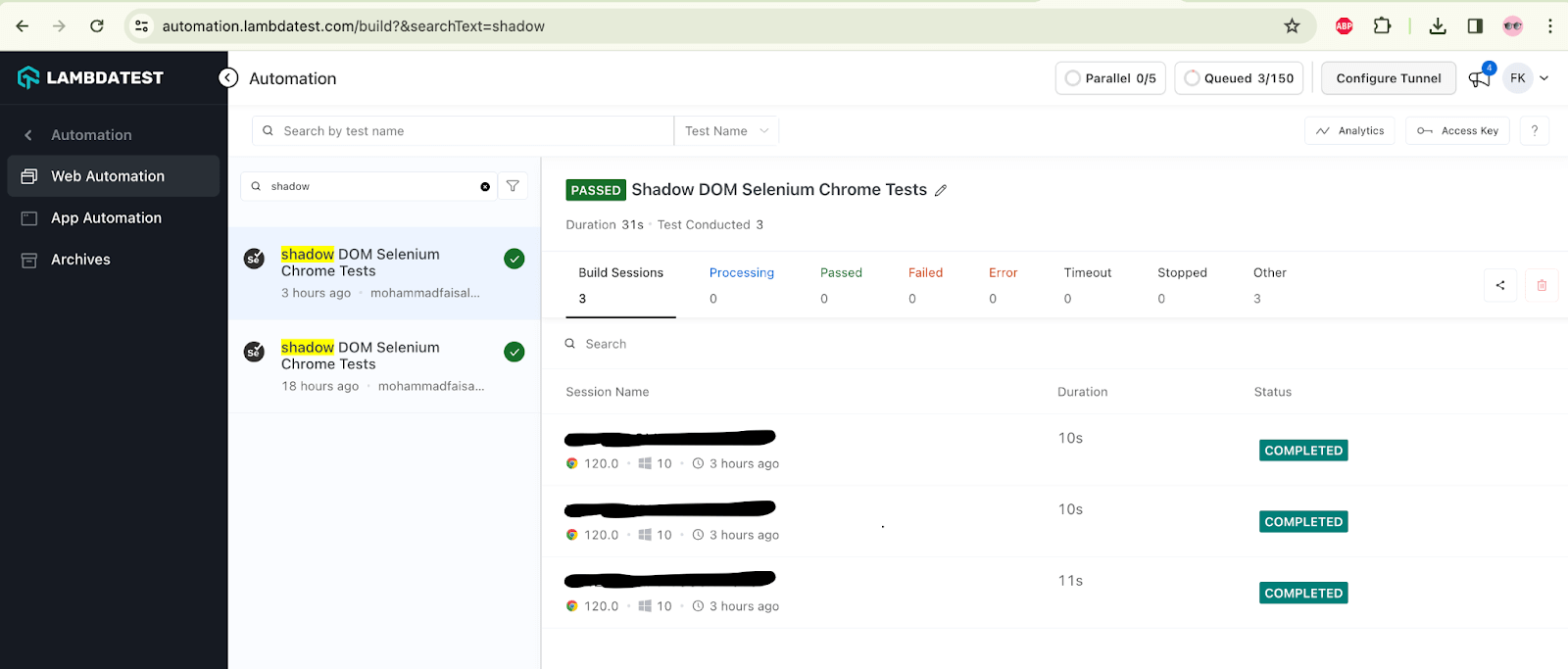
The following screenshot shows the build details and the tests run for automating Shadow DOM in Selenium. Again, the test name, browser name, browser version, OS name, respective OS version, and screen resolution are all correctly visible for each test.
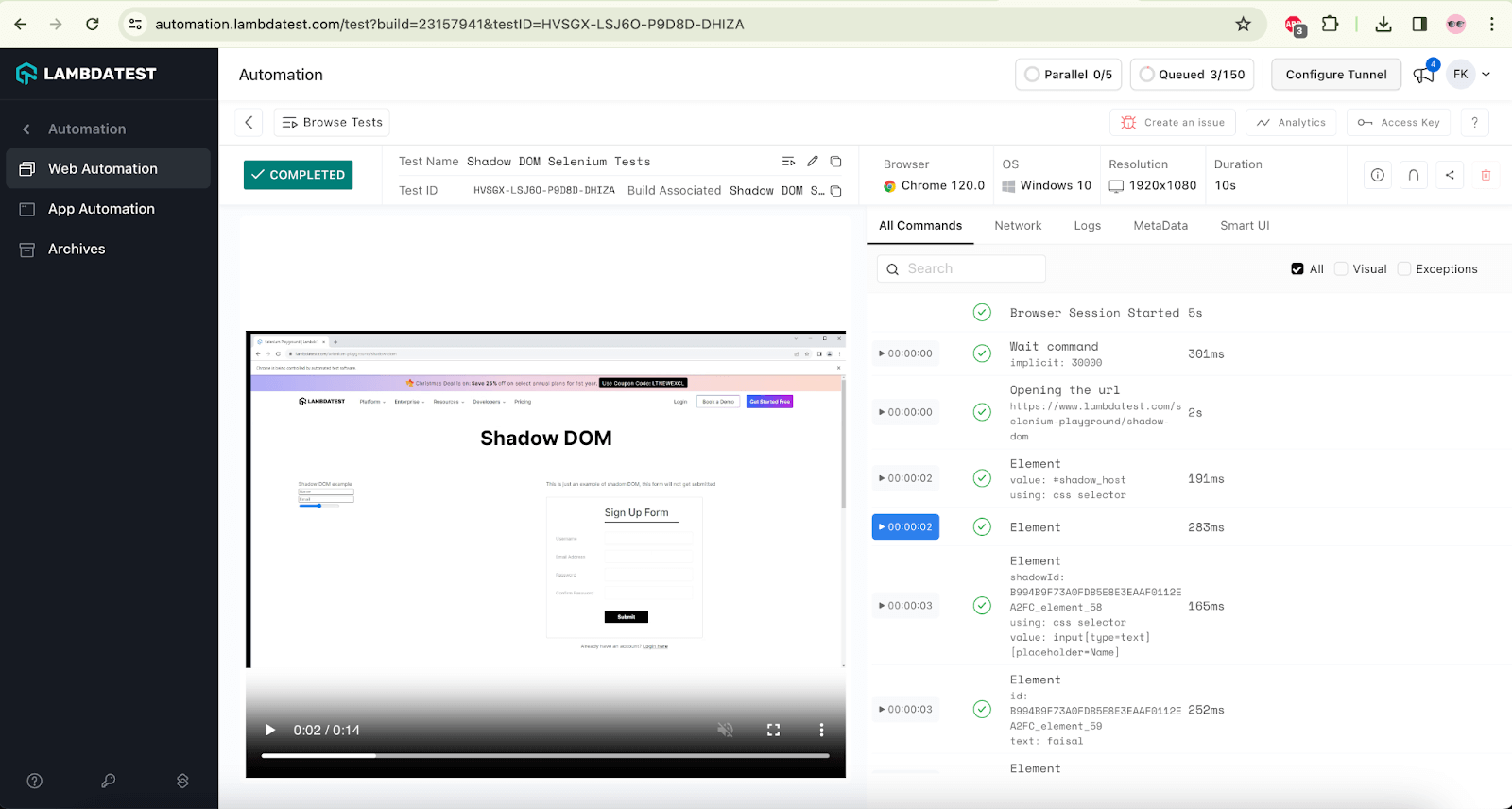
The screenshot below shows the Selenium logs that help testers check what test was run on which browser and accordingly view the logs for automating Shadow DOM in Selenium.
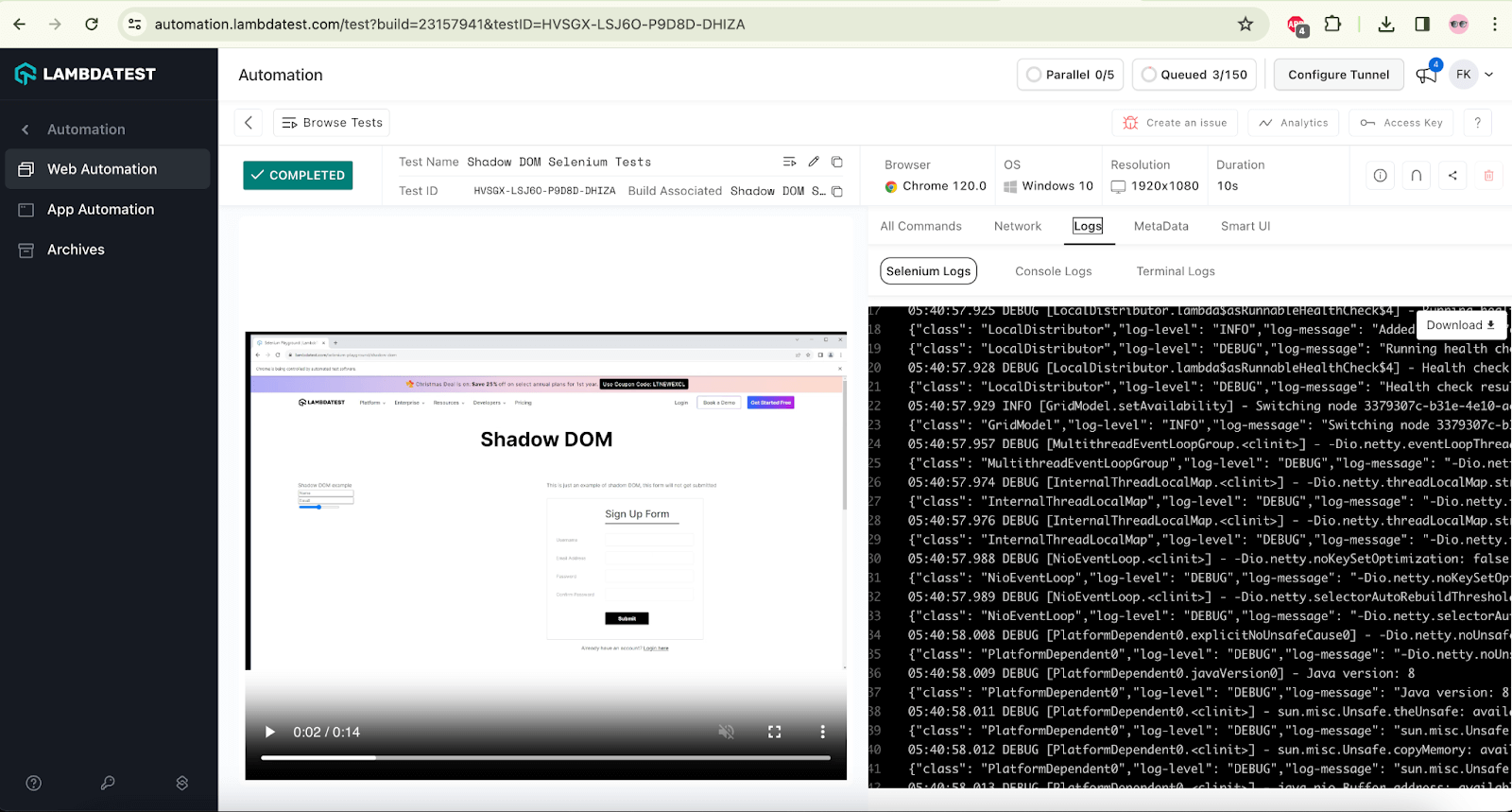
Once you have automated Shadow DOM in Selenium on LambdaTest, you can view the test execution results, such as their status and the overall number of tests passed or failed, in the LambdaTest Analytics Dashboard for deep testing insights. In addition, you can see screenshots of recently executed test runs in the Test Overview section.
If you’re a Selenium tester or developer, the LambdaTest Selenium Java 101 certification can help you advance your Selenium with Java skills.

In addition, you can also reach out to us on the LambdaTest Community in case you face any issues while running the tests on the LambdaTest platform. You can also request a feature or integrations per your testing requirements.
Conclusion
In this blog on automating Shadow DOM in Selenium, we discussed finding Shadow DOM elements and automating them using the getShadowRoot() method introduced in the Selenium WebDriver 4.0.0 and above version.
We also discussed locating and automating the Shadow DOM in Selenium WebDriver using JavaScriptExecutor and running the tests on the LambdaTest platform, which shows granular details of the tests run with Selenium WebDriver logs.
I hope this blog on Shadow DOM in Selenium gives you a fair idea about automating Shadow DOM using Selenium WebDriver.
Happy Testing!
Frequently Asked Questions (FAQs)
What is Shadow DOM, and how is it different from DOM?
Shadow DOM is a way to encapsulate the styles and JavaScript of an element tree within a document without affecting the rest of the page. It’s a way to create an isolated world that can’t be interfered with by other parts of the page. The Shadow DOM is different from the Document Object Model (DOM).
The DOM is the collection of elements in a document and their properties, like id, class, and style. You can think of a shadow DOM as something similar to a DOM, but inside it are hidden or encapsulated things that you can’t see unless you look closely.
How to write XPath for Shadow DOM?
XPath is often used to locate elements in HTML documents, but it has limitations when it comes to Shadow DOM. Shadow DOM encapsulates the internal structure of a component, making it challenging to access elements within the shadow tree using traditional XPath. However, some browsers support the ::shadow or ::deep pseudo-elements in XPath to navigate through the Shadow DOM.


Author’s Profile
Faisal Khatri
Faisal is a Software Testing Professional having 14+ years of experience in automation as well as manual testing. He is a QA, freelancer, blogger and open source contributor. He loves learning new tools and technologies and sharing his experience by writing blogs.
Blogs: 39
Got Questions? Drop them on LambdaTest Community. Visit now